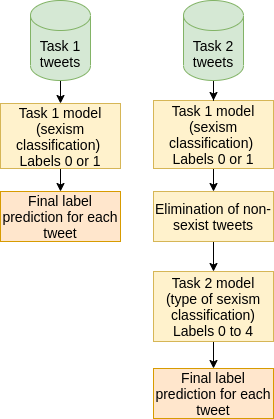
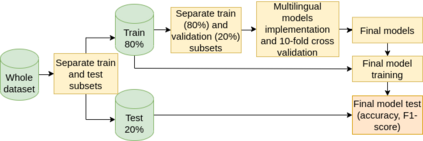
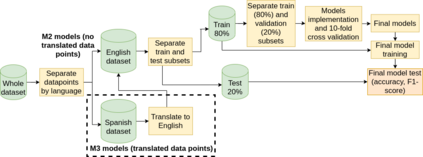
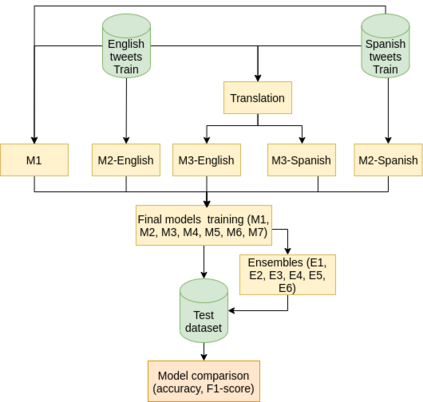
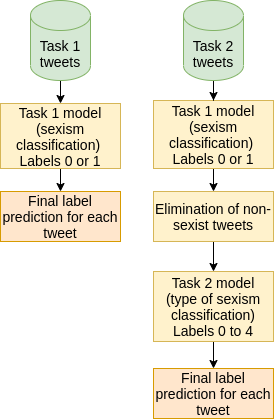
The popularity of social media has created problems such as hate speech and sexism. The identification and classification of sexism in social media are very relevant tasks, as they would allow building a healthier social environment. Nevertheless, these tasks are considerably challenging. This work proposes a system to use multilingual and monolingual BERT and data points translation and ensemble strategies for sexism identification and classification in English and Spanish. It was conducted in the context of the sEXism Identification in Social neTworks shared 2021 (EXIST 2021) task, proposed by the Iberian Languages Evaluation Forum (IberLEF). The proposed system and its main components are described, and an in-depth hyperparameters analysis is conducted. The main results observed were: (i) the system obtained better results than the baseline model (multilingual BERT); (ii) ensemble models obtained better results than monolingual models; and (iii) an ensemble model considering all individual models and the best standardized values obtained the best accuracies and F1-scores for both tasks. This work obtained first place in both tasks at EXIST, with the highest accuracies (0.780 for task 1 and 0.658 for task 2) and F1-scores (F1-binary of 0.780 for task 1 and F1-macro of 0.579 for task 2).
翻译:社会媒体的普及造成了诸如仇恨言论和性别主义之类的问题; 社会媒体对性别主义的识别和分类是非常相关的任务,因为它们有助于建立一个更健康的社会环境; 然而,这些任务具有相当大的挑战性; 这项工作提出了使用多种语言和单一语言的BERT和数据点翻译系统,以及用英语和西班牙语进行性别主义识别和分类的数据点翻译和共同战略; 这项工作是在2021年共同的社会新工作(EXIST 2021)中确定和分类的; 由Iberian语言评价论坛(IberLEF)提议,在2021年的社会新工作(EXIST 2021)中确定和分类的性别主义任务的背景下进行的; 拟议的系统及其主要组成部分得到了描述,并进行了深入的超参数分析; 所观察到的主要成果是:(一) 系统取得了比基线模型(多语言BERT)更好的结果;(二) 组合模型取得比单一语言模式更好的结果;(三) 一个包含所有个人模式和最佳标准价值观的系列模型(EXIST第一组任务和F1-80任务(0.61 Fcricro)和0.18任务1F任务第1号任务(0.182)和0.18任务第1号任务第1号任务第1号任务)和0.18任务第1号任务(0.180任务)和0.18任务第1号任务第1号任务第1号任务第1号任务)。