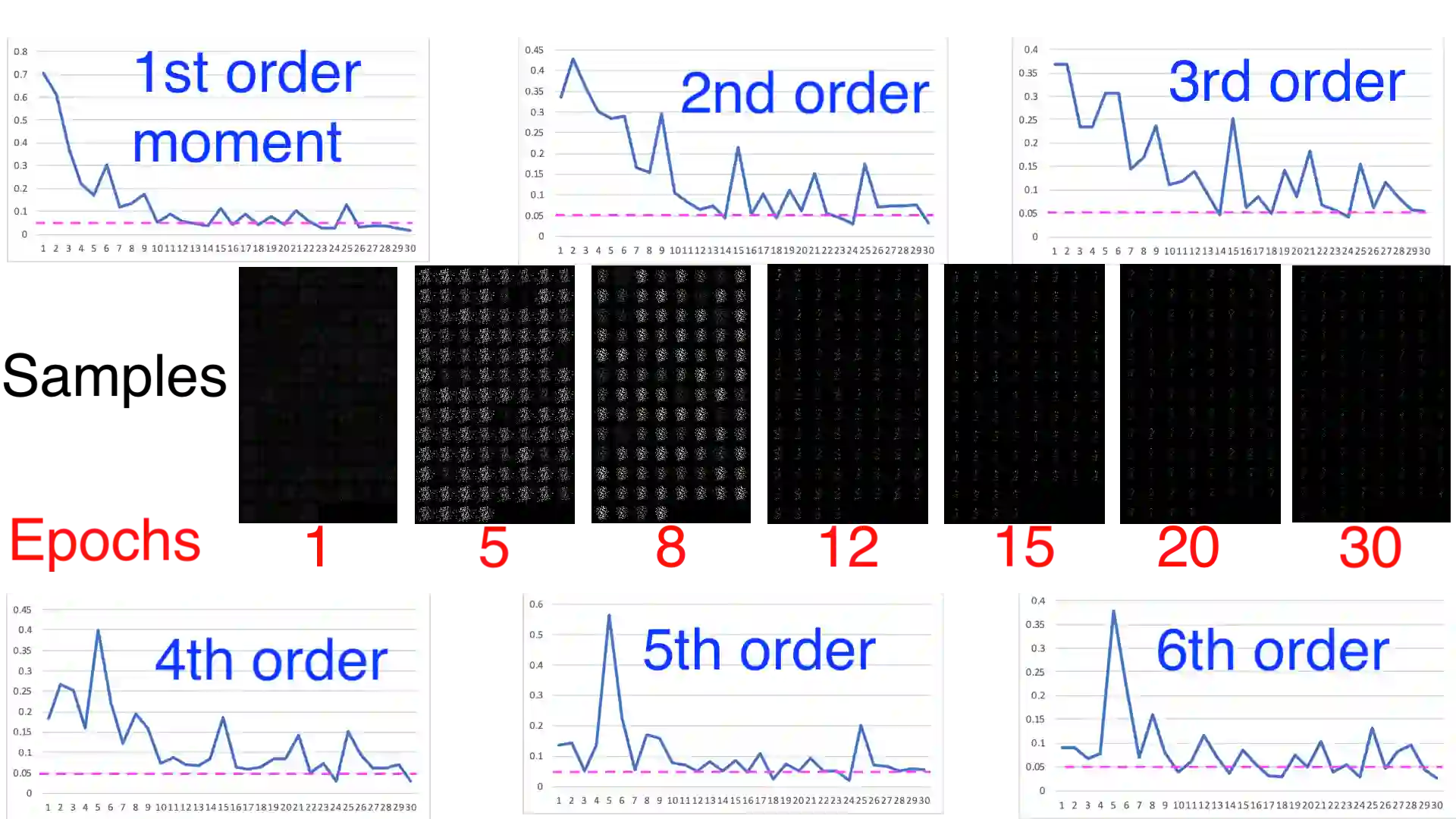
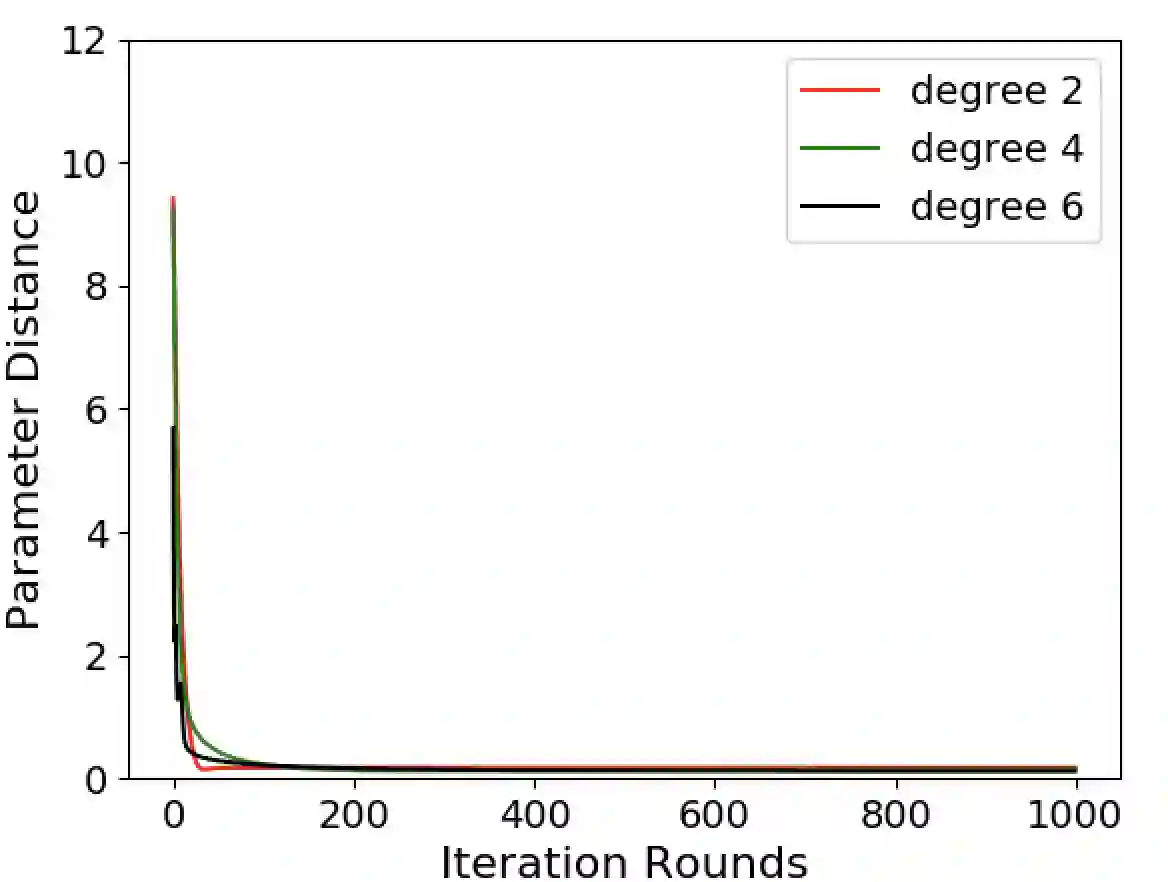
Generative Adversarial Networks (GANs) are widely used models to learn complex real-world distributions. In GANs, the training of the generator usually stops when the discriminator can no longer distinguish the generator's output from the set of training examples. A central question of GANs is that when the training stops, whether the generated distribution is actually close to the target distribution, and how the training process reaches to such configurations efficiently? In this paper, we established a theoretical results towards understanding this generator-discriminator training process. We empirically observe that during the earlier stage of the GANs training, the discriminator is trying to force the generator to match the low degree moments between the generator's output and the target distribution. Moreover, only by matching these empirical moments over polynomially many training examples, we prove that the generator can already learn notable class of distributions, including those that can be generated by two-layer neural networks.
翻译:生成Adversarial Networks (GANs) 是广泛使用的模式来学习复杂的真实世界分布。 在 GANs 中, 当歧视者无法再区分发电机的输出与一组培训示例时, 发电机的培训通常就停止了。 GANs的中心问题是, 当培训停止时, 生成的分布是否真正接近目标分布, 以及培训过程如何有效地达到这样的配置? 在本文中, 我们建立了一个理论结果, 以了解这个发电机与差异者的培训过程。 我们从经验上观察到, 在GANs 培训的早期阶段, 歧视者试图迫使发电机匹配发电机输出与目标分布之间的低度时间。 此外, 只有通过将这些经验性时刻与多个培训实例相匹配, 我们才能证明发电机已经学会了值得注意的分类, 包括由两层神经网络生成的分类。