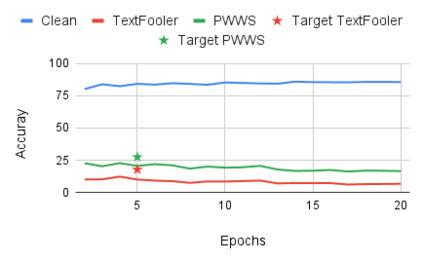
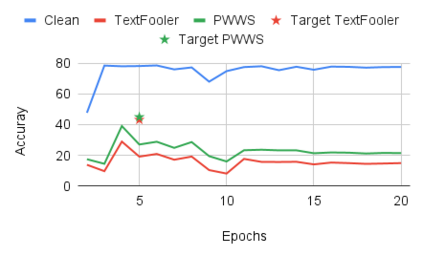
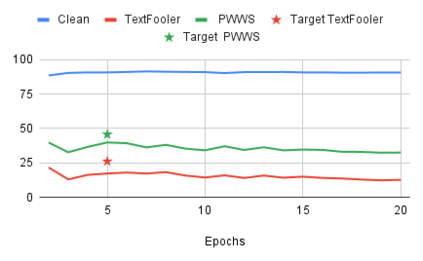
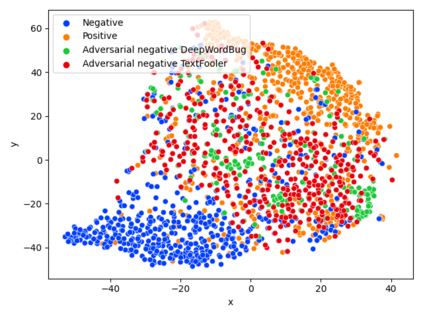
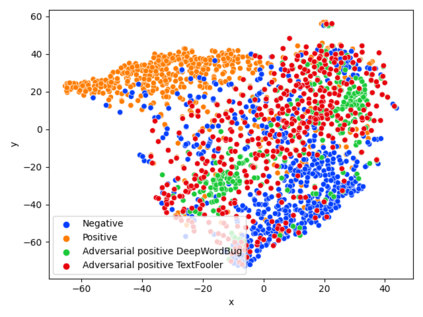
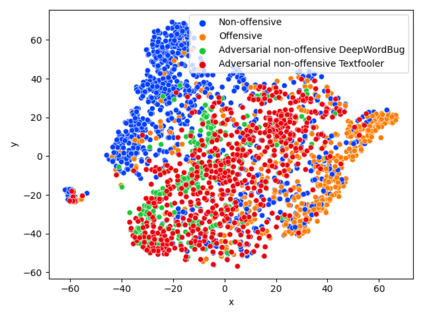
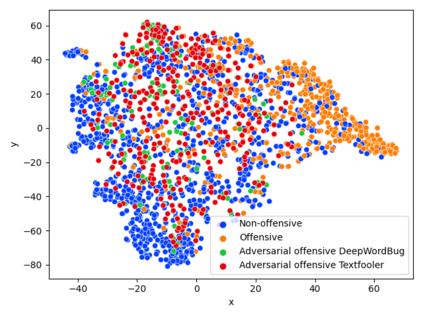
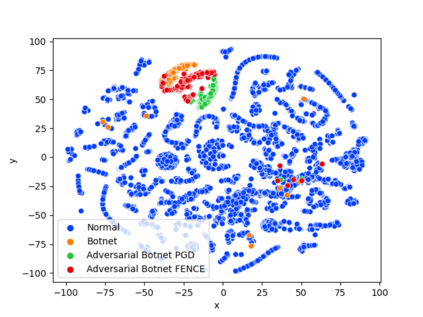
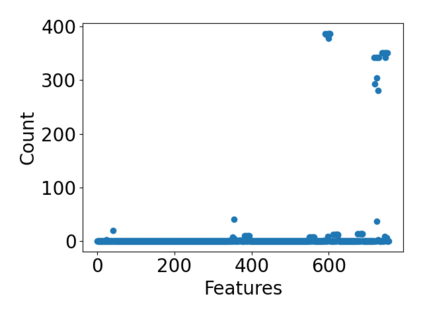
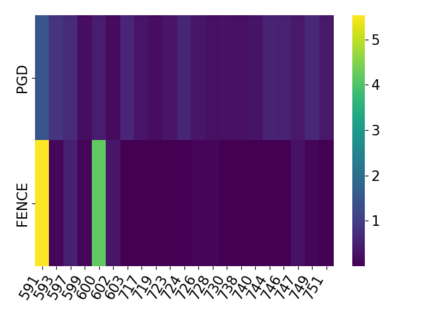
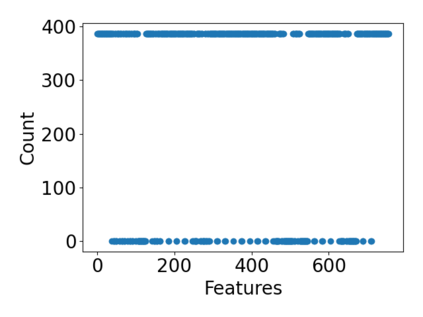
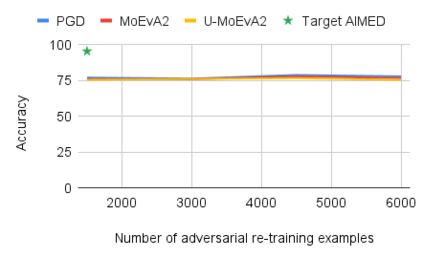
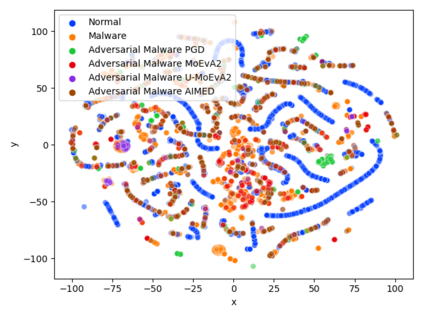
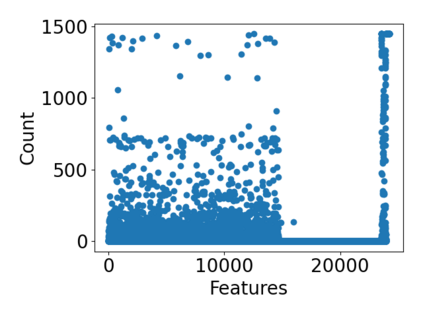
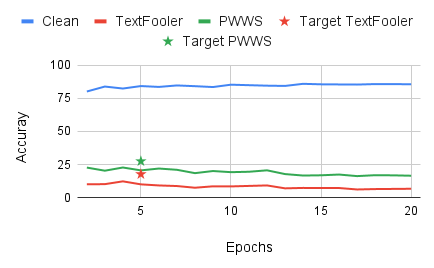
While the literature on security attacks and defense of Machine Learning (ML) systems mostly focuses on unrealistic adversarial examples, recent research has raised concern about the under-explored field of realistic adversarial attacks and their implications on the robustness of real-world systems. Our paper paves the way for a better understanding of adversarial robustness against realistic attacks and makes two major contributions. First, we conduct a study on three real-world use cases (text classification, botnet