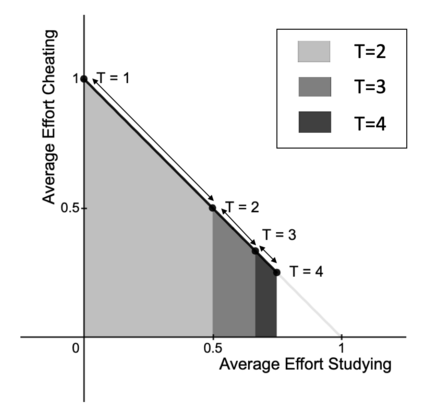
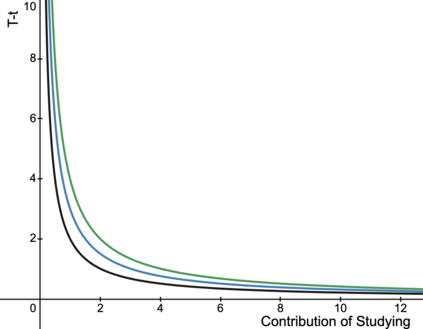
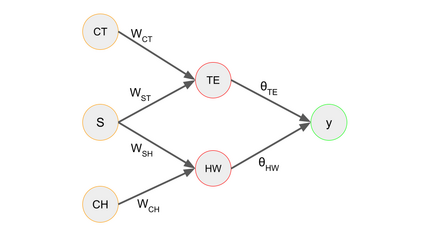
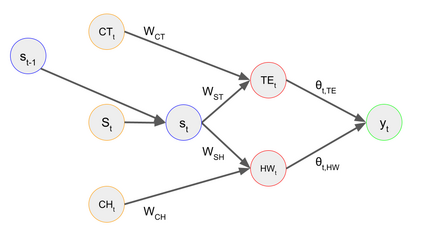
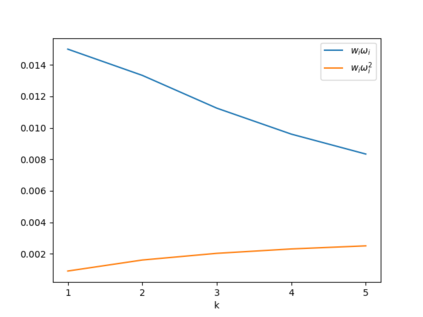
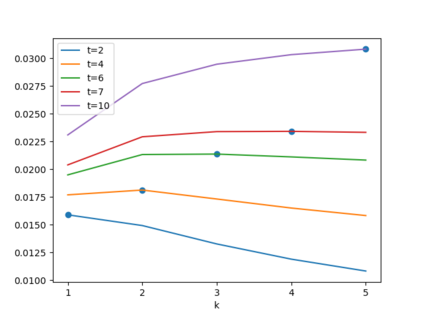
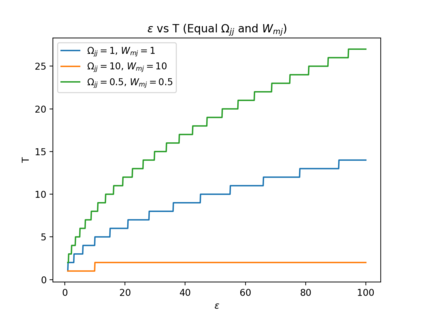
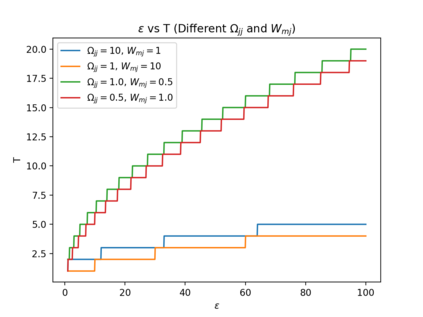
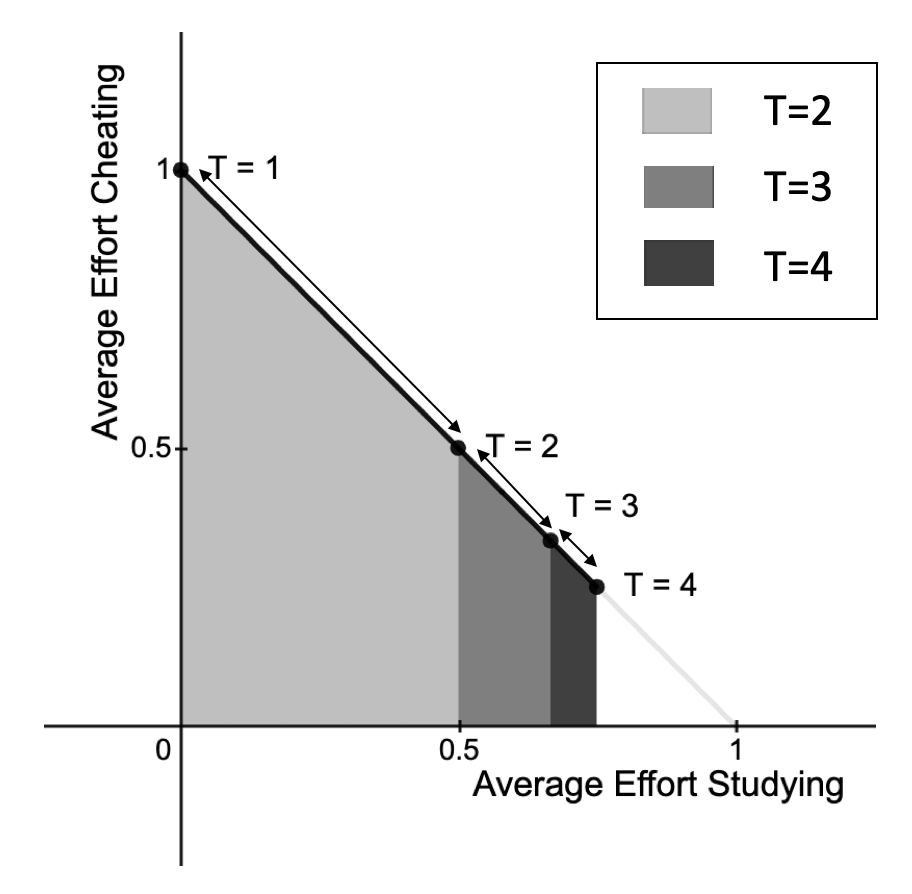
Automated decision-making tools increasingly assess individuals to determine if they qualify for high-stakes opportunities. A recent line of research investigates how strategic agents may respond to such scoring tools to receive favorable assessments. While prior work has focused on the short-term strategic interactions between a decision-making institution (modeled as a principal) and individual decision-subjects (modeled as agents), we investigate interactions spanning multiple time-steps. In particular, we consider settings in which the agent's effort investment today can accumulate over time in the form of an internal state - impacting both his future rewards and that of the principal. We characterize the Stackelberg equilibrium of the resulting game and provide novel algorithms for computing it. Our analysis reveals several intriguing insights about the role of multiple interactions in shaping the game's outcome: First, we establish that