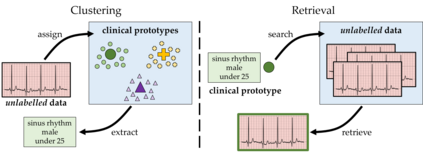
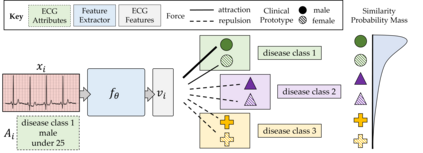
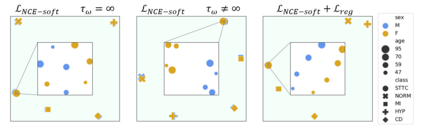
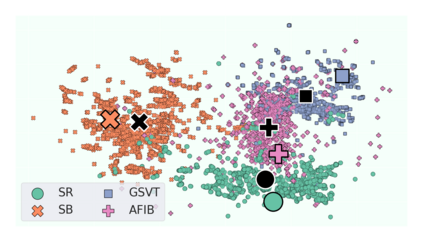
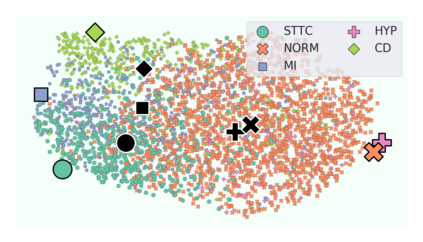
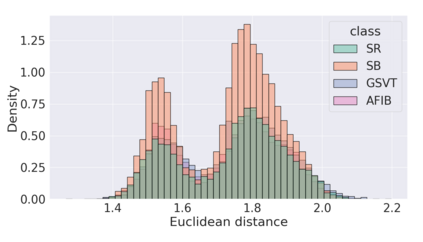
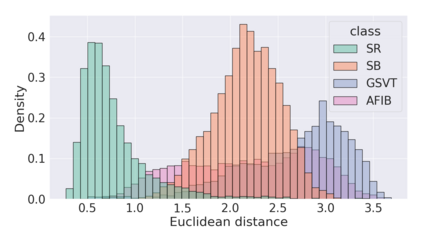
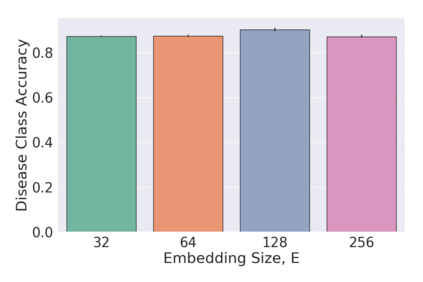
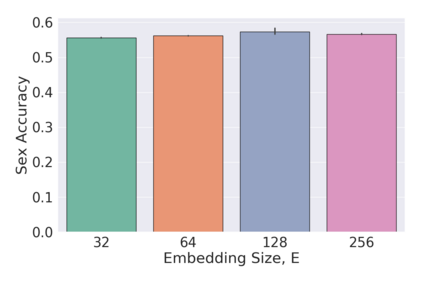
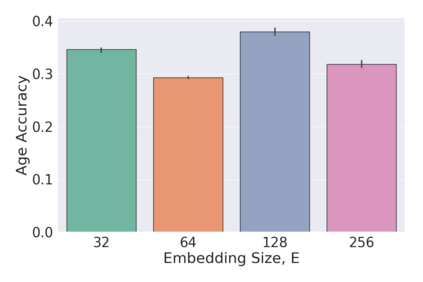
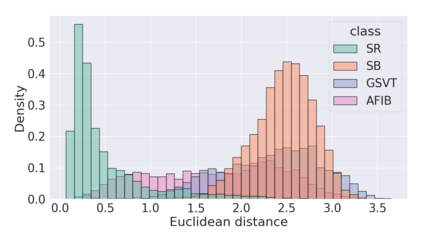
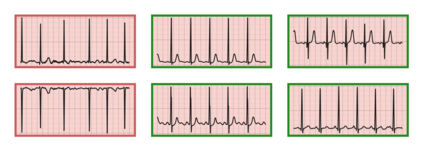
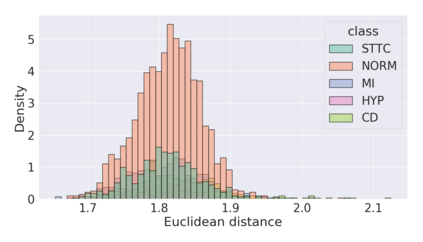
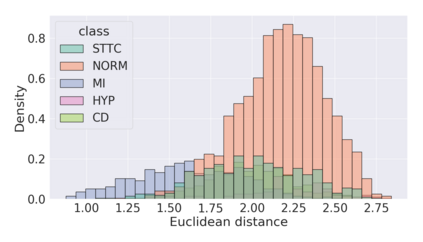
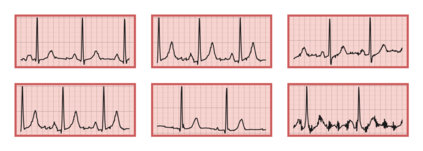
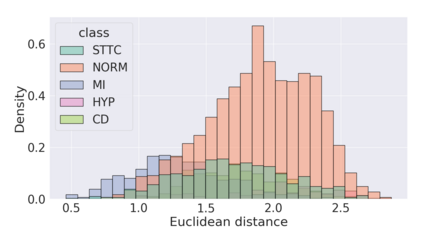
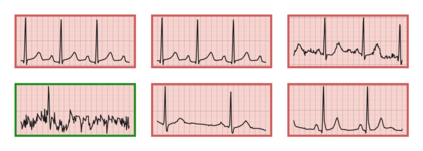
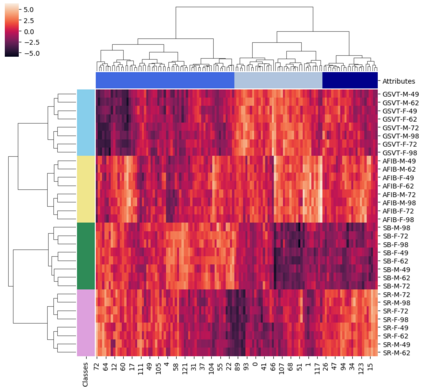
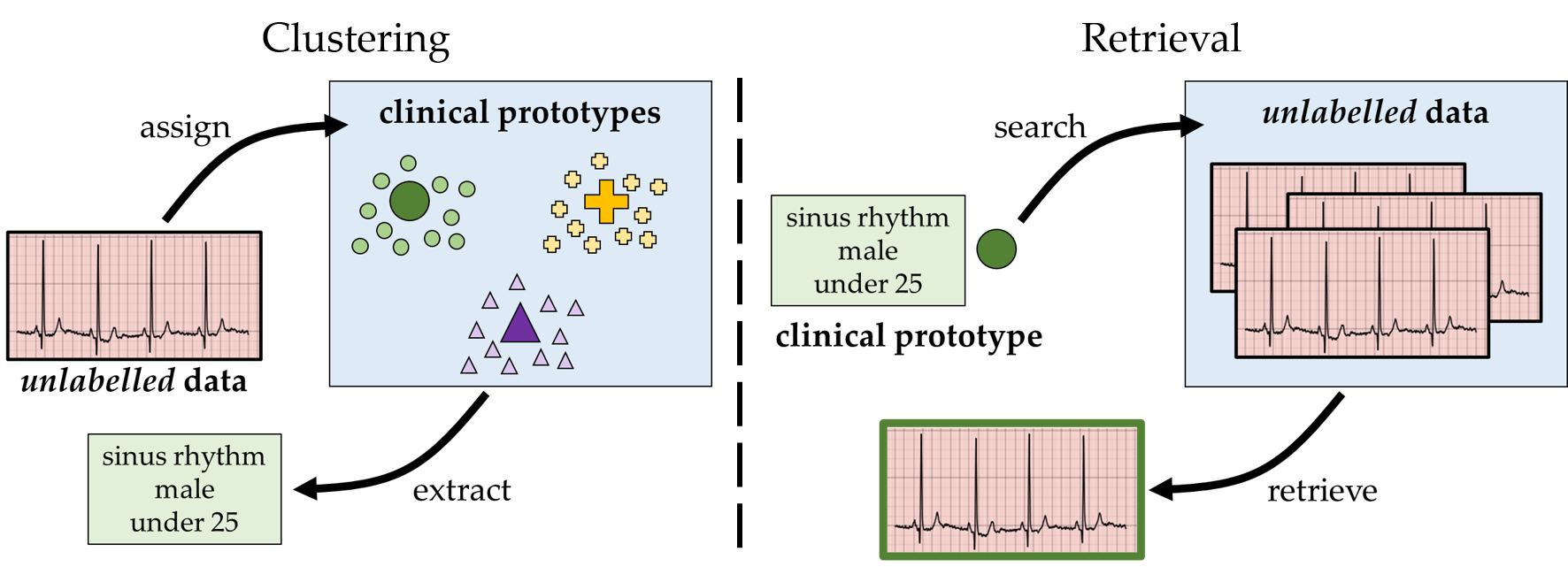
The process of manually searching for relevant instances in, and extracting information from, clinical databases underpin a multitude of clinical tasks. Such tasks include disease diagnosis, clinical trial recruitment, and continuing medical education. This manual search-and-extract process, however, has been hampered by the growth of large-scale