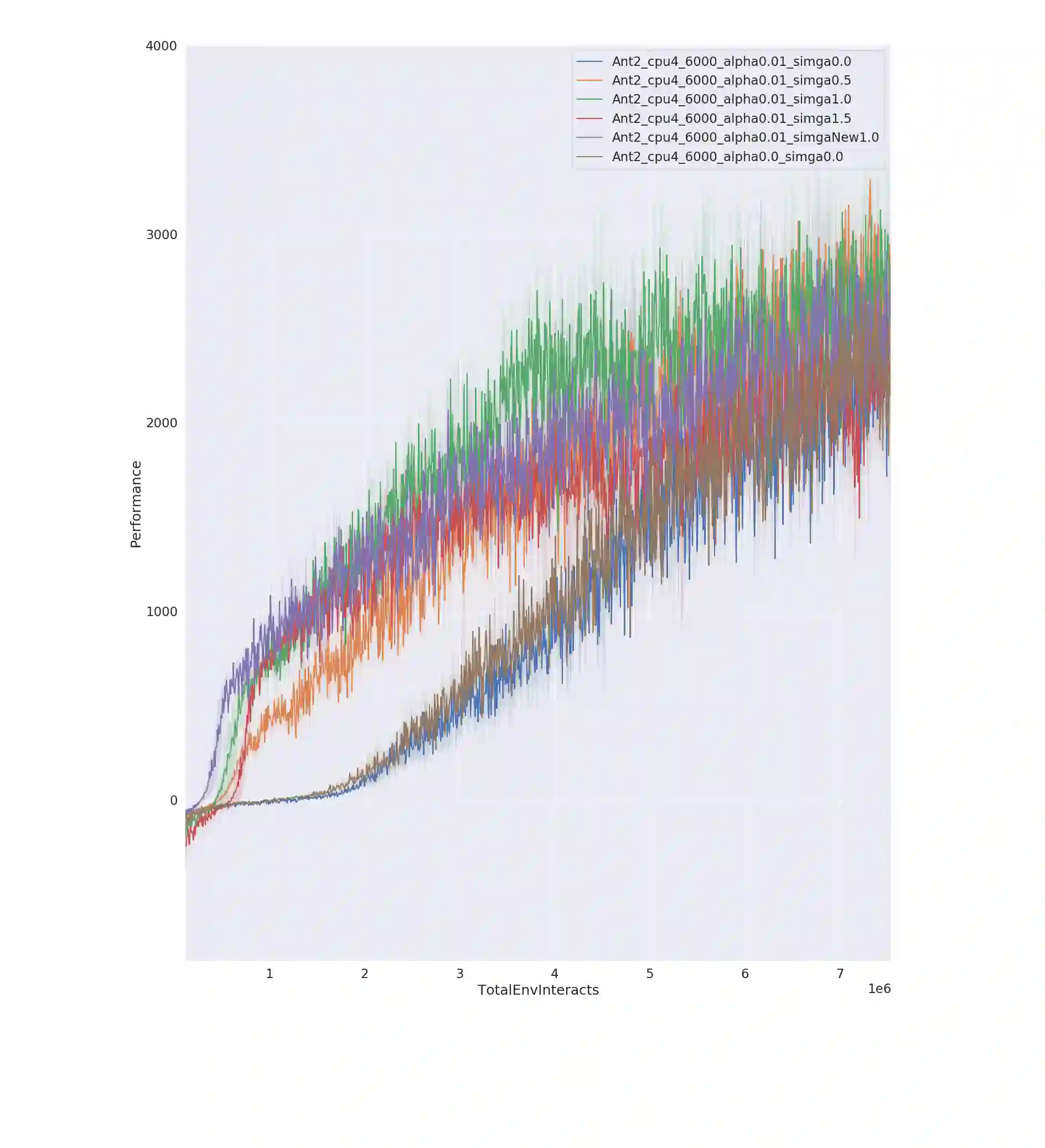
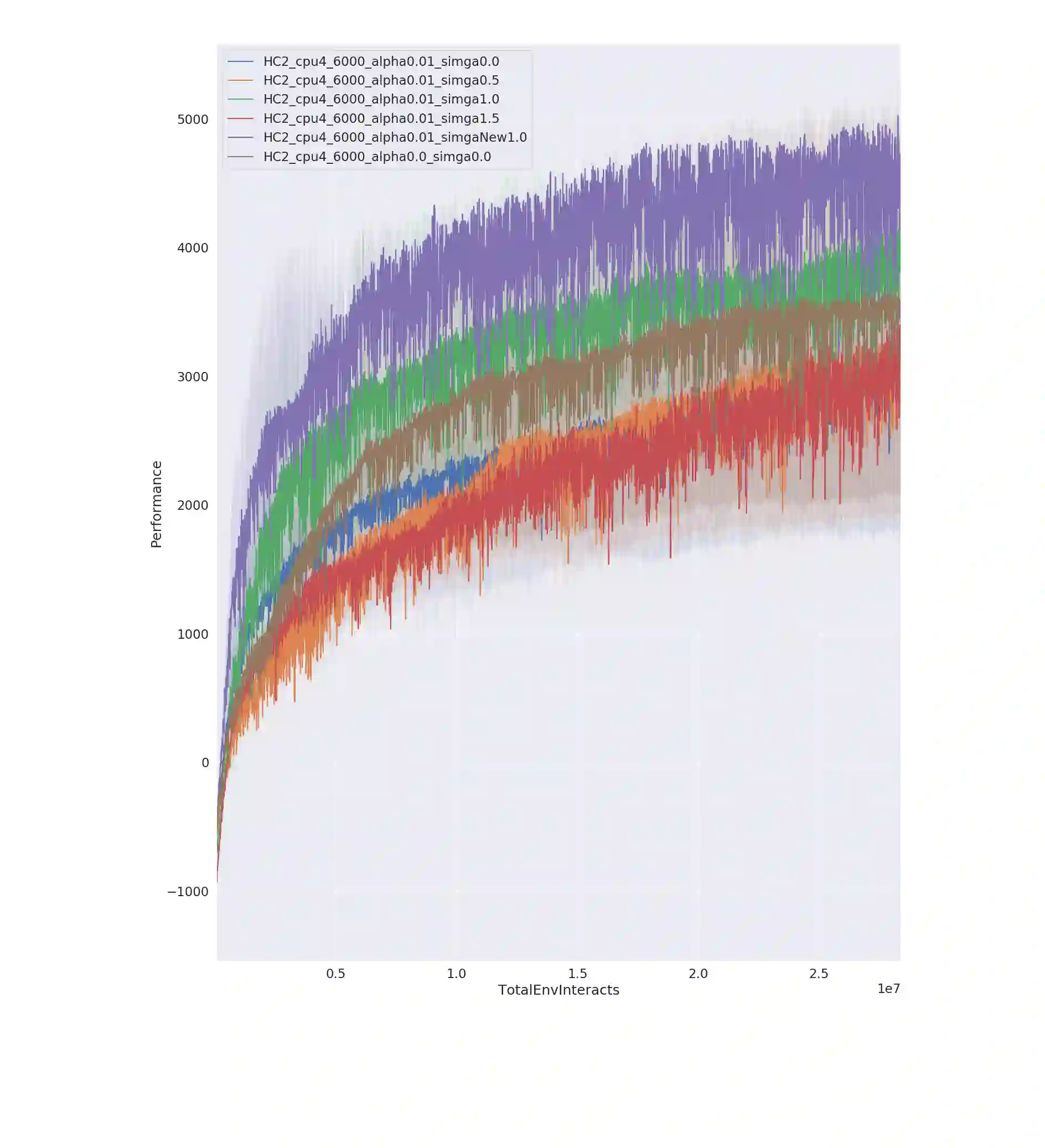
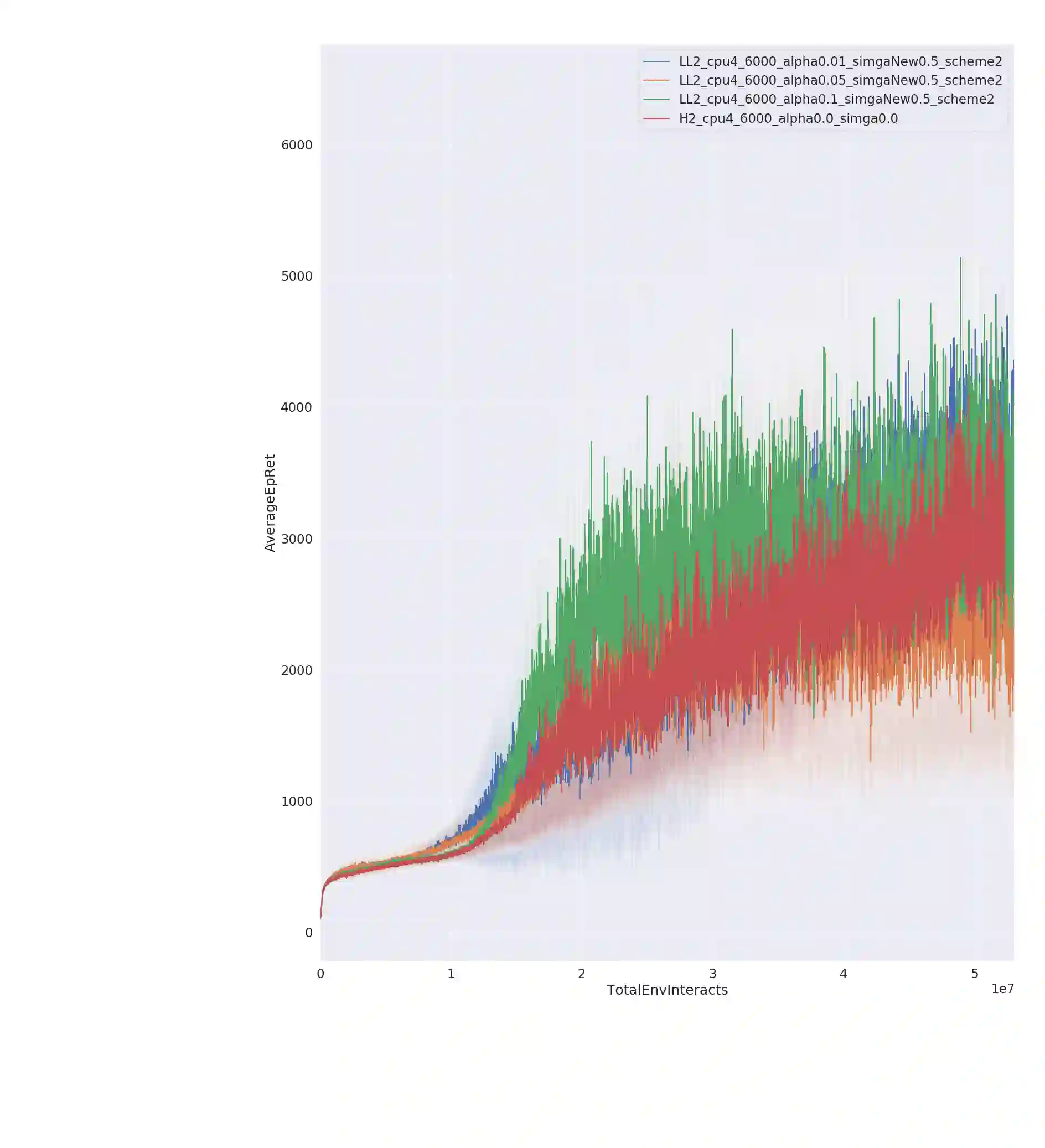
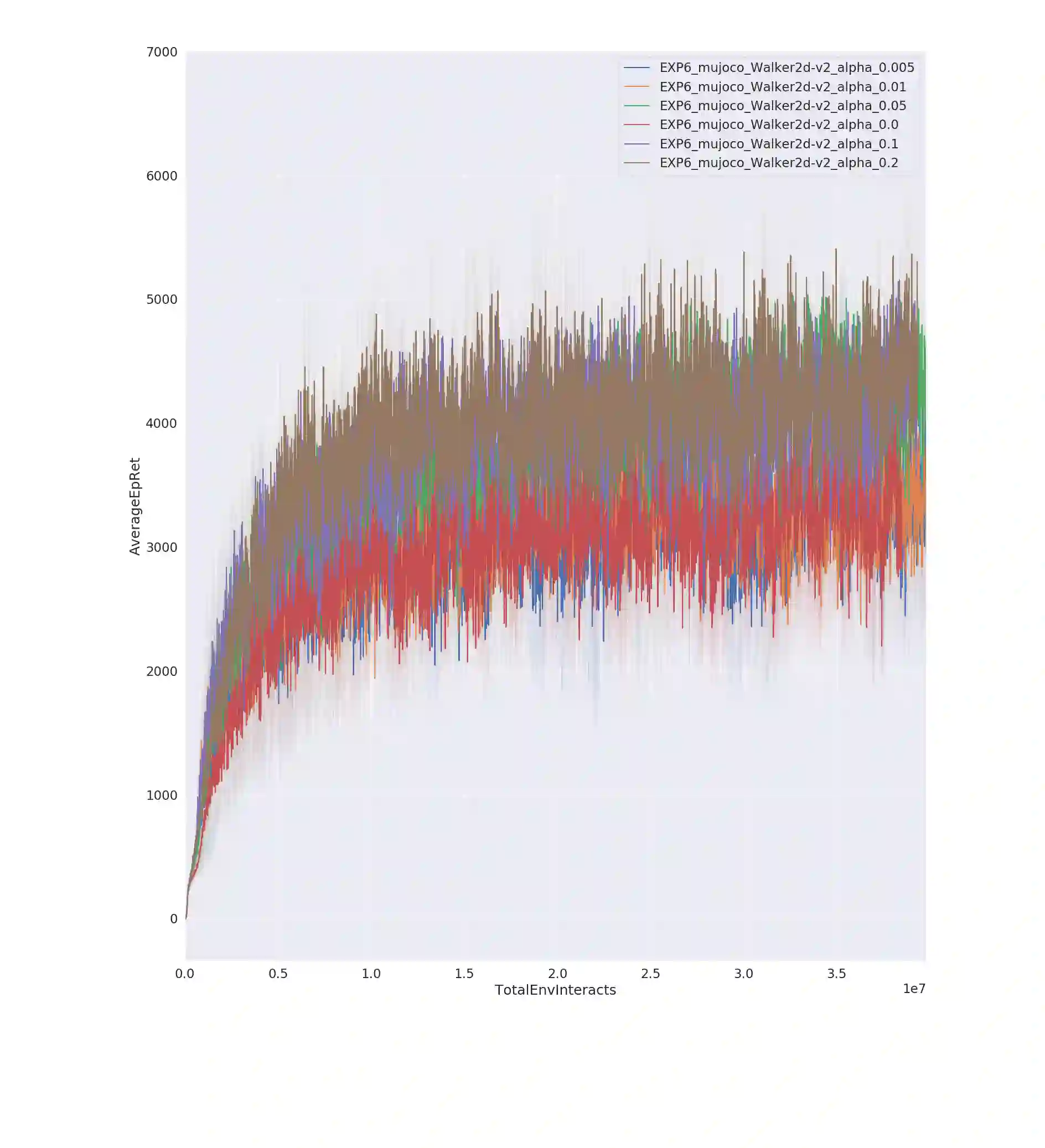
Entropy regularization is an imported idea in reinforcement learning, with great success in recent algorithms like Soft Actor Critic and Soft Q Network. In this work we extend this idea into the on-policy realm. With the soft gradient policy theorem, we construct the maximum entropy reinforcement learning framework for on-policy RL. For policy gradient based