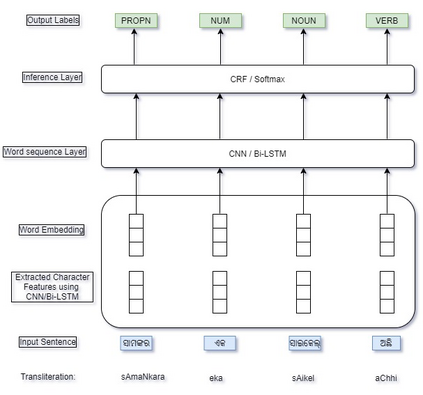
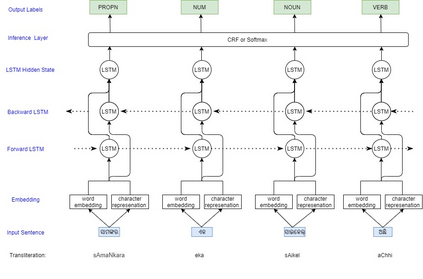
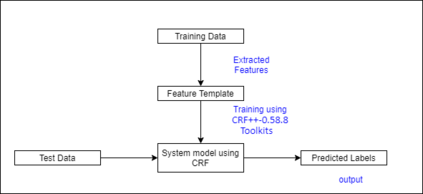
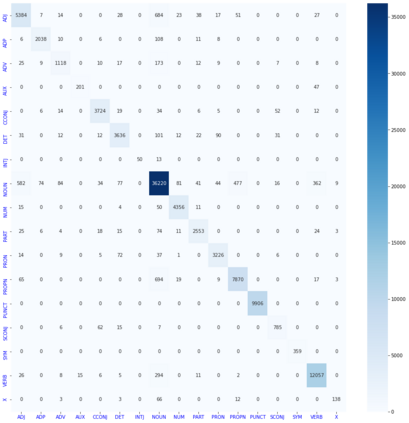
Automatic Part-of-speech (POS) tagging is a preprocessing step of many natural language processing (NLP) tasks such as name entity recognition (NER), speech processing, information extraction, word sense disambiguation, and machine translation. It has already gained a promising result in English and European languages, but in Indian languages, particularly in Odia language, it is not yet well explored because of the lack of supporting tools, resources, and morphological richness of language. Unfortunately, we were unable to locate an open source POS tagger for Odia, and only a handful of attempts have been made to develop POS taggers for Odia language. The main contribution of this research work is to present a conditional random field (CRF) and deep learning-based approaches (CNN and Bidirectional Long Short-Term Memory) to develop Odia part-of-speech tagger. We used a publicly accessible corpus and the dataset is annotated with the Bureau of Indian Standards (BIS) tagset. However, most of the languages around the globe have used the dataset annotated with Universal Dependencies (UD) tagset. Hence, to maintain uniformity Odia dataset should use the same tagset. So we have constructed a simple mapping from BIS tagset to UD tagset. We experimented with various feature set inputs to the CRF model, observed the impact of constructed feature set. The deep learning-based model includes Bi-LSTM network, CNN network, CRF layer, character sequence information, and pre-trained word vector. Character sequence information was extracted by using convolutional neural network (CNN) and Bi-LSTM network. Six different combinations of neural sequence labelling models are implemented, and their performance measures are investigated. It has been observed that Bi-LSTM model with character sequence feature and pre-trained word vector achieved a significant state-of-the-art result.
翻译:自动部分语音标记(POS)是许多自然语言处理任务(NLP)的预处理步骤,如名称实体识别(NER)、语音处理、信息提取、字感突变和机器翻译。在英语和欧洲语言方面已经取得了令人乐观的结果,但在印度语言方面,特别是在Odia语言方面,由于缺少辅助工具、资源和语言的形态丰富,该标记尚未得到充分探讨。不幸的是,我们未能为Odia找到一个开放源源POS矢量计算器(NLP),而且只做了很少的尝试来为Odia语言开发POS深度标记器(NER)、语音处理、信息提取信息提取、字义感应显示一个有条件随机的字段(CRF)和基于深层次的学习方法(CNN和双向长短期内存)来开发Odia语部分。我们使用了一个公开的字元资料和数据元模型(BISLS)的模型(BILS),我们使用通用的轨迹标记(ODRI),我们使用一个相同的标记。