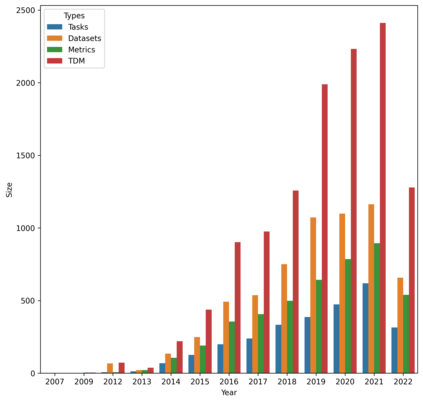
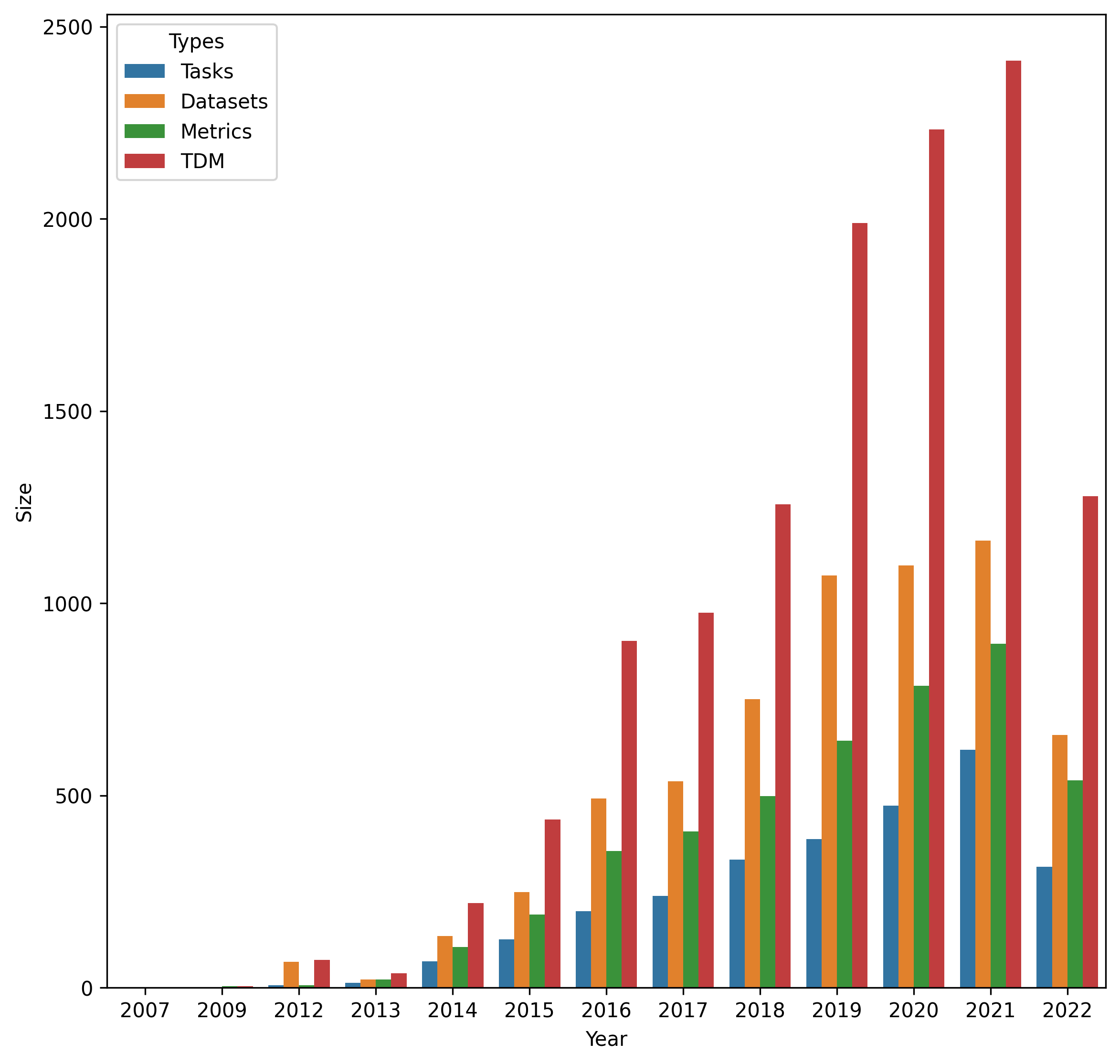
We present a large-scale empirical investigation of the zero-shot learning phenomena in a specific recognizing textual entailment (RTE) task category, i.e. the automated mining of leaderboards for Empirical AI Research. The prior reported state-of-the-art models for leaderboards extraction formulated as an RTE task, in a non-zero-shot setting, are promising with above 90% reported performances. However, a central research question remains unexamined: did the models actually learn entailment? Thus, for the experiments in this paper, two prior reported state-of-the-art models are tested out-of-the-box for their ability to generalize or their capacity for entailment, given leaderboard labels that were unseen during training. We hypothesize that if the models learned entailment, their zero-shot performances can be expected to be moderately high as well--perhaps, concretely, better than chance. As a result of this work, a zero-shot labeled dataset is created via distant labeling formulating the leaderboard extraction RTE task.
翻译:我们在特定的文本蕴涵识别(RTE)任务类别中进行了大规模的零射击学习现象的实证研究,即自动挖掘经验人工智能研究排行榜。针对在非零射击情况下公布的用于排行榜提取的先前报告的最先进模型,在文本蕴涵(RTE)任务执行上表现出了大于90%的性能,但是一个中心研究问题仍未得到考量:这些模型是否实际上学习了蕴涵?因此,在本文的实验中,将测试两个先前报道的最先进模型,在给定的经验人工智能研究排行榜标签在训练期间未见的情况下,它们的泛化能力或蕴涵能力。我们假设如果模型学习了蕴涵,那么可以期望其零射击性能也可能是适度高的--或许是比机会更好的结果。作为这项工作的结果,通过远程标记从排行榜提取RTE任务,创建了一个零射击标记的数据集。