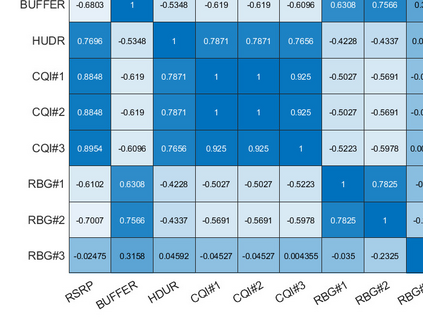
User scheduling is a classical problem and key technology in wireless communication, which will still plays an important role in the prospective 6G. There are many sophisticated schedulers that are widely deployed in the base stations, such as Proportional Fairness (PF) and Round-Robin Fashion (RRF). It is known that the Opportunistic (OP) scheduling is the optimal scheduler for maximizing the average user data rate (AUDR) considering the full buffer traffic. But the optimal strategy achieving the highest fairness still remains largely unknown both in the full buffer traffic and the bursty traffic. In this work, we investigate the problem of fairness-oriented user scheduling, especially for the RBG allocation. We build a user scheduler using Multi-Agent Reinforcement Learning (MARL), which conducts distributional optimization to maximize the fairness of the communication system. The agents take the cross-layer information (e.g. RSRP, Buffer size) as state and the RBG allocation result as action, then explore the optimal solution following a well-defined reward function designed for maximizing fairness. Furthermore, we take the 5%-tile user data rate (5TUDR) as the key performance indicator (KPI) of fairness, and compare the performance of MARL scheduling with PF scheduling and RRF scheduling by conducting extensive simulations. And the simulation results show that the proposed MARL scheduling outperforms the traditional schedulers.
翻译:用户排期是一个典型的问题,也是无线通信方面的关键技术,在未来的6G中仍将发挥重要作用。许多复杂的排期安排在基地站中广泛部署,例如比例公平(PF)和圆环罗滨时装(RRF)。众所周知,机会时间安排是最大限度地提高平均用户数据率(AUDR)的最佳排期安排,考虑到整个缓冲交通,但实现最高公平的最佳战略在全面缓冲交通和交通阻塞方面仍然基本上不为人所知。在这项工作中,我们调查了以公平为导向的用户排期安排问题,特别是在RBG分配方面。我们利用多动强化学习(MARL)建立一个用户排期安排,进行分配优化,以最大限度地提高通信系统的公平性。代理商将跨层信息(如RSRRPR、Buffer大小)作为州和RBG分配结果,然后探索在为尽可能实现公平而定义明确的奖赏功能之后的最佳解决办法。此外,我们以5%的用户排期数据率(5TUDRDR)为用户排期安排,将MRRF的模拟列表表作为主要业绩指标的模拟列表,并比较MRRRRFR的模拟列表。