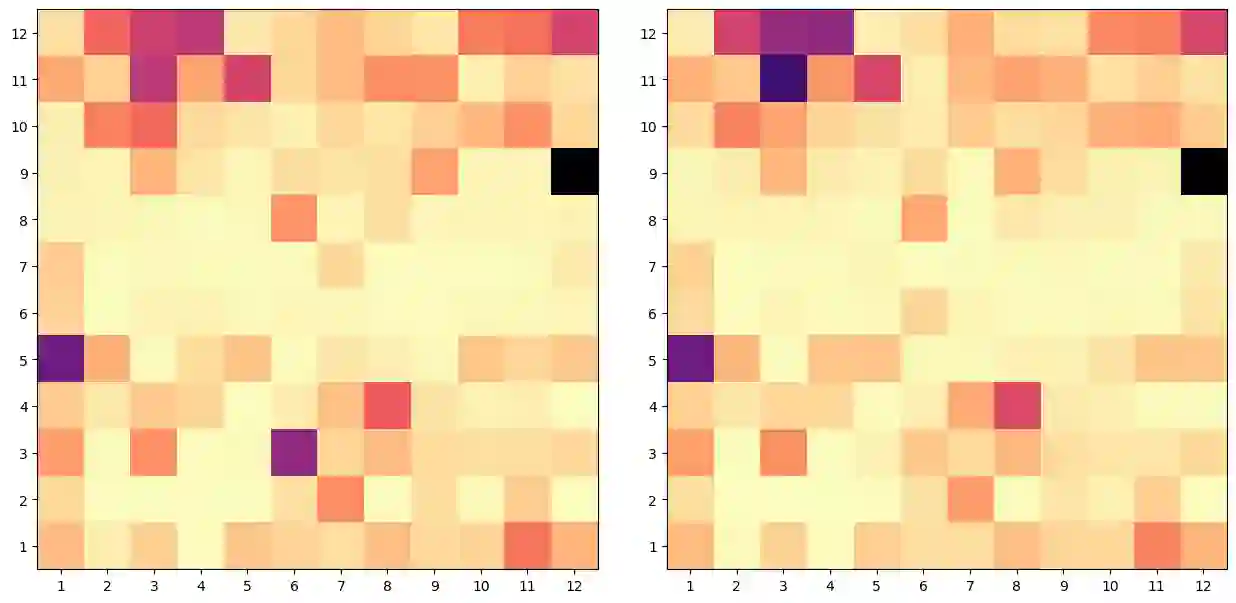
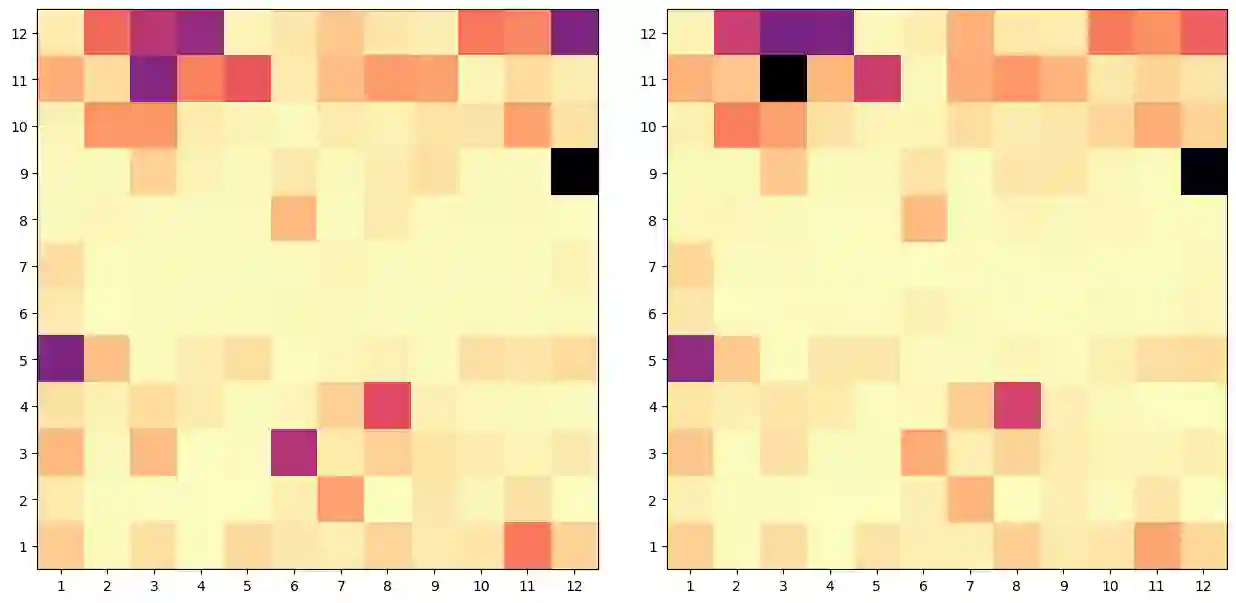
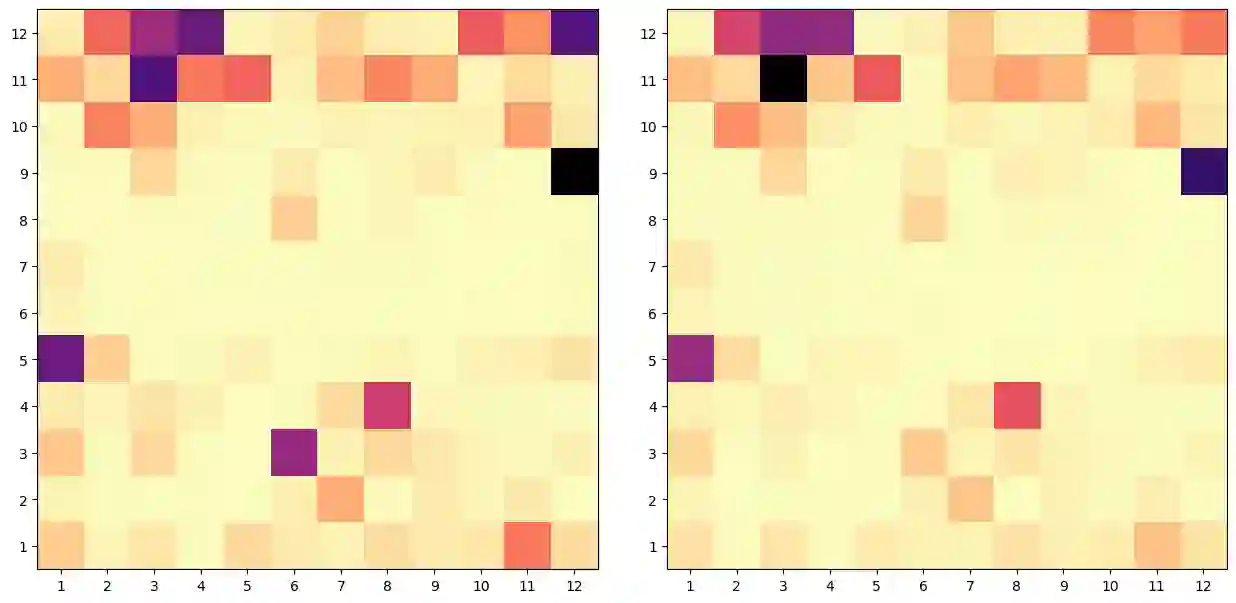
We probe pre-trained transformer language models for bridging inference. We first investigate individual attention heads in BERT and observe that attention heads at higher layers prominently focus on bridging relations in-comparison with the lower and middle layers, also, few specific attention heads concentrate consistently on bridging. More importantly, we consider language models as a whole in our second approach where bridging anaphora resolution is formulated as a masked token prediction task (Of-Cloze test). Our formulation produces optimistic results without any fine-tuning, which indicates that pre-trained language models substantially capture bridging inference. Our further investigation shows that the distance between anaphor-antecedent and the context provided to language models play an important role in the inference.
翻译:我们首先调查BERT的个别关注对象,然后发现高层的注意对象明显侧重于连接与中下层的比较关系,同样,很少有具体的注意对象始终专注于连接。 更重要的是,我们在第二种方法中将语言模式作为一个整体考虑,在第二种方法中,连接异常光谱分辨率是一项隐蔽的象征性预测任务(模拟测试 ) 。 我们的提法产生乐观的结果,而没有任何微调,这表明预先培训的语文模式在很大程度上抓住了连接的推断。 我们的进一步调查表明,异常光谱和为语言模型提供的环境之间的距离在推断中起着重要作用。