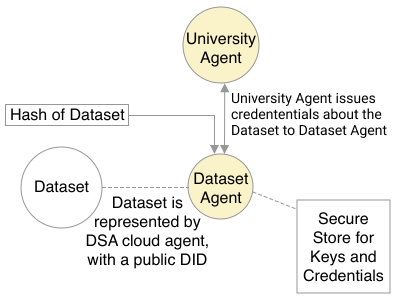
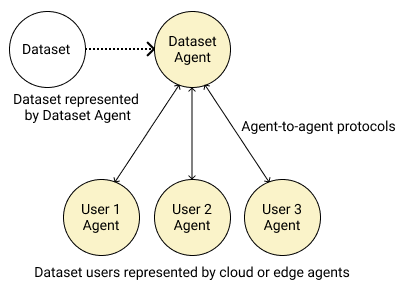
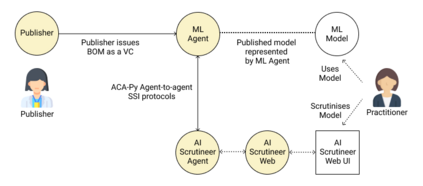
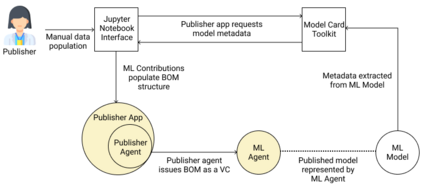
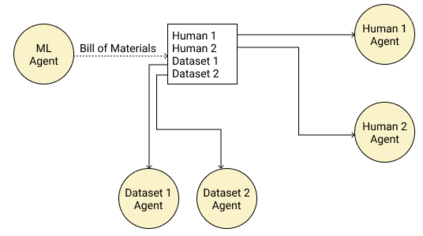
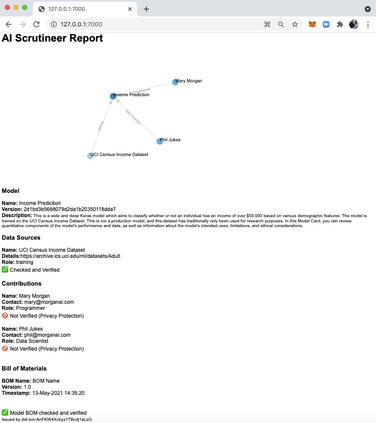
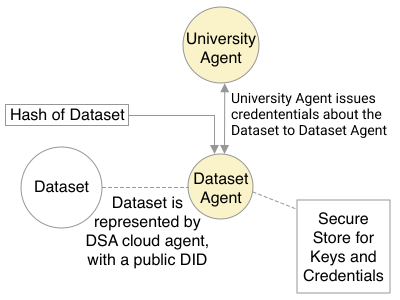
Adopting shared data resources requires scientists to place trust in the originators of the data. When shared data is later used in the development of artificial intelligence (AI) systems or machine learning (ML) models, the trust lineage extends to the users of the system, typically practitioners in fields such as healthcare and finance. Practitioners rely on AI developers to have used relevant, trustworthy data, but may have limited insight and recourse. This paper introduces a software architecture and implementation of a system based on design patterns from the field of self-sovereign identity. Scientists can issue signed credentials attesting to qualities of their data resources. Data contributions to ML models are recorded in a bill of materials (BOM), which is stored with the model as a verifiable credential. The BOM provides a traceable record of the supply chain for an AI system, which facilitates on-going scrutiny of the qualities of the contributing components. The verified BOM, and its linkage to certified data qualities, is used in the AI Scrutineer, a web-based tool designed to offer practitioners insight into ML model constituents and highlight any problems with adopted datasets, should they be found to have biased data or be otherwise discredited.
翻译:采用共享数据资源要求科学家信任数据发端人; 当共享数据后来用于开发人工智能系统或机器学习模型时,信任线将延伸到系统的用户,通常是医疗保健和金融等领域的从业人员。从业者依靠AI开发者使用了相关、可信赖的数据,但可能只有有限的洞察力和追索力。本文介绍了软件结构以及基于自我主权身份领域设计模式的系统的实施。科学家可以签发签名证书,以测试其数据资源的质量。数据对ML模型的贡献记录在一份材料清单(BOM)中,该清单与该模型一起储存,作为可核查的证明。BOM为AI系统提供了供应链的可追踪记录,该系统有助于不断检查贡献要素的质量。经核实的BOM及其与经认证的数据质量的联系,在AI Scrutiner中使用,这是一个基于网络的工具,旨在向从业者提供对ML模型成分的深入了解,并突出与所采纳的数据集存在的任何问题,如果发现它们具有偏差性,则会使其失去信誉。