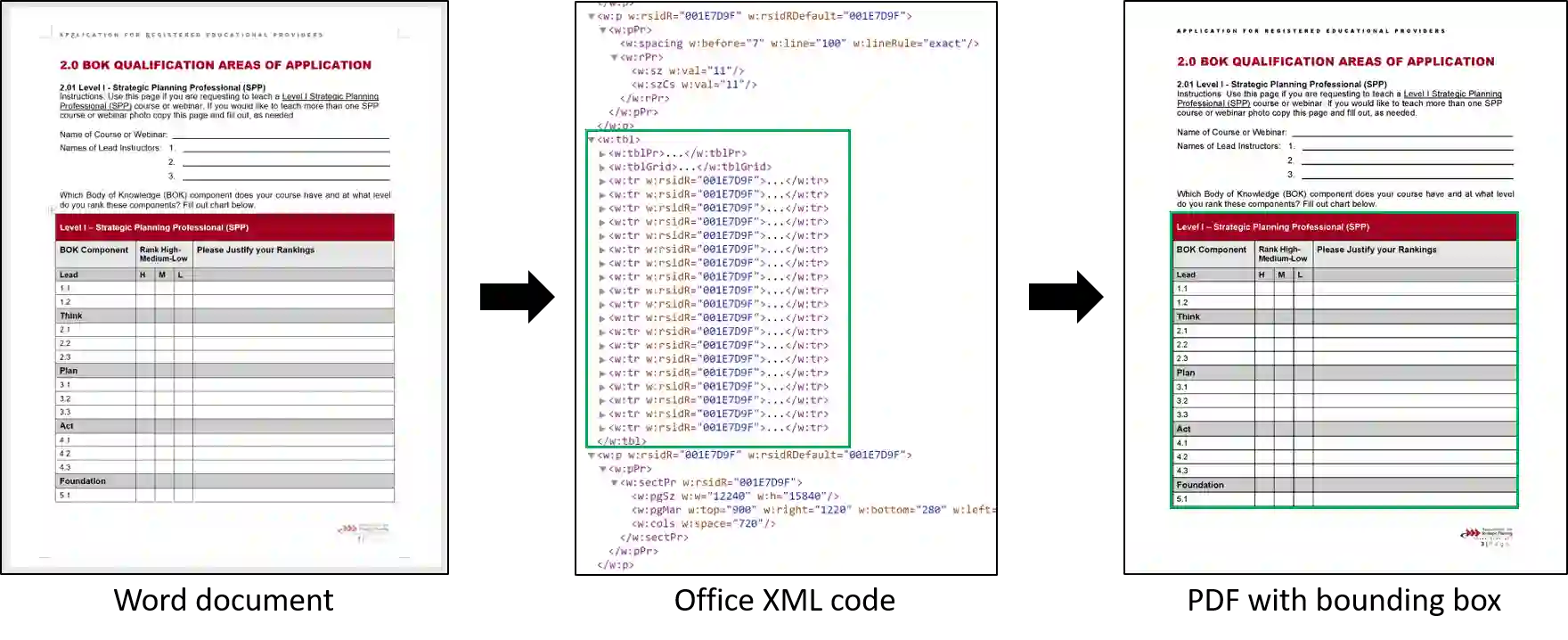
We present TableBank, a new image-based table detection and recognition dataset built with novel weak supervision from Word and Latex documents on the internet. Existing research for image-based table detection and recognition usually fine-tunes pre-trained models on out-of-domain data with a few thousands human labeled examples, which is difficult to generalize on real world applications. With TableBank that contains 417K high-quality labeled tables, we build several strong baselines using state-of-the-art models with deep neural networks. We make TableBank publicly available (https://github.com/doc-analysis/TableBank) and hope it will empower more deep learning approaches in the table detection and recognition task.
翻译:我们提出基于图像的表格检测和识别新数据集,这是在互联网上Word和Latex文件的新微弱监管下建立的基于图像的表格检测和识别新数据集,现有的基于图像的表格检测和识别研究通常以经过培训的外表数据模型为精细模型,有几千个人类标记的例子,难以在真实世界应用中一概而论。与含有417K高品质标签表格的表格的表格银行一起,我们利用具有深层神经网络的先进模型建立了几个强有力的基线。我们向公众提供(https://github.com/doc-analyation/TableBank),希望它能够增强在表格检测和识别任务中的更深层次学习方法。