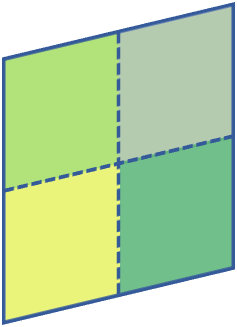
The great success of machine learning with massive amounts of data comes at a price of huge computation costs and storage for training and tuning. Recent studies on dataset condensation attempt to reduce the dependence on such massive data by synthesizing a compact training dataset. However, the existing approaches have fundamental limitations in optimization due to the limited representability of synthetic datasets without considering any data regularity characteristics. To this end, we propose a novel condensation framework that generates multiple synthetic data with a limited storage budget via efficient parameterization considering data regularity. We further analyze the shortcomings of the existing gradient matching-based condensation methods and develop an effective optimization technique for improving the condensation of training data information. We propose a unified algorithm that drastically improves the quality of condensed data against the current state-of-the-art on CIFAR-10, ImageNet, and Speech Commands.
翻译:利用大量数据进行机器学习的巨大成功是以巨大的计算成本和为培训和调试而储存的巨额费用为代价的。最近关于数据集浓缩的研究试图通过合成一个紧凑的培训数据集来减少对如此庞大数据的依赖。然而,由于合成数据集的可代表性有限,而没有考虑到任何数据的正常性特点,现有方法在优化方面有根本性的局限性。为此,我们提议了一个新的凝结框架,通过考虑到数据规律性的有效参数化来生成多种合成数据,其储存预算有限。我们进一步分析现有的梯度匹配凝结方法的缺点,并开发一种有效的优化技术,以改进培训数据信息的凝结。我们建议一种统一的算法,根据目前有关CIFAR-10、图像网络和语音指令的最新技术,大幅度提高浓缩数据的质量。