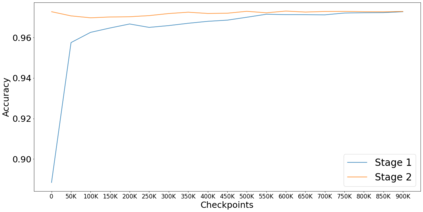
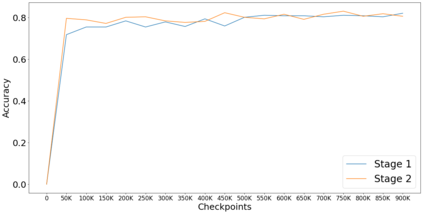
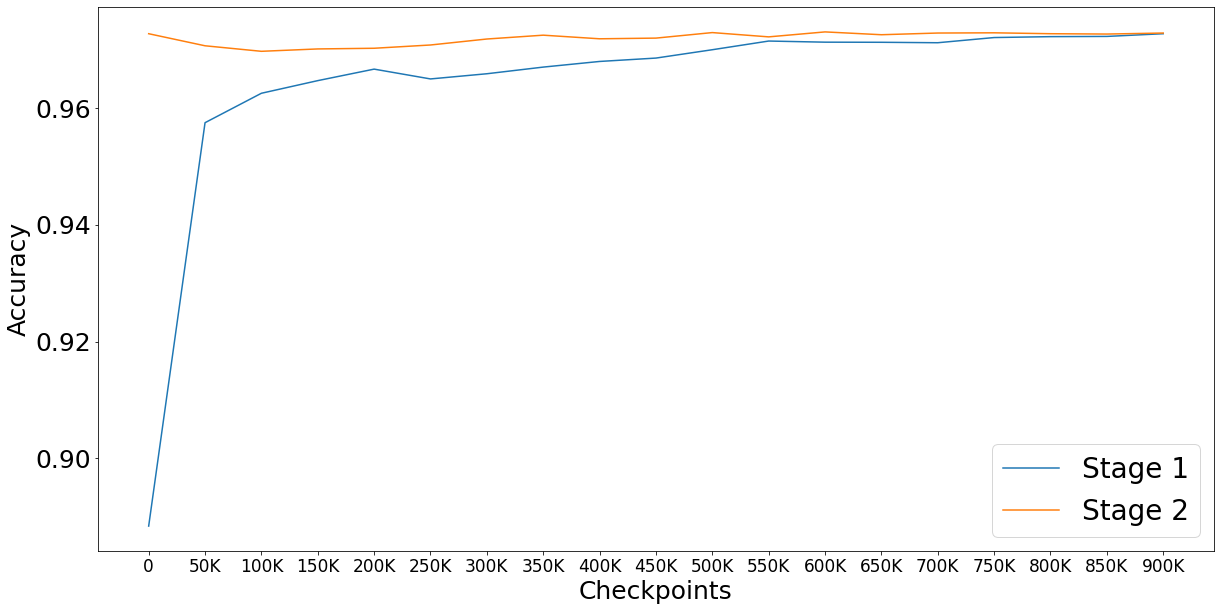
This paper presents EstBERT, a large pretrained transformer-based language-specific BERT model for Estonian. Recent work has evaluated multilingual BERT models on Estonian tasks and found them to outperform the baselines. Still, based on existing studies on other languages, a language-specific BERT model is expected to improve over the multilingual ones. We first describe the EstBERT pretraining process and then present the results of the models based on finetuned EstBERT for multiple NLP tasks, including POS and morphological tagging, named entity recognition and text classification. The evaluation results show that the models based on EstBERT outperform multilingual BERT models on five tasks out of six, providing further evidence towards a view that training language-specific BERT models are still useful, even when multilingual models are available.
翻译:本文件介绍了爱沙尼亚基于语言的大型预先培训变压器具体语言BERT模式。最近的工作评价了爱沙尼亚任务的多语言BERT模式,发现这些模式优于基线。然而,根据对其他语言的现有研究,预计针对语言的BERT模式将比多语言模式有所改进。我们首先介绍EstBERT培训前进程,然后介绍基于微调EstBERT模式的模型的结果,用于多项NLP任务,包括POS和形态标记、名称实体识别和文本分类。评价结果显示,基于EstBERT的模型在六项任务中优于多语言的BERT模式,进一步证明培训特定语言的BERT模式仍然有用,即使有多种模式。