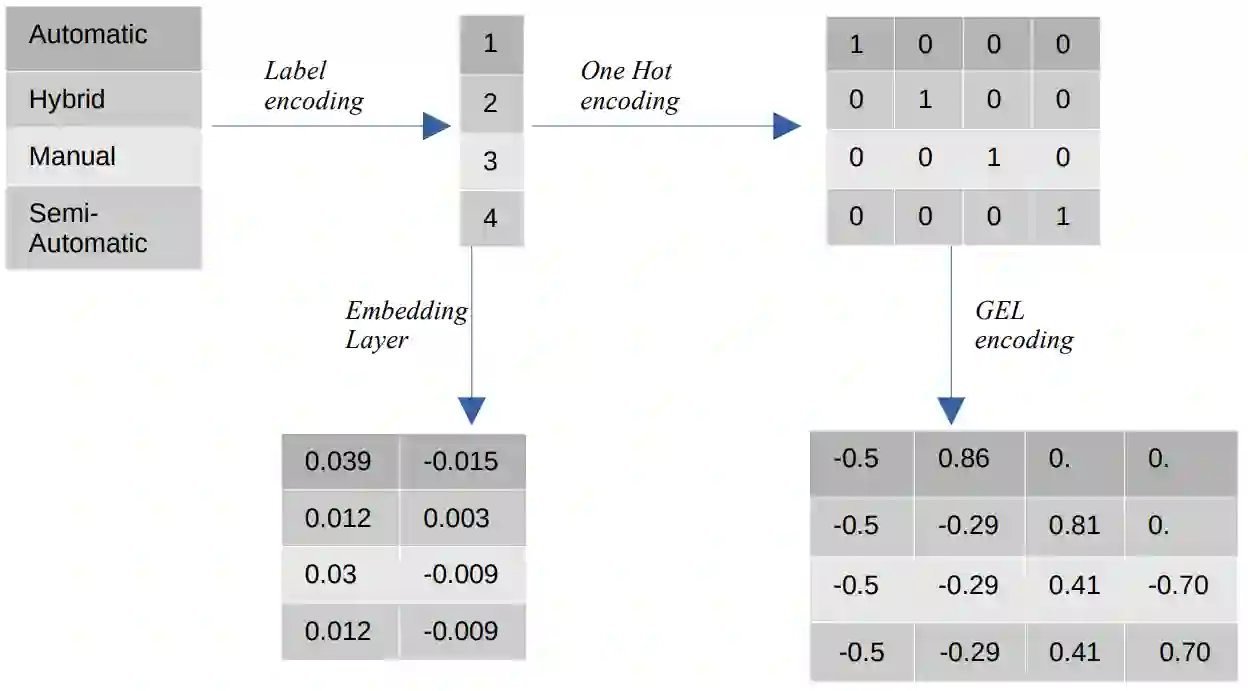
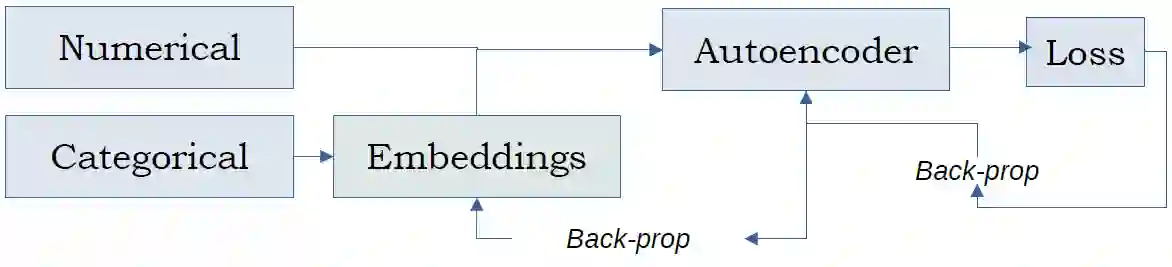
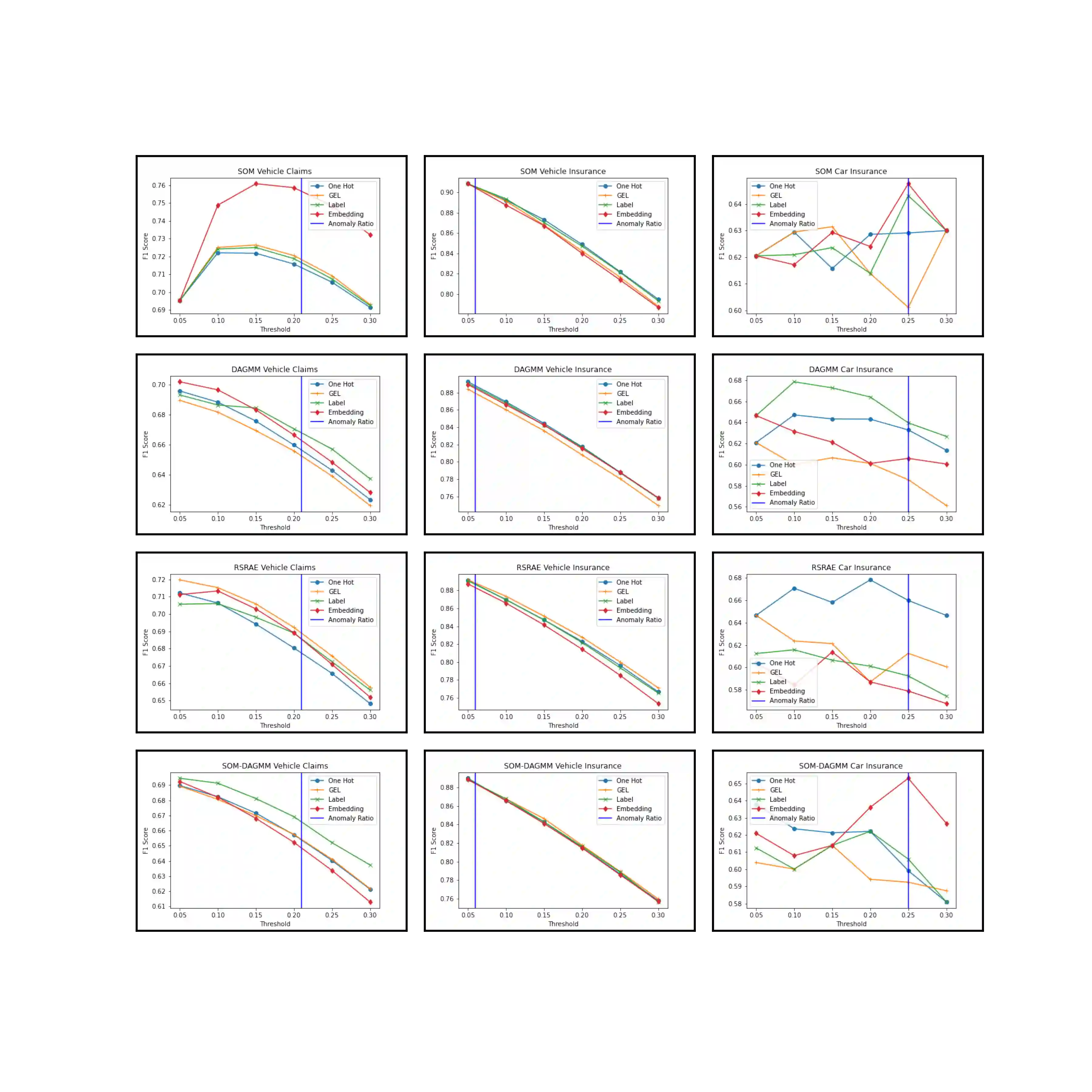
In this paper, we introduce the Vehicle Claims dataset, consisting of fraudulent insurance claims for automotive repairs. The data belongs to the more broad category of Auditing data, which includes also Journals and Network Intrusion data. Insurance claim data are distinctively different from other auditing data (such as network intrusion data) in their high number of categorical attributes. We tackle the common problem of missing benchmark datasets for anomaly detection: datasets are mostly confidential, and the public tabular datasets do not contain relevant and sufficient categorical attributes. Therefore, a large-sized dataset is created for this purpose and referred to as Vehicle Claims (VC) dataset. The dataset is evaluated on