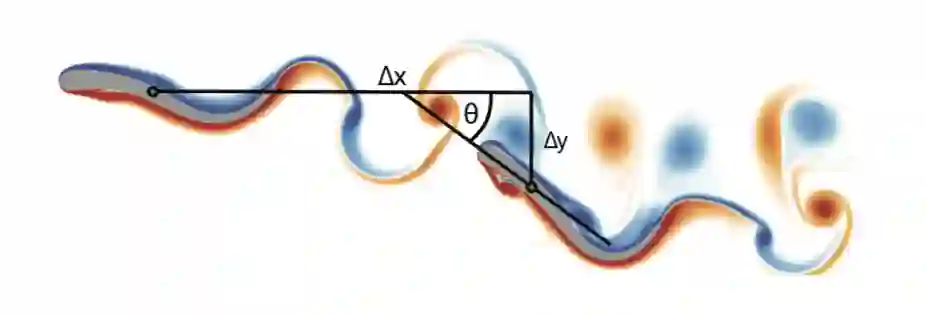
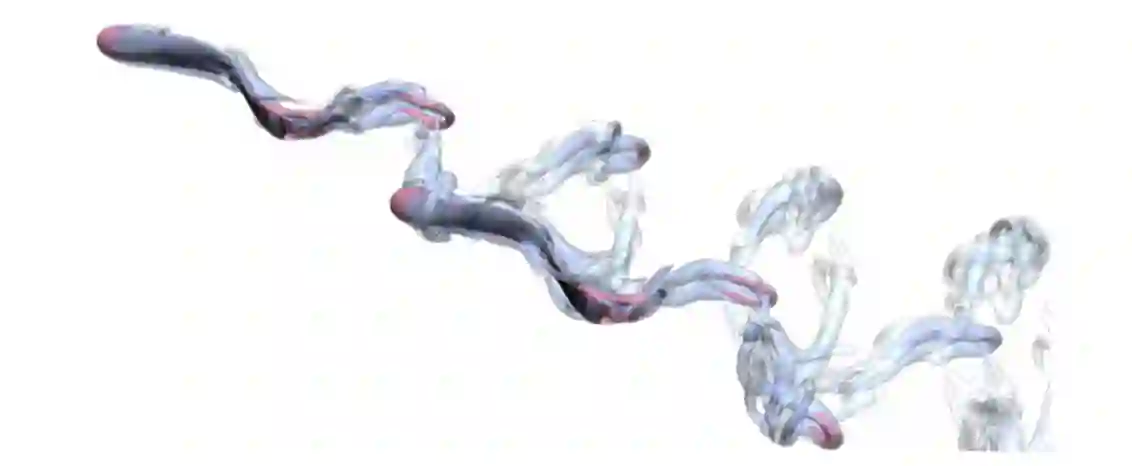
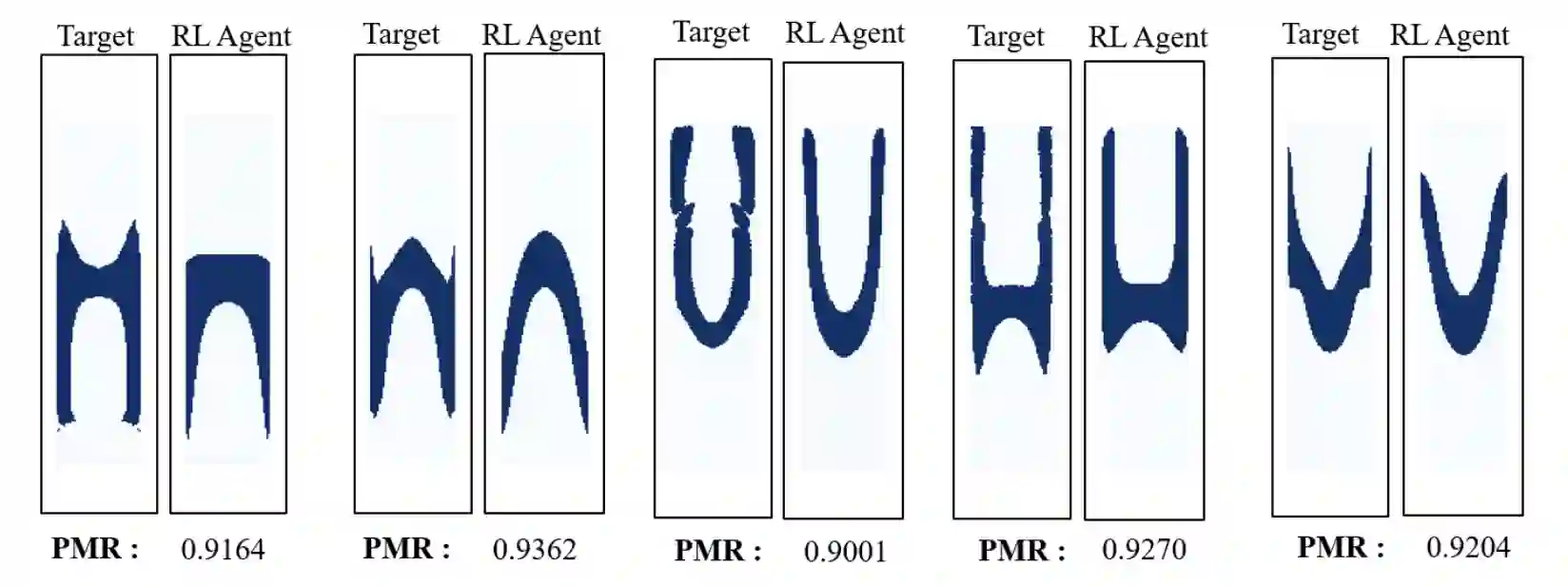
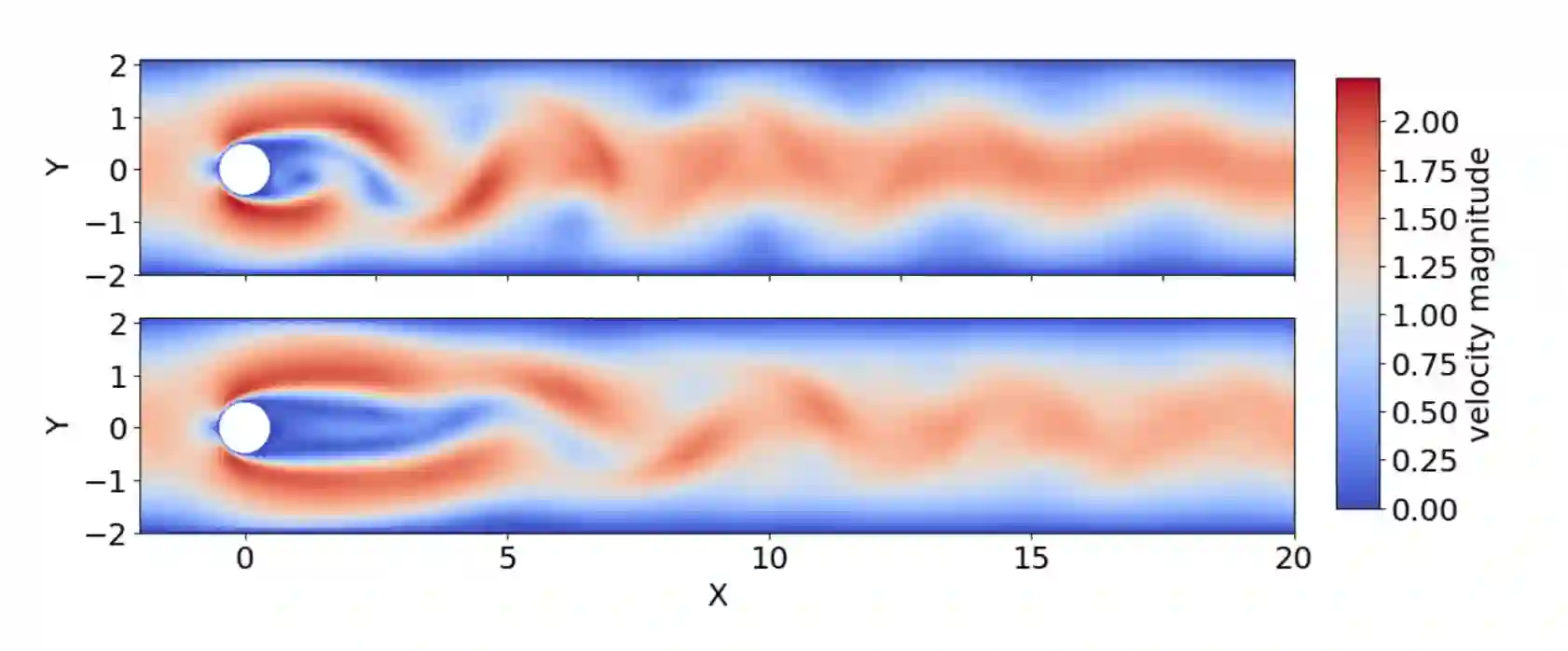
Deep reinforcement learning (DRL) has recently been adopted in a wide range of physics and engineering domains for its ability to solve decision-making problems that were previously out of reach due to a combination of non-linearity and high dimensionality. In the last few years, it has spread in the field of computational mechanics, and particularly in fluid dynamics, with recent applications in flow control and shape optimization. In this work, we conduct a detailed review of existing DRL applications to fluid mechanics problems. In addition, we present recent results that further illustrate the potential of DRL in Fluid Mechanics. The coupling methods used in each case are covered, detailing their advantages and limitations. Our review also focuses on the comparison with classical methods for optimal control and optimization. Finally, several test cases are described that illustrate recent progress made in this field. The goal of this publication is to provide an understanding of DRL capabilities along with state-of-the-art applications in fluid dynamics to researchers wishing to address new problems with these methods.
翻译:最近,在一系列广泛的物理学和工程学领域采用了深度强化学习(DRL),以便其解决以前由于非线性和高度性的综合作用而无法达到的决策问题的能力。在过去几年里,它已经扩散到计算机学领域,特别是流体动力学领域,最近在流动控制和形状优化方面应用了流体动力学。在这项工作中,我们详细审查了现有DRL应用于流体力学问题。此外,我们介绍了最近的结果,进一步说明了DRL在流体机械学方面的潜力。每种情况下使用的混合方法都包括在内,详细说明了这些方法的优点和局限性。我们的审查还侧重于与传统方法的比较,以便优化控制和优化。最后,我们介绍了几个测试案例,说明最近在这一领域取得的进展。本出版物的目的是向希望解决这些方法的新问题的研究人员介绍DRL能力以及流体动力方面的最新应用情况。