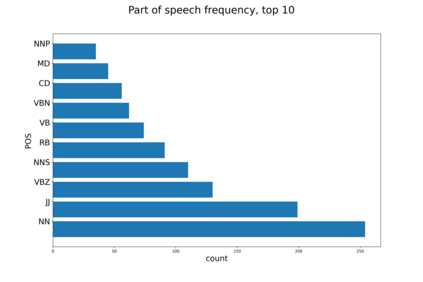
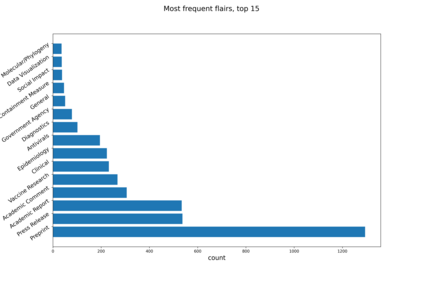
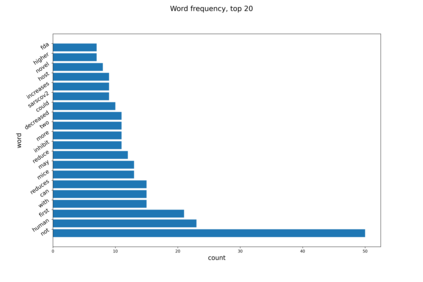
We introduce a FEVER-like dataset COVID-Fact of $4,086$ claims concerning the COVID-19 pandemic. The dataset contains claims, evidence for the claims, and contradictory claims refuted by the evidence. Unlike previous approaches, we automatically detect true claims and their source articles and then generate counter-claims using automatic methods rather than employing human annotators. Along with our constructed resource, we formally present the task of identifying relevant evidence for the claims and verifying whether the evidence refutes or supports a given claim. In addition to scientific claims, our data contains simplified general claims from media sources, making it better suited for detecting general misinformation regarding COVID-19. Our experiments indicate that COVID-Fact will provide a challenging testbed for the development of new systems and our approach will reduce the costs of building domain-specific datasets for detecting misinformation.
翻译:我们采用了一种类似于FEWL的数据数据集COVID-Fact, 共4 086美元的COVID-19大流行索赔,该数据集包含索赔要求、索赔证据和被证据反驳的自相矛盾的索赔要求,与以往的做法不同,我们自动发现真实的索赔要求及其来源文章,然后使用自动方法而不是使用人工标示器提出反索赔要求。我们与我们建造的资源一道,正式提出查明索赔要求的有关证据的任务,核实证据是否反驳或支持某一索赔要求。除了科学索赔要求外,我们的数据还包含来自媒体的简化的一般索赔要求,使之更适合发现有关COVID-19的一般错误信息。我们的实验表明,COVID-Fact将为开发新系统提供一个具有挑战性的检验台,我们的方法将降低为发现错误信息而建立特定领域的数据集的费用。