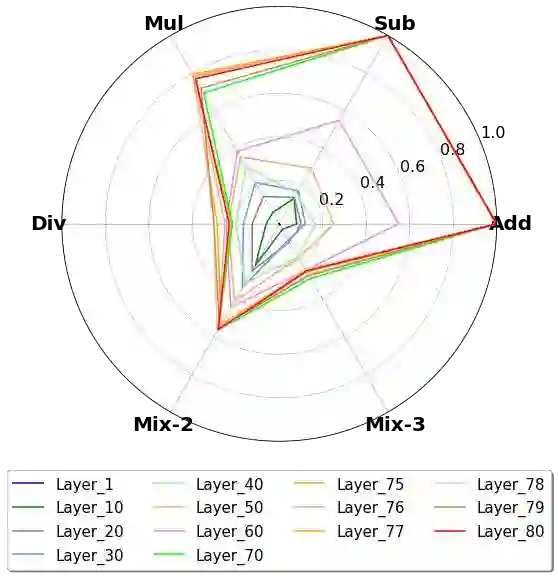
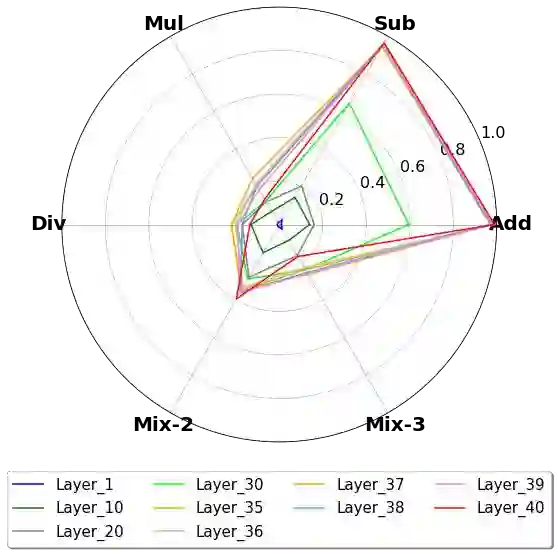
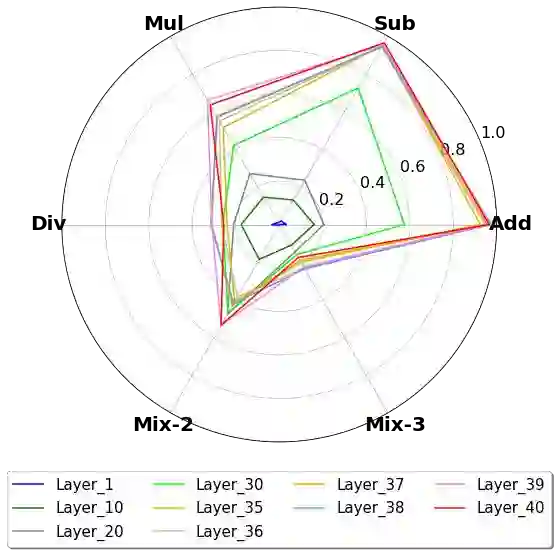
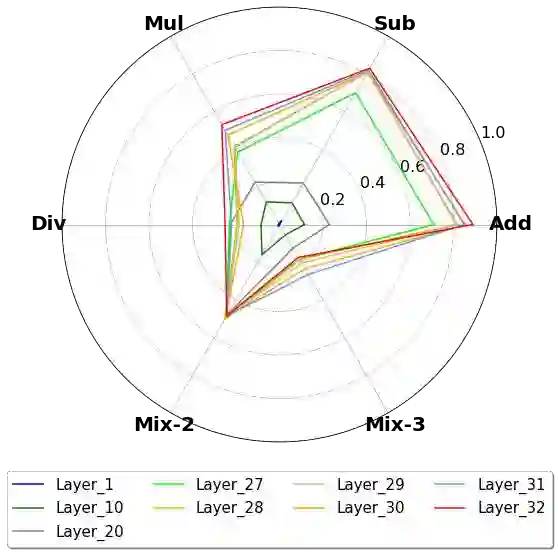
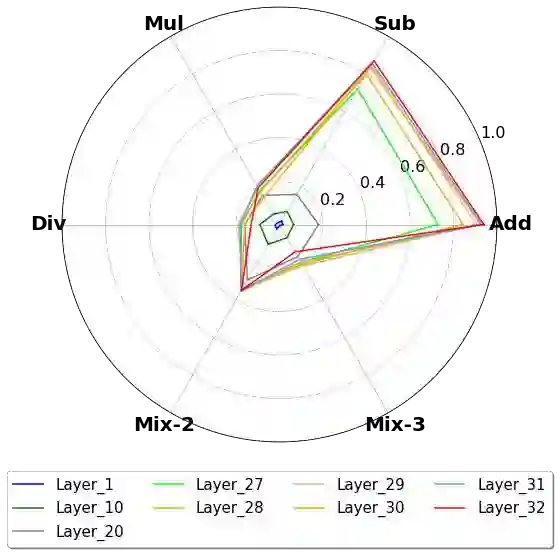
This paper presents an in-depth analysis of Large Language Models (LLMs), focusing on LLaMA, a prominent open-source foundational model in natural language processing. Instead of assessing LLaMA through its generative output, we design multiple-choice tasks to probe its intrinsic understanding in high-order tasks such as reasoning and computation. We examine the model horizontally, comparing different sizes, and vertically, assessing different layers. We unveil several key and uncommon findings based on the designed probing tasks: (1) Horizontally, enlarging model sizes almost could not automatically impart additional knowledge or computational prowess. Instead, it can enhance reasoning abilities, especially in math problem solving, and helps reduce hallucinations, but only beyond certain size thresholds; (2) In vertical analysis, the lower layers of LLaMA lack substantial arithmetic and factual knowledge, showcasing logical thinking, multilingual and recognitive abilities, with top layers housing most computational power and real-world knowledge.
翻译:暂无翻译