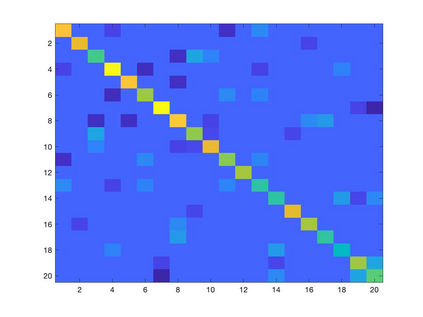
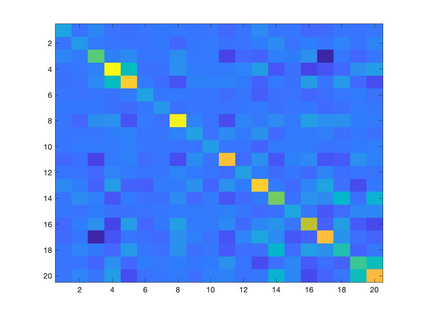
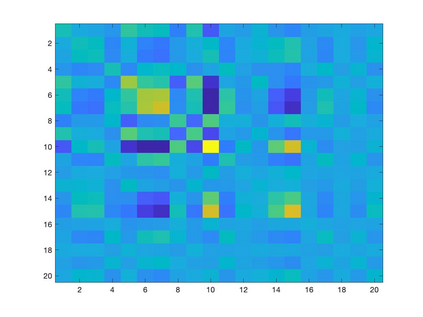
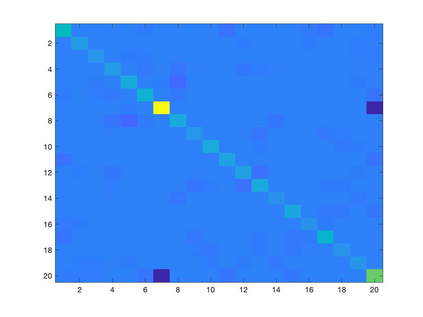
Learning a suitable graph is an important precursor to many graph signal processing (GSP) pipelines, such as graph spectral signal compression and denoising. Previous graph learning algorithms either i) make some assumptions on connectivity (e.g., graph sparsity), or ii) make simple graph edge assumptions such as positive edges only. In this paper, given an empirical covariance matrix $\bar{C}$ computed from data as input, we consider a structural assumption on the graph Laplacian matrix $L$: the first $K$ eigenvectors of $L$ are pre-selected, e.g., based on domain-specific criteria, such as computation requirement, and the remaining eigenvectors are then learned from data. One example use case is image coding, where the first eigenvector is pre-chosen to be constant, regardless of available observed data. We first prove that the subspace of symmetric positive semi-definite (PSD) matrices $H_{u}^+$ with the first $K$ eigenvectors being $\{u_k\}$ in a defined Hilbert space is a convex cone. We then construct an operator to project a given positive definite (PD) matrix $L$ to $H_{u}^+$, inspired by the Gram-Schmidt procedure. Finally, we design an efficient hybrid graphical lasso/projection algorithm to compute the most suitable graph Laplacian matrix $L^* \in H_{u}^+$ given $\bar{C}$. Experimental results show that given the first $K$ eigenvectors as a prior, our algorithm outperforms competing graph learning schemes using a variety of graph comparison metrics.
翻译:学习一个合适的图形是许多图形信号处理( GSP) 管道的重要前奏, 如图形光谱信号压缩和拆分等 。 先前的图形学习算法 i (i) 对连接( 如图光度) 做出一些假设, 或 ii (ii) 做出简单的图形边缘假设, 例如正边缘 。 在本文中, 实验性共变矩阵 $\ bar{C} 从数据中计算为数据输入, 我们考虑在图形 Laplacian mission (GPD) 中做出一个结构性假设: 首次以美元为单位, 美元为美元, 例如, 之前的图表学习算法根据特定的域( 如计算要求), 然后从数据中学习其余的偏差参数 。 一个例子是图像编译, 第一次以美元为正数的正数 美元 。 我们首先给出的 美元 美元 美元 基数 基数 基数 的基数 基数 基数 。