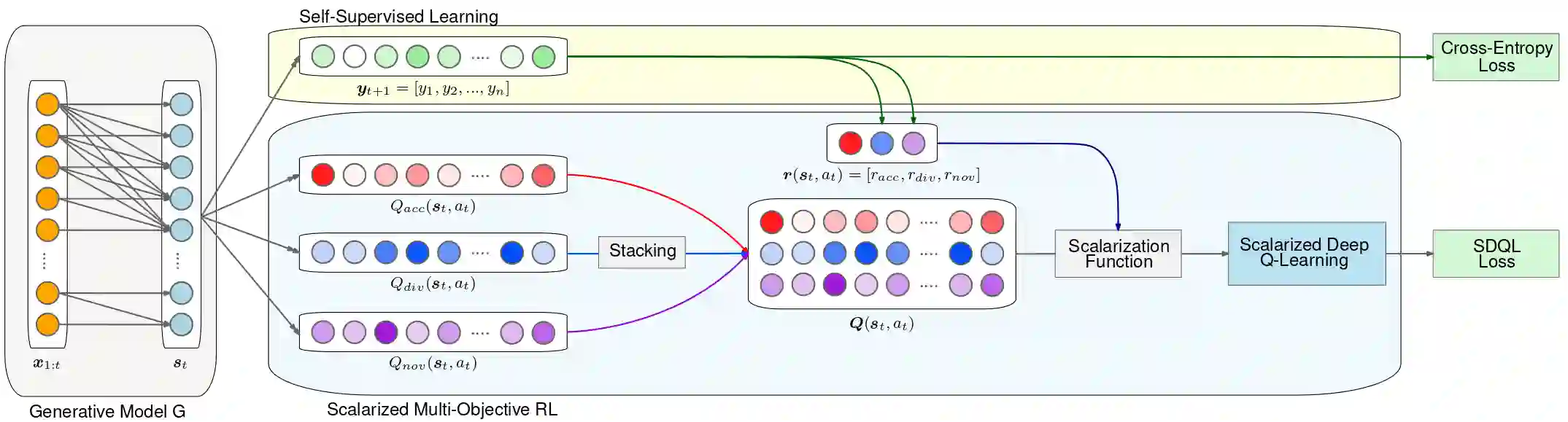
Since the inception of Recommender Systems (RS), the accuracy of the recommendations in terms of relevance has been the golden criterion for evaluating the quality of RS algorithms. However, by focusing on item relevance, one pays a significant price in terms of other important metrics: users get stuck in a "filter bubble" and their array of options is significantly reduced, hence degrading the quality of the user experience and leading to churn. Recommendation, and in particular session-based/sequential recommendation, is a complex task with multiple - and often conflicting objectives - that existing state-of-the-art approaches fail to address. In this work, we take on the aforementioned challenge and introduce Scalarized Multi-Objective Reinforcement Learning (SMORL) for the RS setting, a novel Reinforcement Learning (RL) framework that can effectively address multi-objective recommendation tasks. The proposed SMORL agent augments standard recommendation models with additional RL layers that enforce it to simultaneously satisfy three principal objectives: accuracy, diversity, and novelty of recommendations. We integrate this framework with four state-of-the-art session-based recommendation models and compare it with a single-objective RL agent that only focuses on accuracy. Our experimental results on two real-world datasets reveal a substantial increase in aggregate diversity, a moderate increase in accuracy, reduced repetitiveness of recommendations, and demonstrate the importance of reinforcing diversity and novelty as complementary objectives.
翻译:自建议系统(RS)建立以来,建议的相关性的准确性一直是评估RS算法质量的黄金标准,然而,通过注重项目相关性,我们为其他重要指标付出了巨大代价:用户被困在“过滤泡沫”中,其选择范围大为减少,从而降低了用户经验的质量,导致出现麻烦。建议,特别是基于届会/顺序的建议,是一项复杂的任务,现有最先进的方法未能解决多重——而且往往是相互冲突的目标。在这项工作中,我们迎接上述挑战,为RS设置采用升级化多目标强化学习(SMORL),采用新的强化学习(RL)框架,以有效解决多目标建议任务。拟议的SMORL代理机构将标准建议模式扩大,增加RL层次,使之同时满足三大主要目标:准确性、多样性和新颖性建议。我们将这一框架与四个基于最先进的会议建议模式结合起来,为RS设定了升级的多目标(SMMRL), 将一个新的强化性多目标(SMRL) 的精确性(SB) 与一个更精确性的单一指标性(SAL) ) 对比性(OUL) 性(SUL) 的精确性(OUL) 仅能展示性) 提高的精确性(OUL) 和真实性(OUL) 核心性(OIL) 核心性(OI) 核心性) ) 目标性(仅性) 对比性) 的精确性(OI) 的精确性(B) 的精确性(仅注重性(仅显示) 性) 的精确性) 。