on-policy algorithms, policy network is often represented as Gaussian distribution with the action variance restricted to be global for all the states observed from the environment. We propose an idea called action variance scale for policy network and find it can work collaboratively with the idea of entropy regularization. In this paper, we choose the state-of-the-art on-policy algorithm, Proximal Policy Optimization, as our basal algorithm and present Soft Proximal Policy Optimization (SPPO). PPO is a popular on-policy RL algorithm with great stability and parallelism. But like many on-policy algorithm, PPO can also suffer from low sample efficiency and local optimum problem. In the entropy-regularized framework, SPPO can guide the agent to succeed at the task while maintaining exploration by acting as randomly as possible. Our method outperforms prior works on a range of continuous control benchmark tasks, Furthermore, our method can be easily extended to large scale experiment and achieve stable learning at high throughput.
翻译:在强化学习中,内装正规化是一个进口的理念,在Soft Actor Criptic 和Soft Q 网络等最近的算法中取得了巨大成功。 在这项工作中,我们将这一理念推广到政策领域。我们用软梯度政策理论,为政策RL构建了最大增殖框架。对于基于政策算法的政策梯度,政策网络通常以高斯分布为代表,其行动差异仅限于全球范围,从环境观察的所有国家。我们提出了一个想法,即政策网络需要行动差异表,并发现它可以与英特质正规化理念合作。在本文中,我们选择了最先进的政策算法、普罗克西玛政策优化化,作为我们的巴萨算法和目前的Soft Proximmal 政策优化化(SPPO) 。 PPO是一个受欢迎的政策RL算法,其稳定性和平行性很强。但是像许多政策算法一样,PPO也可以因低样本效率和当地最佳问题而受害。在加密框架中,我们选择了最先进的政策框架,我们的政策框架,我们选择了最先进的政策最先进的政策算法, Proximalimal Popal Popal Popolimporim Popal 可以指导我们一个长期的实验法, 通过一个成功的实验方法,在可能成功的实验方法,在可能完成一个高的实验方法, 的实验方法,通过一个成功的实验方法,通过一个成功的实验方法,通过一个成功的实验方法,然后在可能完成。