in our stateful setting, the class of all linear assessment policies remains as powerful as the larger class of all monotonic assessment policies. While recovering the principal's optimal policy requires solving a non-convex optimization problem, we provide polynomial-time algorithms for recovering both the principal and agent's optimal policies under common assumptions about the process by which effort investments convert to observable features. Most importantly, we show that with multiple rounds of interaction at her disposal, the principal is more effective at incentivizing the agent to accumulate effort in her desired direction. Our work addresses several critical gaps in the growing literature on the societal impacts of automated decision-making - by focusing on longer time horizons and accounting for the compounding nature of decisions individuals receive over time.
翻译:自动化决策工具越来越多地评估个人,以确定他们是否有资格获得高级机会。最近的一系列研究调查了战略代理商如何对这种评分工具作出反应,以获得有利的评估。虽然先前的工作侧重于决策机构(制成主要)和单个决策主体(制成代理商)之间的短期战略互动,但我们调查了跨越多个时间步骤的相互作用。特别是,我们考虑了代理商今天的努力投资能够以内部状态的形式逐渐积累的环境,既影响他的未来回报,也影响本金。我们将由此产生的游戏的Stackelberg平衡化,并为计算它提供新的算法。我们的分析揭示了对多个决策机构(制成主机)和单个决策主体(制成)之间多重互动作用的深刻认识:首先,我们确定在我们所处的状态下,所有线性评估政策的类别仍然与所有单一评估政策的较大类别一样强大。虽然要弥补本公司的最佳政策需要解决非convex优化问题,但我们为在恢复主要互动机制的关键时间计算方法方面提供了多重时间算法,我们通过在最大程度上将核心投资转向最理想的投资模式,通过改变我们共同的流程,从而将最佳投资转化为最佳方向。