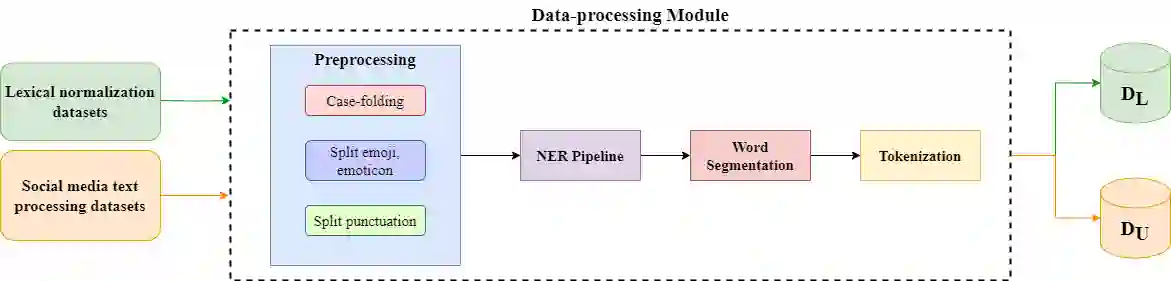
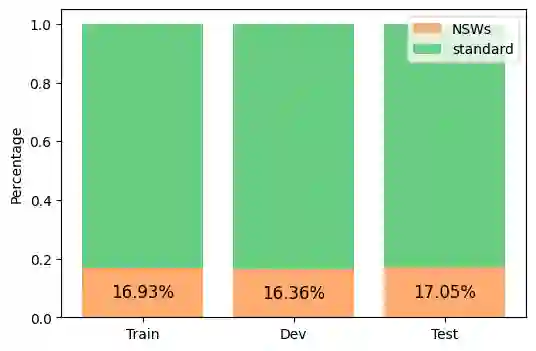
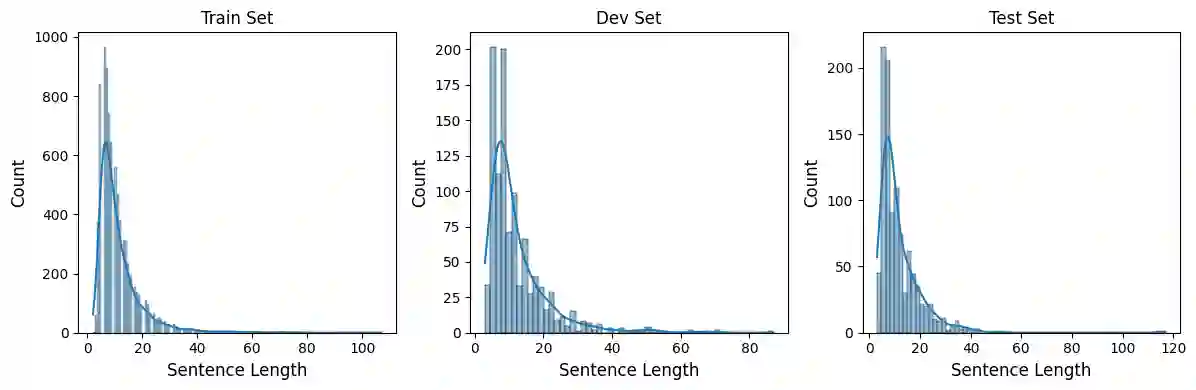
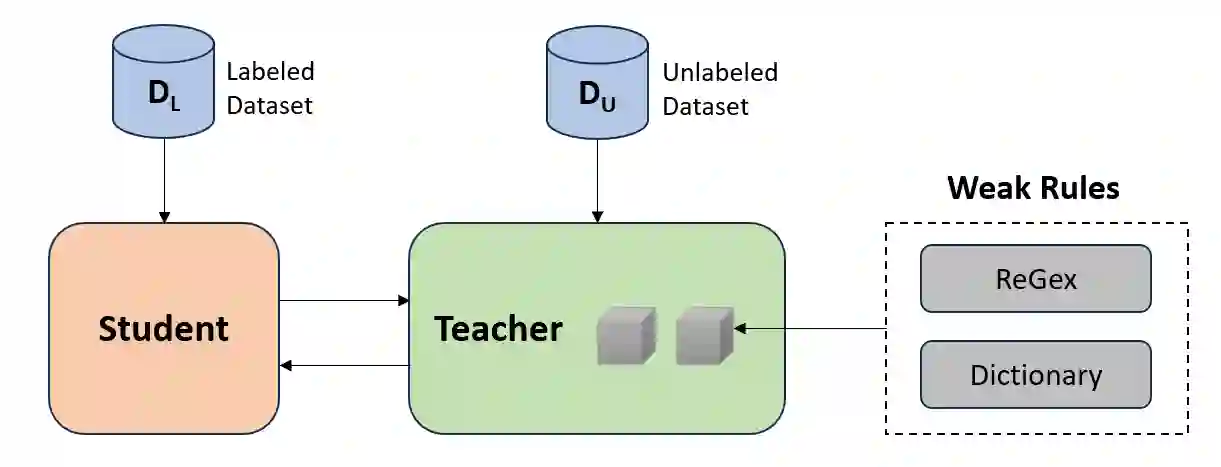
This study introduces an innovative automatic labeling framework to address the challenges of lexical normalization in social media texts for low-resource languages like Vietnamese. Social media data is rich and diverse, but the evolving and varied language used in these contexts makes manual labeling labor-intensive and expensive. To tackle these issues, we propose a framework that integrates semi-supervised learning with weak supervision techniques. This approach enhances the quality of training dataset and expands its size while minimizing manual labeling efforts. Our framework automatically labels raw data, converting non-standard vocabulary into standardized forms, thereby improving the accuracy and consistency of the training data. Experimental results demonstrate the effectiveness of our weak supervision framework in normalizing Vietnamese text, especially when utilizing Pre-trained Language Models. The proposed framework achieves an impressive F1-score of 82.72% and maintains vocabulary integrity with an accuracy of up to 99.22%. Additionally, it effectively handles undiacritized text under various conditions. This framework significantly enhances natural language normalization quality and improves the accuracy of various NLP tasks, leading to an average accuracy increase of 1-3%.
翻译:暂无翻译