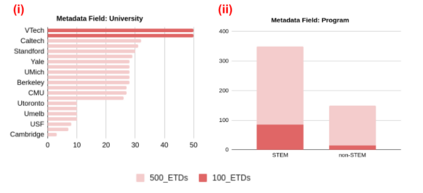
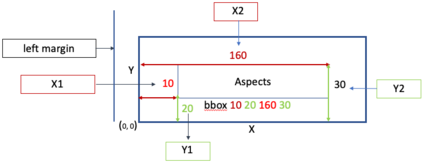
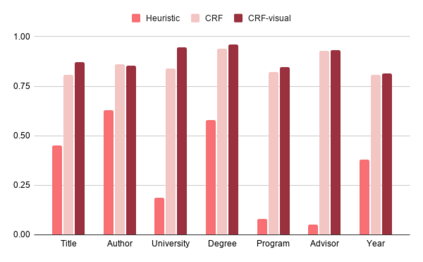
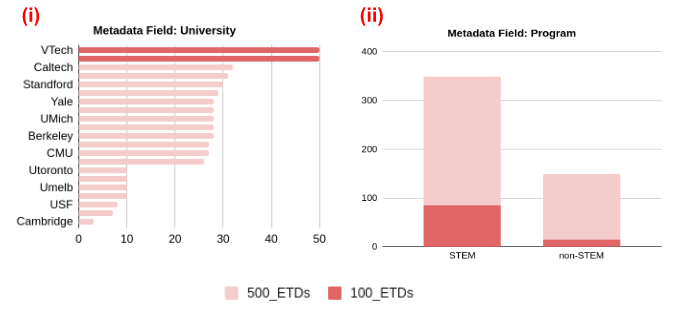
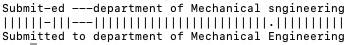Electronic Theses and Dissertations (ETDs) contain domain knowledge that can be used for many digital library tasks, such as analyzing citation networks and predicting research trends. Automatic metadata extraction is important to build scalable digital library search engines. Most existing methods are designed for born-digital documents, so they often fail to extract metadata from scanned documents such as for ETDs. Traditional sequence tagging methods mainly rely on text-based features. In this paper, we propose a conditional random field (CRF) model that combines text-based and visual features. To verify the robustness of our model, we extended an existing corpus and created a new ground truth corpus consisting of 500 ETD cover pages with human validated metadata. Our experiments show that CRF with visual features outperformed both a heuristic and a CRF model with only text-based features. The proposed model achieved 81.3%-96% F1 measure on seven metadata fields. The data and source code are publicly available on Google Drive (https://tinyurl.com/y8kxzwrp) and a GitHub repository (https://github.com/lamps-lab/ETDMiner/tree/master/etd_crf), respectively.
翻译:电子论文和文章(ETDs)包含可用于许多数字图书馆任务的域知识,如分析引用网络和预测研究趋势等。自动元数据提取对于建立可缩放的数字图书馆搜索引擎十分重要。大多数现有方法都是为天生数字文件设计的,因此它们往往无法从扫描文档中提取元数据,如ETDs。传统序列标记方法主要依靠基于文本的特征。在本文件中,我们提议一个有条件随机域模型,将文本和视觉特征结合起来。为了核实模型的稳健性,我们扩展了现有实体并创建了由500个ETD封面页和人类验证元数据组成的新的地面真相资料库。我们的实验显示,具有视觉特征的通用报告格式优于以文本为基础的模式。拟议的模型在七个元领域实现了81.3%-96%的F1措施。数据和源代码在谷歌驱动器(https://tinyurl.com/y8kzrwrp)和GitHub仓库(https://grustral_Erome.com/lam-slam-rwrum)上公开提供(httpsmaxxwn)。