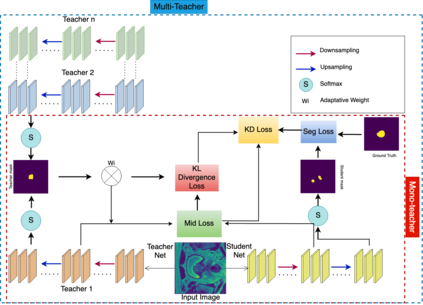
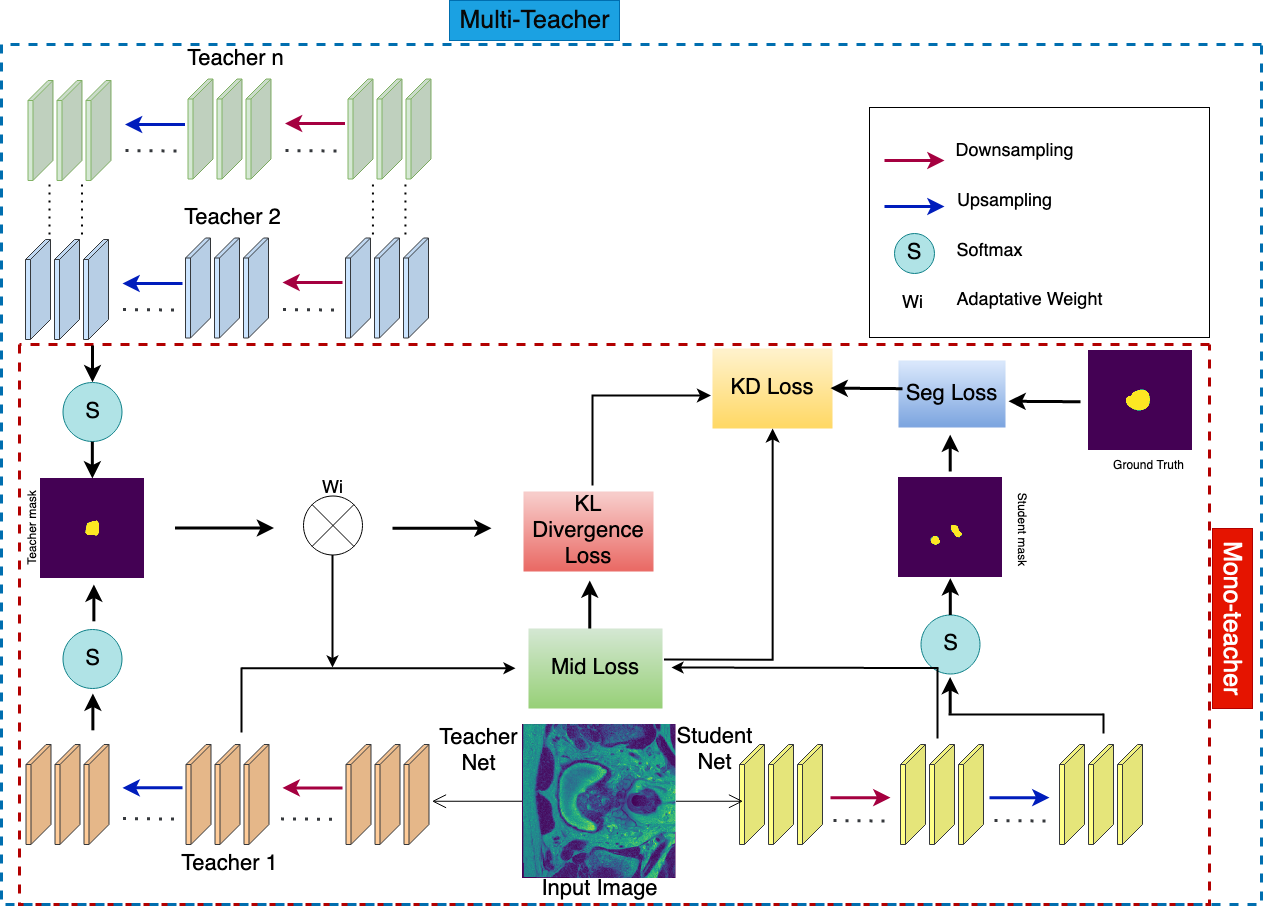
With numerous medical tasks, the performance of deep models has recently experienced considerable improvements. These models are often adept learners. Yet, their intricate architectural design and high computational complexity make deploying them in clinical settings challenging, particularly with devices with limited resources. To deal with this issue, Knowledge Distillation (KD) has been proposed as a compression method and an acceleration technology. KD is an efficient learning strategy that can transfer knowledge from a burdensome model (i.e., teacher model) to a lightweight model (i.e., student model). Hence we can obtain a compact model with low parameters with preserving the teacher's performance. Therefore, we develop a KD-based deep model for prostate MRI segmentation in this work by combining features-based distillation with Kullback-Leibler divergence, Lovasz, and Dice losses. We further demonstrate its effectiveness by applying two compression procedures: 1) distilling knowledge to a student model from a single well-trained teacher, and 2) since most of the medical applications have a small dataset, we train multiple teachers that each one trained with a small set of images to learn an adaptive student model as close to the teachers as possible considering the desired accuracy and fast inference time. Extensive experiments were conducted on a public multi-site prostate tumor dataset, showing that the proposed adaptation KD strategy improves the dice similarity score by 9%, outperforming all tested well-established baseline models.
翻译:在许多医学任务中,深度模型的性能最近经历了相当大的提高。这些模型通常是熟练的学习者。然而,它们复杂的架构设计和高计算复杂度使得在临床设置中部署它们具有挑战性,特别是对于资源有限的设备。为了解决这个问题,知识蒸馏(KD)被提出作为压缩方法和加速技术。KD是一种有效的学习策略,可以从一个复杂的模型(即教师模型)转移知识到一个轻型模型(即学生模型)。因此,我们可以获得具有低参数的紧凑型模型,同时保持教师的性能。因此,我们在这项工作中开发了一种基于KD的前列腺MRI分割深度模型,通过将基于特征的蒸馏与KL散度、Loavsz和Dice损失相结合来实现。我们进一步演示了它的有效性,通过应用两种压缩过程:1)从单个经过良好训练的教师中向学生模型蒸馏知识,2)由于大多数医疗应用的数据集很小,我们训练多个教师,每个教师使用少量图像进行训练,以尽可能接近教师的自适应学生模型,考虑所需的准确性和快速推理时间。在公共的多中心前列腺肿瘤数据集上进行了广泛的实验,结果表明所提出的自适应KD策略将Dice相似度得分提高了9%,优于所有测试的成熟基线模型。