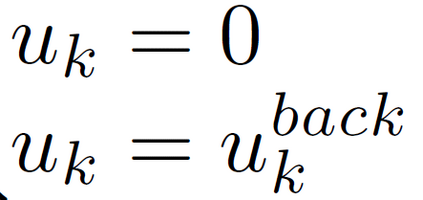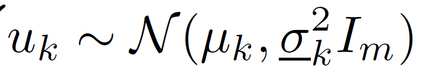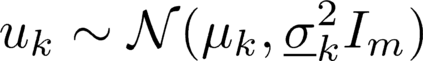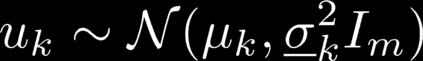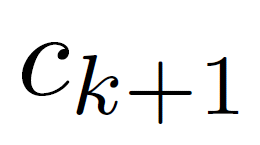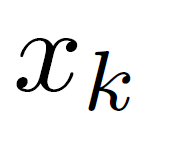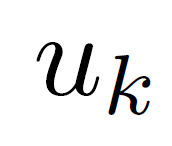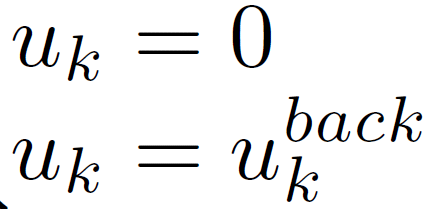In reinforcement learning (RL) algorithms, exploratory control inputs are used during learning to acquire knowledge for decision making and control, while the true dynamics of a controlled object is unknown. However, this exploring property sometimes causes undesired situations by violating constraints regarding the state of the controlled object. In this paper, we propose an automatic exploration process adjustment method for safe RL in continuous state and action spaces utilizing a linear nominal model of the controlled object. Specifically, our proposed method automatically selects whether the exploratory input is used or not at each time depending on the state and its predicted value as well as adjusts the variance-covariance matrix used in the Gaussian policy for exploration. We also show that our exploration process adjustment method theoretically guarantees the satisfaction of the constraints with the pre-specified probability, that is, the satisfaction of a joint chance constraint at every time. Finally, we illustrate the validity and the effectiveness of our method through numerical simulation.
翻译:在强化学习(RL)算法中,探索控制投入用于学习获取决策和控制的知识,而受控物体的真实动态却未知。然而,这种探索财产有时会违反受控物体状态的限制,造成不理想的情况。在本文中,我们提议在连续状态和动作空间中,利用受控物体的线性名义模型,对安全RL采用自动勘探过程调整方法。具体地说,我们提议的方法根据状态及其预测值,自动选择探索输入是否每次使用,并调整高斯勘探政策中使用的差异变量矩阵。我们还表明,我们的勘探过程调整方法理论上保证了对预定概率的满足,即每次联合机会限制的满足。最后,我们通过数字模拟来说明我们方法的有效性和有效性。