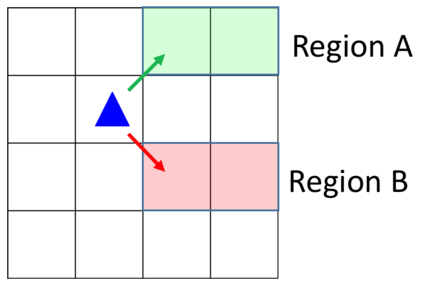
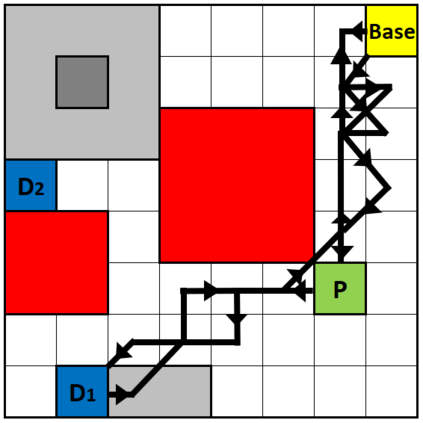
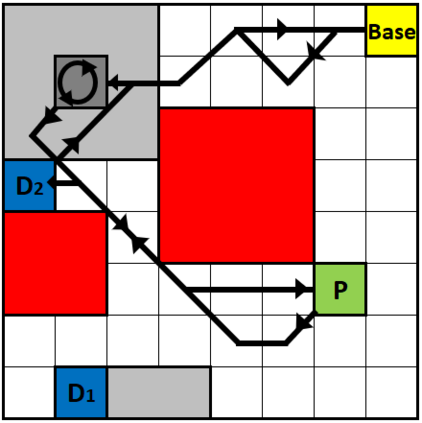
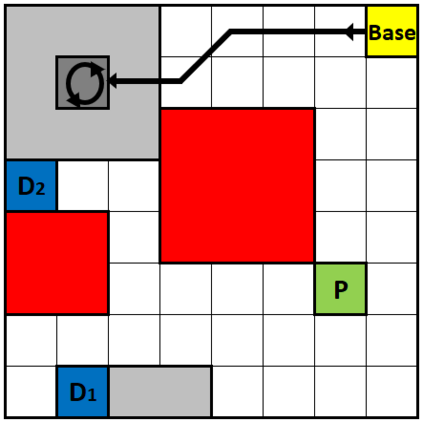
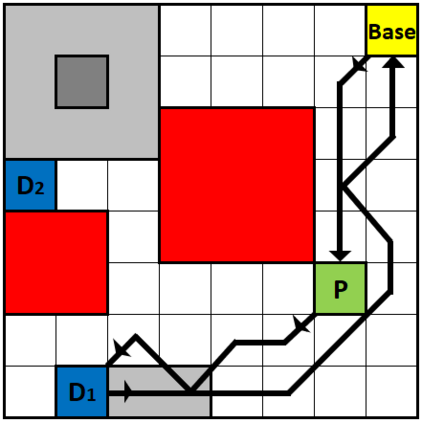
We present a novel reinforcement learning algorithm for finding optimal policies in Markov Decision Processes while satisfying temporal logic constraints with a desired probability throughout the learning process. An automata-theoretic approach is proposed to ensure probabilistic satisfaction of the constraint in each episode, which is different from penalizing violations to achieve constraint satisfaction after a sufficiently large number of episodes. The proposed approach is based on computing a lower bound on the probability of constraint satisfaction and adjusting the exploration behavior as needed. We present theoretical results on the probabilistic constraint satisfaction achieved by the proposed approach. We also numerically demonstrate the proposed idea in a drone scenario, where the constraint is to perform periodically arriving pick-up and delivery tasks and the objective is to fly over high-reward zones to simultaneously perform aerial monitoring.
翻译:我们提出了一个新的强化学习算法,用于在Markov决定程序中寻找最佳政策,同时满足时间逻辑限制,在整个学习过程中达到理想的概率。我们提议采用自成一体的理论方法,以确保每个事件都能够顺利地满足限制,这不同于惩罚违规行为,以便在足够多的事件发生后达到约束性满足。我们提议的方法基于较低的约束性满意度约束度,并根据需要调整勘探行为。我们提出了关于拟议方法实现的概率性约束性满意度的理论结果。我们还从数字上展示了无人机情景中的拟议想法,其中的限制是定期完成接收和交付任务,目标是飞越高纬度区域,同时进行空中监测。