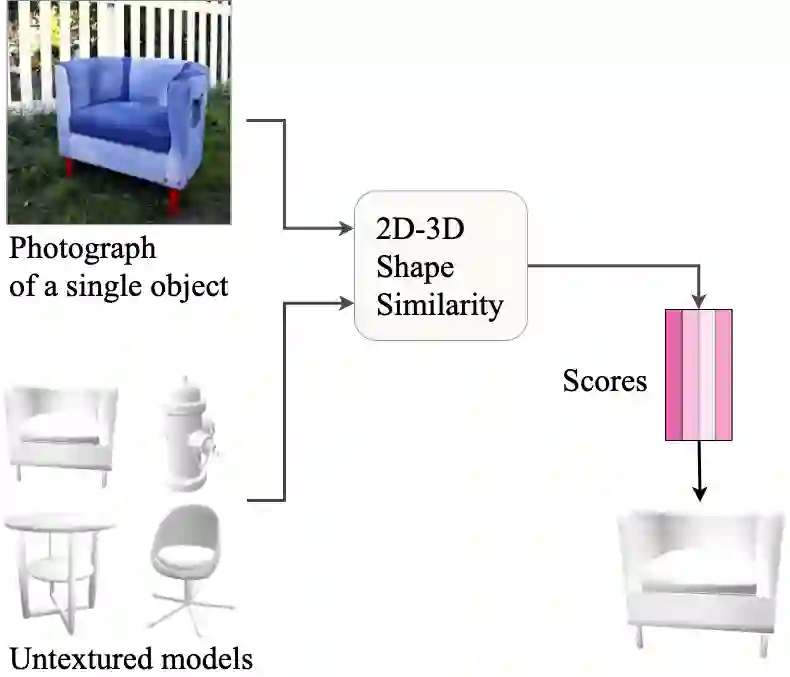
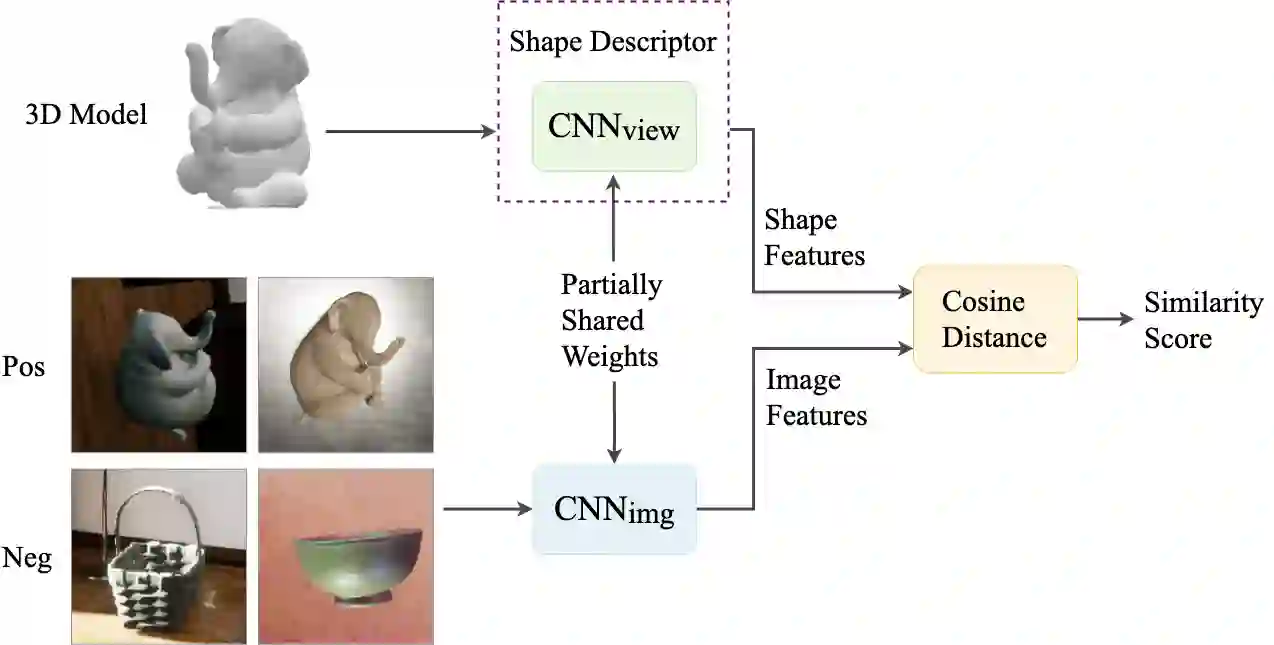
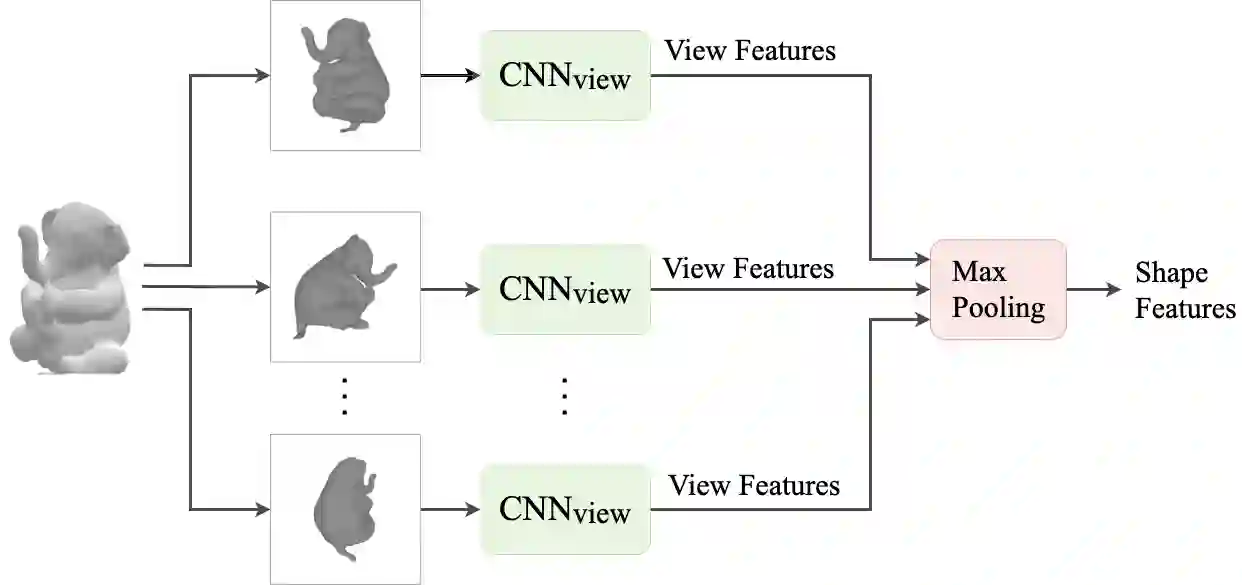
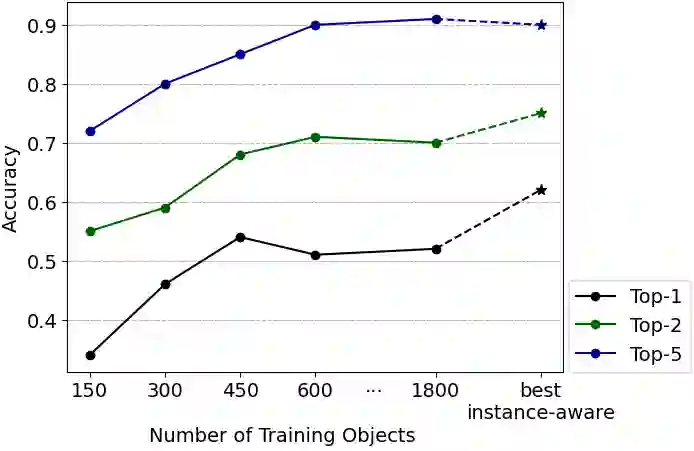
We present a network architecture which compares RGB images and untextured 3D models by the similarity of the represented shape. Our system is optimised for zero-shot retrieval, meaning it can recognise shapes never shown in training. We use a view-based shape descriptor and a siamese network to learn object geometry from pairs of 3D models and 2D images. Due to scarcity of datasets with exact photograph-mesh correspondences, we train our network with only synthetic data. Our experiments investigate the effect of different qualities and quantities of training data on retrieval accuracy and present insights from bridging the domain gap. We show that increasing the variety of synthetic data improves retrieval accuracy and that our system's performance in zero-shot mode can match that of the instance-aware mode, as far as narrowing down the search to the top 10% of objects.
翻译:我们展示了一个网络结构, 将 RGB 图像和未发文的 3D 模型与代表形状的相似性进行比较。 我们的系统为零发检索提供了优化, 意思是它能够识别在训练中从未显示的形状。 我们使用基于视觉的形状描述器和一个 Siamese 网络来从 3D 模型和 2D 图像的对等中学习对象的几何。 由于缺少带有精确照片- 图像通信的数据集, 我们只用合成数据来培训我们的网络。 我们的实验调查了不同质量和数量的培训数据对检索准确性的影响, 并展示了缩小域间距差距的洞察力。 我们显示, 增加合成数据的种类可以提高检索准确性, 我们系统在零发模式下的性能可以与实例- 觉模式的性能匹配性能, 从而将搜索缩小到最高10%的物体。