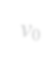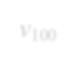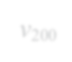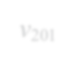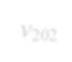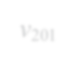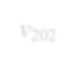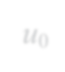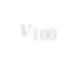Subgraph isomorphism is a well-known NP-hard problem which is widely used in many applications, such as social network analysis and knowledge graph query. Its performance is often limited by the inherent hardness. Several insightful works have been done since 2012, mainly optimizing pruning rules and matching orders to accelerate enumerating all isomorphic subgraphs. Nevertheless, their correctness and performance are not well studied. First, different languages are used in implementation with different compilation flags. Second, experiments are not done on the same platform and the same datasets. Third, some ideas of different works are even complementary. Last but not least, there exist errors when applying some algorithms. In this paper, we address these problems by re-implementing seven representative subgraph isomorphism algorithms as well as their improved versions, and conducting comprehensive experiments on various graphs. The results show pros and cons of state-of-the-art solutions and explore new approaches to optimization.
翻译:子系形态是一个众所周知的NP-硬问题,在许多应用程序中广泛使用,如社交网络分析和知识图形查询,其性能往往受到内在硬性的限制。自2012年以来,已经做了一些颇有见地的工作,主要是优化裁剪规则和匹配顺序,以加速罗列所有等形态子图。然而,没有很好地研究它们的正确性和性能。首先,不同语言用于不同的编译旗帜。第二,不同语言的运用在同一个平台和相同的数据集中并不使用。第三,不同作品的一些想法甚至互为补充。最后但并非最不重要的一点是,在应用某些算法时存在错误。在本文件中,我们通过重新实施七个具有代表性的子系形态算法及其改进版本来解决这些问题,并在各种图表上进行全面实验。结果显示了最新解决方案的利弊,并探索了新的优化方法。