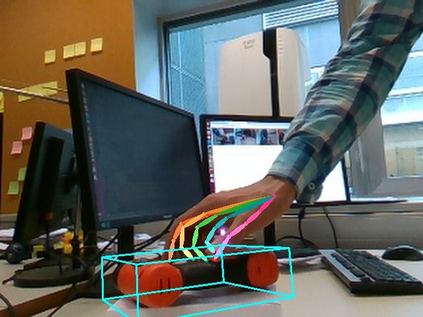
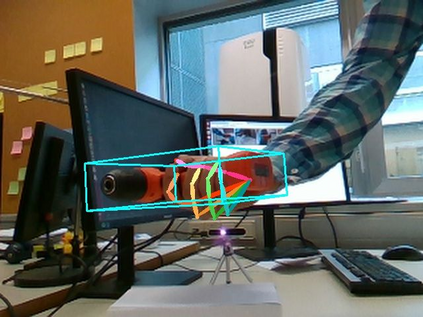
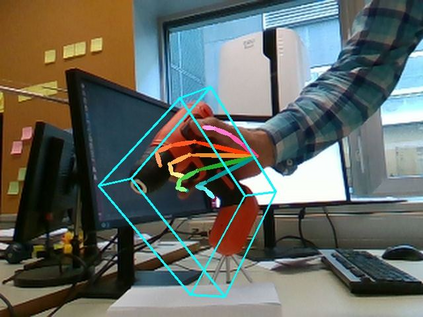
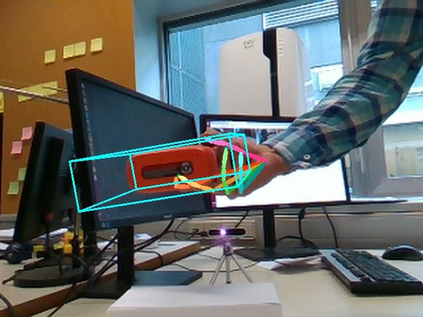
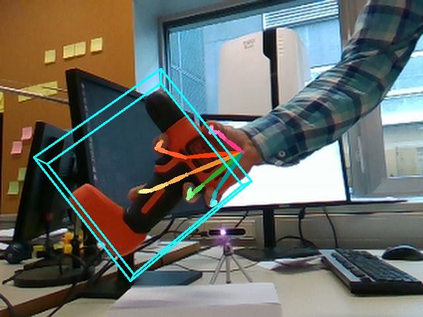
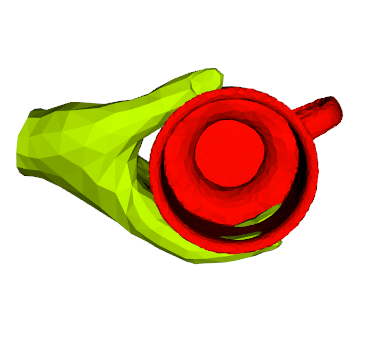
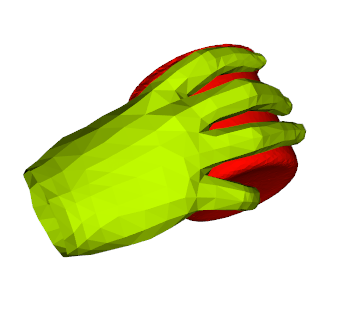
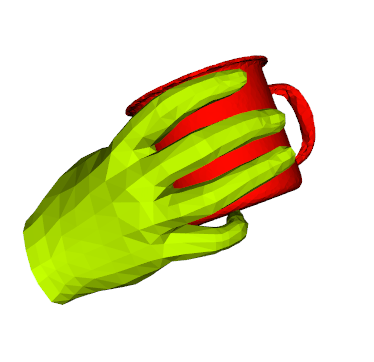
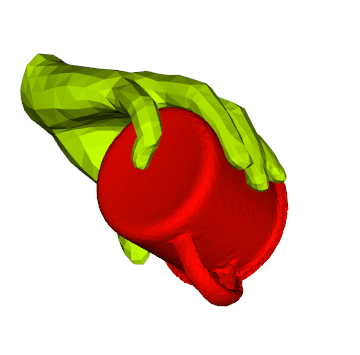
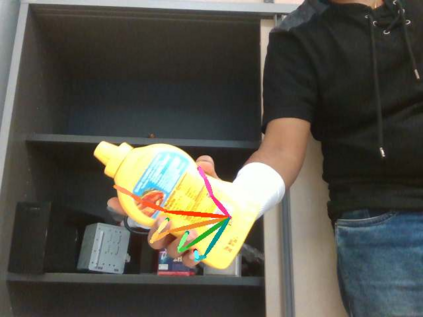
We propose a method for annotating images of a hand manipulating an object with the 3D poses of both the hand and the object, together with a dataset created using this method. There is a current lack of annotated real images for this problem, as estimating the 3D poses is challenging, mostly because of the mutual occlusions between the hand and the object. To tackle this challenge, we capture sequences with one or several RGB-D cameras, and jointly optimizes the 3D hand and object poses over all the frames simultaneously. This method allows us to automatically annotate each frame with accurate estimates of the poses, despite large mutual occlusions. With this method, we created HO-3D, the first markerless dataset of color images with 3D annotations of both hand and object. This dataset is currently made of 80,000 frames, 65 sequences, 10 persons, and 10 objects, and growing. We also use it to train a deepnet to perform RGB-based single frame hand pose estimation and provide a baseline on our dataset.
翻译:我们建议一种方法来说明手动操纵物体的3D形状的图像,以及使用此方法创建的数据集。目前缺乏这一问题的附加说明的真实图像,因为估计3D姿势具有挑战性,主要是因为手与物体之间相互隔绝。为了应对这一挑战,我们用一个或几个 RGB-D 相机来捕捉序列,同时将3D 手和物体的配置优化到所有框架。这种方法使我们能够自动为每个框架作说明,准确估计其姿势,尽管存在大量相互隔离现象。我们用这种方法创建了HO-3D,这是第一个带有手和物体3D说明的颜色图像无标记数据集。这个数据集目前由80 000个框架、65个序列、10个人和10个对象组成,并不断增长。我们还利用它来训练一个深网来进行基于 RGB 的单框架手的估算,并提供我们数据集的基线。