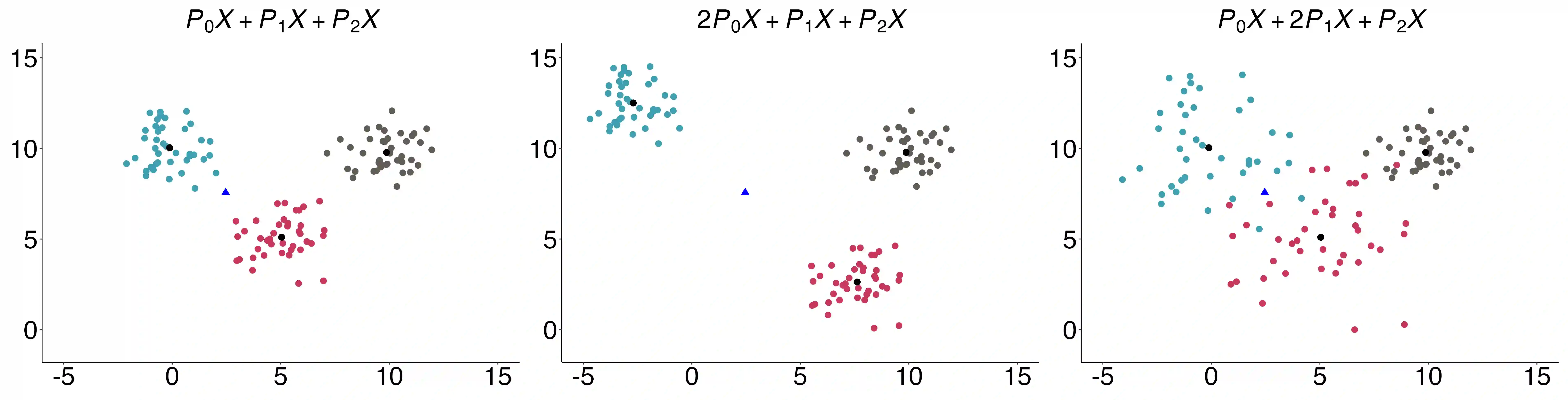
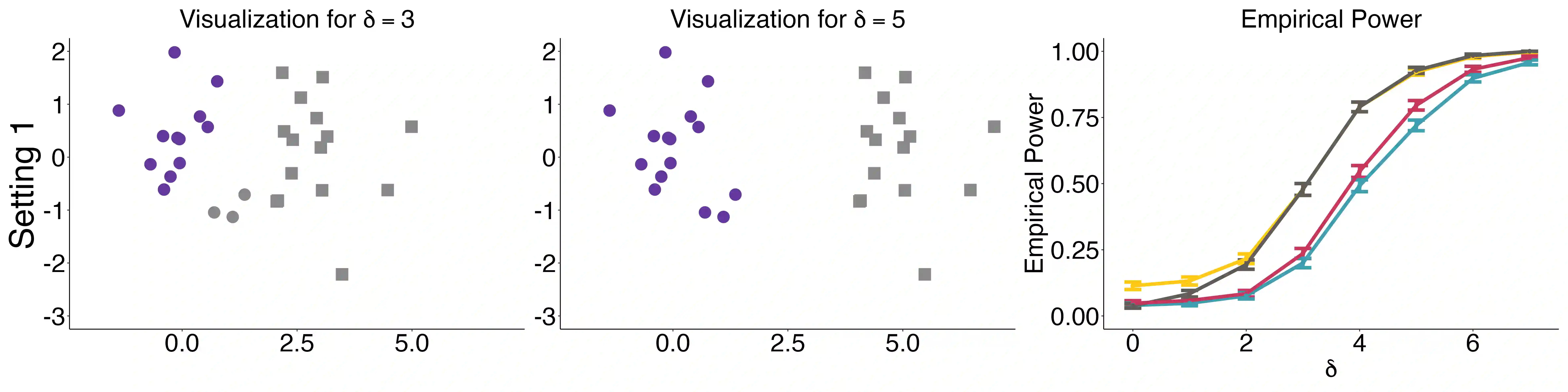
In many modern statistical problems, the limited available data must be used both to develop the hypotheses to test, and to test these hypotheses-that is, both for exploratory and confirmatory data analysis. Reusing the same dataset for both exploration and testing can lead to massive selection bias, leading to many false discoveries. Selective inference is a framework that allows for performing valid inference even when the same data is reused for exploration and testing. In this work, we are interested in the problem of selective inference for data clustering, where a clustering procedure is used to hypothesize a separation of the data points into a collection of subgroups, and we then wish to test whether these data-dependent clusters in fact represent meaningful differences within the data. Recent work by Gao et al. [2022] provides a framework for doing selective inference for this setting, where a hierarchical clustering algorithm is used for producing the cluster assignments, which was then extended to k-means clustering by Chen and Witten [2022]. Both these works rely on assuming a known covariance structure for the data, but in practice, the noise level needs to be estimated-and this is particularly challenging when the true cluster structure is unknown. In our work, we extend this work to the setting of noise with unknown variance, and provide a selective inference method for this more general setting. Empirical results show that our new method is better able to maintain high power while controlling Type I error when the true noise level is unknown.
翻译:暂无翻译