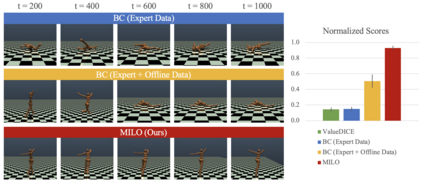
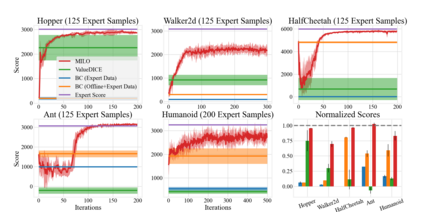
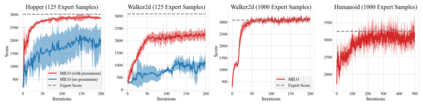
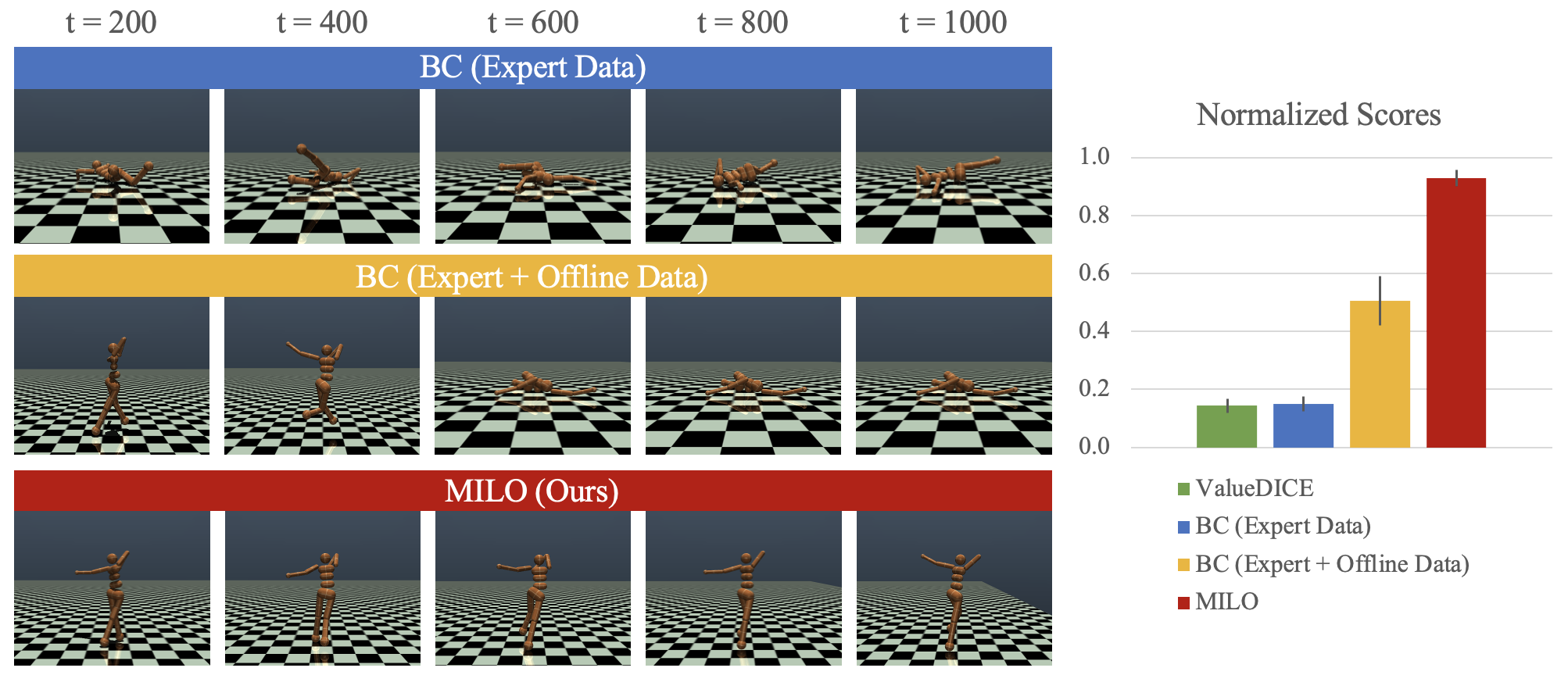
This paper studies offline Imitation Learning (IL) where an agent learns to imitate an expert demonstrator without additional online environment interactions. Instead, the learner is presented with a static offline dataset of state-action-next state transition triples from a potentially less proficient behavior policy. We introduce Model-based IL from Offline data (MILO): an algorithmic framework that utilizes the static dataset to solve the offline IL problem efficiently both in theory and in practice. In theory, even if the behavior policy is highly sub-optimal compared to the expert, we show that as long as the data from the behavior policy provides sufficient coverage on the expert state-action traces (and with no necessity for a global coverage over the entire state-action space), MILO can provably combat the covariate shift issue in IL. Complementing our theory results, we also demonstrate that a practical implementation of our approach mitigates covariate shift on benchmark MuJoCo continuous control tasks. We demonstrate that with behavior policies whose performances are less than half of that of the expert, MILO still successfully imitates with an extremely low number of expert state-action pairs while traditional offline IL method such as behavior cloning (BC) fails completely. Source code is provided at https://github.com/jdchang1/milo.
翻译:本文研究离线模拟学习(IL), 代理商在不增加在线环境互动的情况下学习模仿专家演示人, 而不用额外的在线环境互动。 相反, 向学习人展示了一个固定的离线演示数据组, 显示国家- 行动- 下一步国家过渡三倍的固定离线数据集, 这些数据来自可能不太熟练的行为政策。 我们引入了基于模型的离线数据( MILO ) : 一个算法框架, 利用静态数据集在理论和实践上有效解决离线 IL 问题。 在理论上和实践中, 实际实施我们的方法可以减轻 MuJoco 持续控制任务基准上的共变换。 我们证明,行为政策的表现比专家低一半, 只要行为政策的数据能够充分覆盖专家的国家- 行动轨迹( 无需覆盖整个州- 行动空间的全球范围), MILILO 就可以肯定地解决IL 数据中的共变换问题。 补充我们的理论结果, 我们还证明, 实际实施我们的方法可以减轻 MuJoco 持续控制任务上的共变换。 我们证明, 行为政策如果其表现低于专家的一半,, MILILILO仍然成功地模仿/ BBC 以极低的源码/ 标准。