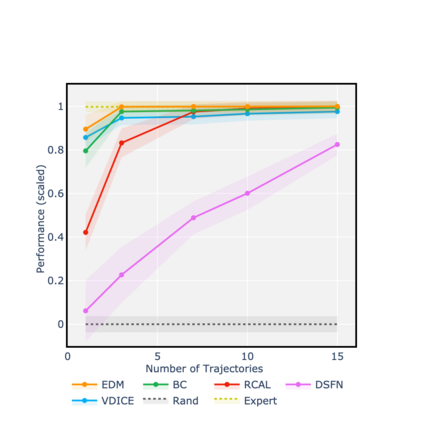
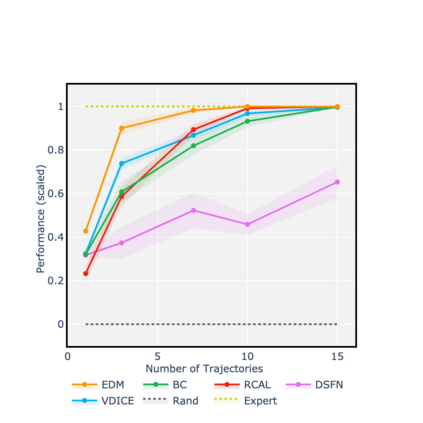
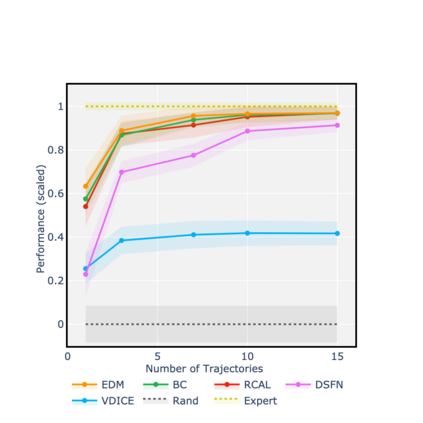
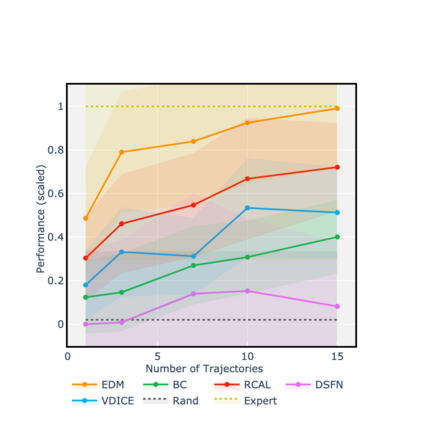
Consider learning a policy purely on the basis of demonstrated behavior -- that is, with no access to reinforcement signals, no knowledge of transition dynamics, and no further interaction with the environment. This *strictly batch imitation learning* problem arises wherever live experimentation is costly, such as in healthcare. One solution is simply to retrofit existing algorithms for apprenticeship learning to work in the offline setting. But such an approach leans heavily on off-policy evaluation or offline model estimation, and can be indirect and inefficient. We argue that a good solution should be able to explicitly parameterize a policy (i.e. respecting action conditionals), implicitly learn from rollout dynamics (i.e. leveraging state marginals), and -- crucially -- operate in an entirely offline fashion. To address this challenge, we propose a novel technique by *energy-based distribution matching* (EDM): By identifying parameterizations of the (discriminative) model of a policy with the (generative) energy function for state distributions, EDM yields a simple but effective solution that equivalently minimizes a divergence between the occupancy measure for the demonstrator and a model thereof for the imitator. Through experiments with application to control and healthcare settings, we illustrate consistent performance gains over existing algorithms for strictly batch imitation learning.
翻译:纯粹根据已证实的行为来学习一项政策 -- -- 也就是说,没有获得强化信号的机会,没有关于过渡动态的知识,也没有与环境进一步互动。在现场实验费用昂贵的地方,例如在医疗保健方面,就会产生这种严格批量模仿学习* 问题。一个解决办法只是改造现有的学徒学习算法,以便在离线环境中工作。但这种方法在很大程度上依赖于离线评估或离线模型估计,并且可能是间接和无效的。我们认为,一个好的解决方案应该能够明确参数化政策(即尊重行动条件)、隐性地从推出动态(即利用国家边缘)中学习,以及 -- -- 关键是 -- -- 以完全离线的方式运作。为了应对这一挑战,我们建议一种新的技术,通过基于能源的分布匹配* (EDM):通过确定州分配的(遗传)能源功能的参数化(差异性)模式,EDM产生一个简单而有效的解决方案,可以将示威者占用率措施之间的差异降低到最小程度(即利用国家边缘),以及 -- -- -- 关键是 -- -- 以完全脱线的方式运行的方式运行。我们用基于模拟的模型来进行模拟模型的测试。