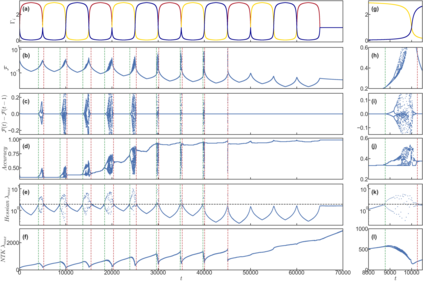
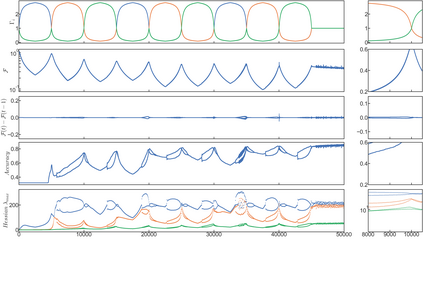
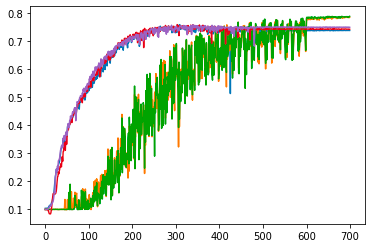
We show that learning can be improved by using loss functions that evolve cyclically during training to emphasize one class at a time. In underparameterized networks, such dynamical loss functions can lead to successful training for networks that fail to find a deep minima of the standard cross-entropy loss. In overparameterized networks, dynamical loss functions can lead to better generalization. Improvement arises from the interplay of the changing loss landscape with the dynamics of the system as it evolves to minimize the loss. In particular, as the loss function oscillates, instabilities develop in the form of bifurcation cascades, which we study using the Hessian and Neural Tangent Kernel. Valleys in the landscape widen and deepen, and then narrow and rise as the loss landscape changes during a cycle. As the landscape narrows, the learning rate becomes too large and the network becomes unstable and bounces around the valley. This process ultimately pushes the system into deeper and wider regions of the loss landscape and is characterized by decreasing eigenvalues of the Hessian. This results in better regularized models with improved generalization performance.
翻译:我们表明,通过使用培训过程中周期性演变的损失功能,可以提高学习质量,同时强调一个班级。在分界线不足的网络中,这种动态损失功能可以导致成功培训未能找到标准跨热带损失的深微粒的网络。在过分分界线的网络中,动态损失功能可以导致更好的概括化。由于不断变化的损失场景与系统动态的相互作用,随着系统的变化,将损失最小化。特别是,随着损失功能的振荡,不稳定性以双向级联的形式发展,我们研究如何使用赫森和尼苏尔唐南内尔的双向级联星。在地貌的山谷扩大和深化,然后随着周期中损失地貌的变化而缩小和上升。随着地貌的缩小,学习率变得过大,网络变得不稳定,在河谷周围反弹。这一过程最终将系统推向损失地貌的更深和更广的区域,其特征是赫斯山的精度下降。这导致更好的正规模型,其总体性得到改进。