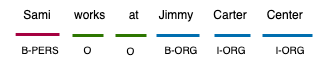
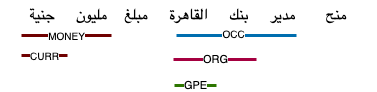
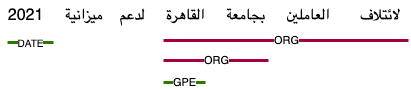
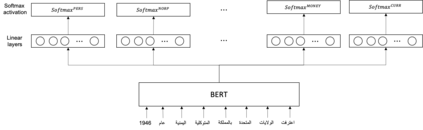
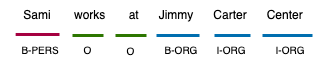
This paper presents Wojood, a corpus for Arabic nested Named Entity Recognition (NER). Nested entities occur when one entity mention is embedded inside another entity mention. Wojood consists of about 550K Modern Standard Arabic (MSA) and dialect tokens that are manually annotated with 21 entity types including person, organization, location, event and date. More importantly, the corpus is annotated with nested entities instead of the more common flat annotations. The data contains about 75K entities and 22.5% of which are nested. The inter-annotator evaluation of the corpus demonstrated a strong agreement with Cohen's Kappa of 0.979 and an F1-score of 0.976. To validate our data, we used the corpus to train a nested NER model based on multi-task learning and AraBERT (Arabic BERT). The model achieved an overall micro F1-score of 0.884. Our corpus, the annotation guidelines, the source code and the pre-trained model are publicly available.
翻译:本文展示了Wojood, 阿拉伯嵌套命名实体识别(NER) 。 当一个实体提到某个实体时, 就会出现堆积实体 。 Wojood 由大约550K 现代阿拉伯文标准(MSA)和方言符号组成, 上面有21个实体类型, 包括个人、 组织、 地点、 事件和日期, 手动加注, 更重要的是, 文中加注的是嵌套实体, 而不是更常见的平面说明 。 数据包含大约 75K 个实体, 其中22.5% 被嵌套。 对堆积实体的评估显示, 与科恩的Kappa 的 0. 97979 和 F1 标码的 F1 0.976 达成强烈协议 。 为了验证我们的数据, 我们利用这个平台培训一个基于多任务学习和 AraBERT 的嵌嵌套净模型。 该模型实现了0.884 总体的微型F1 核心。 我们的体、 指南、 源代码和预培训模型可以公开查阅 。