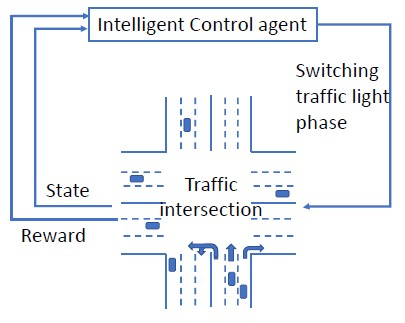
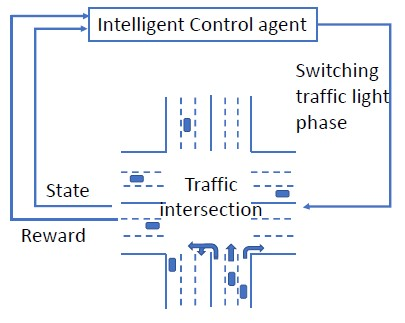
Intelligent traffic lights in smart cities can optimally reduce traffic congestion. In this study, we employ reinforcement learning to train the control agent of a traffic light on a simulator of urban mobility. As a difference from existing works, a policy-based deep reinforcement learning method, Proximal Policy Optimization (PPO), is utilized other than value-based methods such as Deep Q Network (DQN) and Double DQN (DDQN). At first, the obtained optimal policy from PPO is compared to those from DQN and DDQN. It is found that the policy from PPO performs better than the others. Next, instead of the fixed-interval traffic light phases, we adopt the light phases with variable time intervals, which result in a better policy to pass the traffic flow. Then, the effects of environment and action disturbances are studied to demonstrate the learning-based controller is robust. At last, we consider unbalanced traffic flows and find that an intelligent traffic light can perform moderately well for the unbalanced traffic scenarios, although it learns the optimal policy from the balanced traffic scenarios only.
翻译:智能城市的智能交通灯可以最佳地减少交通堵塞。 在这项研究中,我们利用强化学习来培训城市流动模拟器的交通灯控制剂。 作为与现有工程的区别,我们采用了基于政策的深强化学习方法,即Proximal政策优化(PPO),除了基于价值的方法之外,还使用了深Q网络(DQN)和双DQN(DDQN)等基于深Q的监控方法。首先,从PPPO获得的最佳政策比DQN和DDQN的政策要好。发现PPPO的政策比其他政策效果更好。 其次,我们采用不同时间间隔的固定交通灯阶段,采用不同的灯光相,从而形成更好的政策,以通过交通流量。然后,研究环境和行动干扰的影响,以证明基于学习的控制器是稳健的。最后,我们考虑到不平衡的交通流量,发现智能交通灯在不平衡的交通情景下可以产生中等效果,尽管它只从平衡的交通情景中学习了最佳政策。