shallow and deep learning methods. Due to the introduction of categorical attributes, we encounter the challenge of encoding them for the large dataset. As One Hot encoding of high cardinal dataset invokes the "curse of dimensionality", we experiment with GEL encoding and embedding layer for representing categorical attributes. Our work compares competitive learning, reconstruction-error, density estimation and contrastive learning approaches for Label, One Hot, GEL encoding and embedding layer to handle categorical values.
翻译:在本文中,我们介绍车辆索赔数据集,由汽车修理保险欺诈性索赔组成。数据属于更广泛的审计数据类别,包括日记和网络入侵数据。保险索赔数据与其他审计数据(如网络入侵数据)有明显不同,因为它们具有大量绝对属性。我们处理的是为检测异常而缺少基准数据集这一共同问题:数据集大多是保密的,公开表格数据集并不包含相关和足够的绝对属性。因此,为此创建了一个大数据集,称为车辆索赔数据集。数据集是用浅深学习方法进行评估的。由于采用了绝对属性,我们面临为大型数据集编码这些数据的挑战。作为高红源数据集的一个热编码,我们用GEL编码和嵌入层进行实验,以代表绝对属性。我们的工作比较了拉贝尔(Label)、一个热、GEL编码和嵌入层的竞争性学习、重整、密度估计和对比学习方法,以便处理绝对值。