detection, malware detection)) and five datasets in order to evaluate whether unrealistic adversarial examples can be used to protect models against realistic examples. Our results reveal discrepancies across the use cases, where unrealistic examples can either be as effective as the realistic ones or may offer only limited improvement. Second, to explain these results, we analyze the latent representation of the adversarial examples generated with realistic and unrealistic attacks. We shed light on the patterns that discriminate which unrealistic examples can be used for effective hardening. We release our code, datasets and models to support future research in exploring how to reduce the gap between unrealistic and realistic adversarial attacks.
翻译:虽然关于安全攻击和机器学习系统防御的文献大多侧重于不现实的对抗性实例,但最近的研究对现实对抗性攻击的探索不足的领域及其对现实世界系统稳健性的影响提出了关切。我们的文件为更好地理解对现实攻击的对抗性攻击的有力性铺平了道路,并作出了两大贡献。首先,我们对三个真实世界使用的案例(文字分类、肉网探测、恶意软件探测)和五个数据集进行了研究,以便评估是否可以利用不现实的对抗性例子来保护模型不受现实例子的影响。我们的结果揭示了不同使用案例之间的差异,不现实的例子可以与现实的对立性攻击一样有效,或者只能提供有限的改进。第二,为了解释这些结果,我们分析了以现实和不现实攻击生成的对立性例子的潜在代表性。我们揭示了那些不切实际的例子可用于有效硬化的模式。我们发布了我们的代码、数据集和模型,以支持今后研究如何缩小不现实和现实的对立性攻击之间的差距。