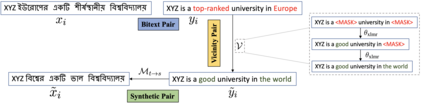
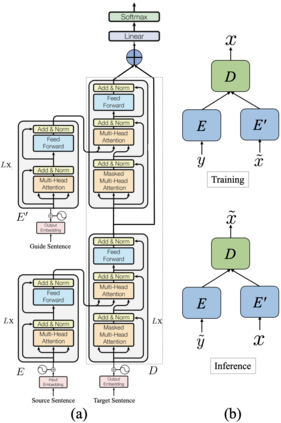
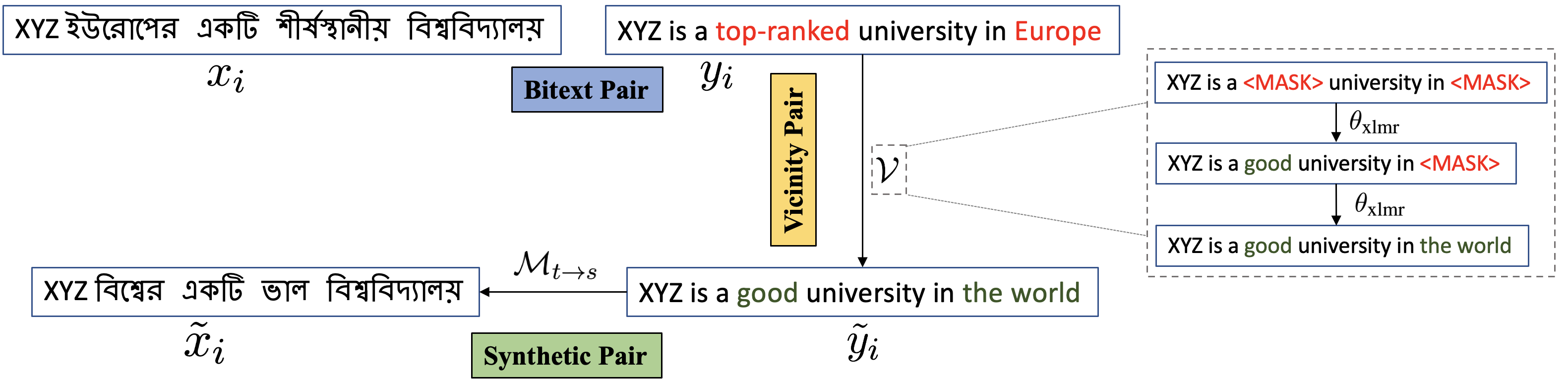
The success of Neural Machine Translation (NMT) largely depends on the availability of large bitext training corpora. Due to the lack of such large corpora in low-resource language pairs, NMT systems often exhibit poor performance. Extra relevant monolingual data often helps, but acquiring it could be quite expensive, especially for low-resource languages. Moreover, domain mismatch between bitext (train/test) and monolingual data might degrade the performance. To alleviate such issues, we propose AUGVIC, a novel data augmentation framework for low-resource NMT which exploits the vicinal samples of the given bitext without using any extra monolingual data explicitly. It can diversify the in-domain bitext data with finer level control. Through extensive experiments on four low-resource language pairs comprising data from different domains, we have shown that our method is comparable to the traditional back-translation that uses extra in-domain monolingual data. When we combine the synthetic parallel data generated from AUGVIC with the ones from the extra monolingual data, we achieve further improvements. We show that AUGVIC helps to attenuate the discrepancies between relevant and distant-domain monolingual data in traditional back-translation. To understand the contributions of different components of AUGVIC, we perform an in-depth framework analysis.
翻译:神经机器翻译(NMT)能否成功,主要取决于能否获得大量培训分数。由于在低资源语言配对中缺乏如此庞大的连体,NMT系统往往表现不佳。额外的单语数据往往有帮助,但获得这些数据的费用可能相当昂贵,特别是对低资源语言而言。此外,比特(培训/测试)和单语数据之间的域错配可能会降低性能。为了缓解这些问题,我们提议AUGVIC,这是一个为低资源NMT开发比特样的新的数据增强框架,它利用了给定比特的比特样本,而没有明确使用任何额外的单语数据。NMT系统可以将内部的比特数据多样化,并具有精细的控制。通过对四对包含不同领域数据的低资源语言配对的广泛实验,我们已经表明,我们的方法可以与使用多语言单语数据的传统回译方法相比。当我们把从AUGVIC产生的合成平行数据与超单语数据组合结合起来时,我们取得了进一步的改进。我们表明,AUGVIC帮助加深了对不同语言框架的深度分析。