clinical databases and the increased prevalence of unlabelled instances. To address this challenge, we propose a supervised contrastive learning framework, CROCS, where representations of cardiac signals associated with a set of patient-specific attributes (e.g., disease class, sex, age) are attracted to learnable embeddings entitled clinical prototypes. We exploit such prototypes for both the clustering and retrieval of unlabelled cardiac signals based on multiple patient attributes. We show that CROCS outperforms the state-of-the-art method, DTC, when clustering and also retrieves relevant cardiac signals from a large database. We also show that clinical prototypes adopt a semantically meaningful arrangement based on patient attributes and thus confer a high degree of interpretability.
翻译:临床数据库中相关案例的人工搜索过程和从临床数据库中提取信息是许多临床任务的基础,这些任务包括疾病诊断、临床试验招聘和继续医学教育。但是,由于大规模临床数据库的扩大和未贴标签案例的日益普遍,这一人工搜索和提取过程受到阻碍。为了应对这一挑战,我们提议了一个监督的对比学习框架,即CROCS,在这个框架中,与一套特定病人特征(如疾病等级、性别、年龄)相关的心脏信号的表示被吸引到可学习的临床原型嵌入中。我们利用这些原型来对基于多个病人属性的未贴标签的心脏信号进行分组和检索。我们表明,CROCS在集群和从一个大型数据库检索相关的心脏信号时,超过了最先进的方法,即DTC。我们还表明,临床原型采用了基于病人属性的具有生命意义的安排,因此具有很高程度的可解释性。