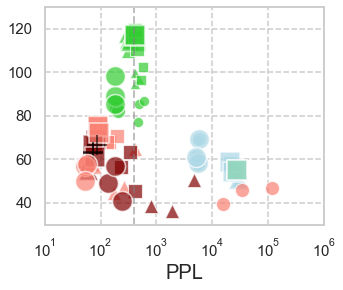
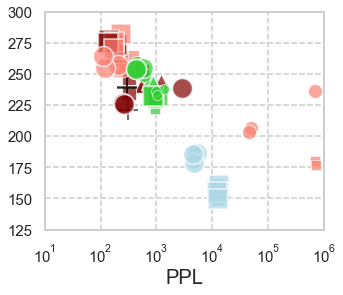
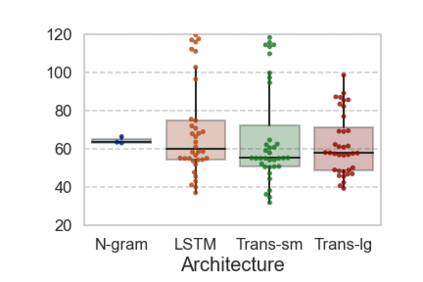
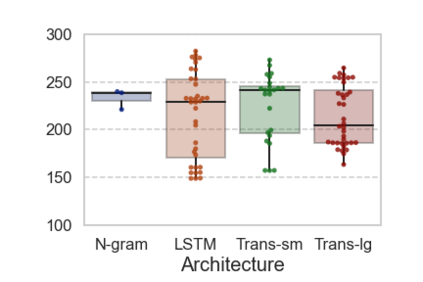
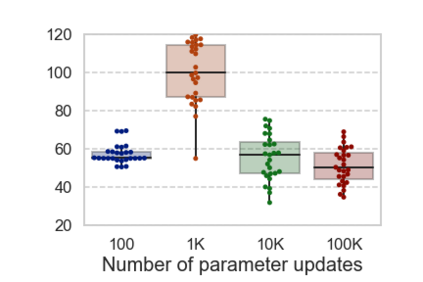
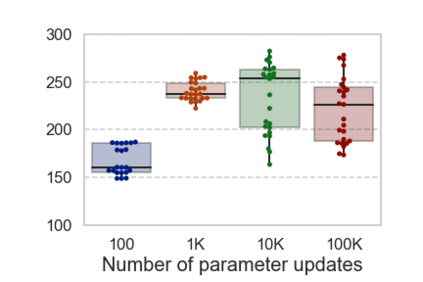
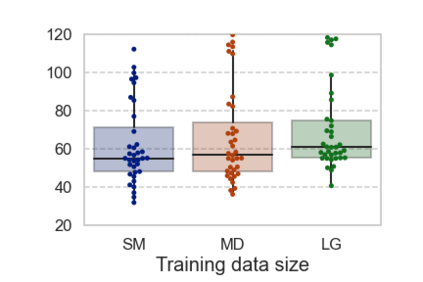
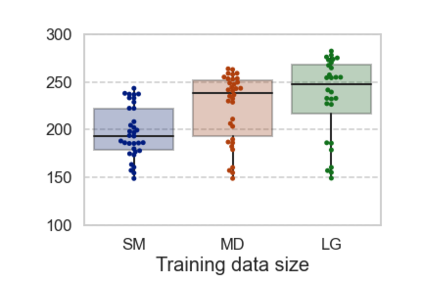
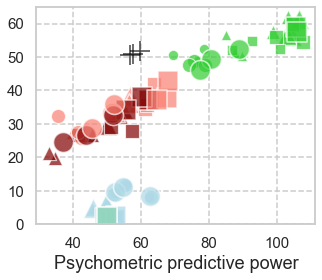
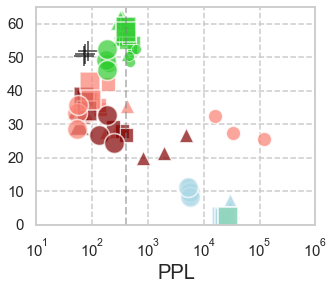
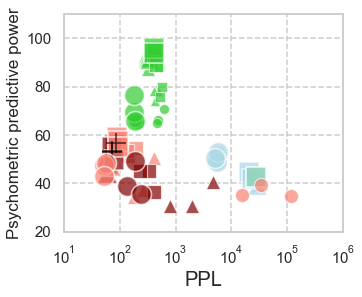
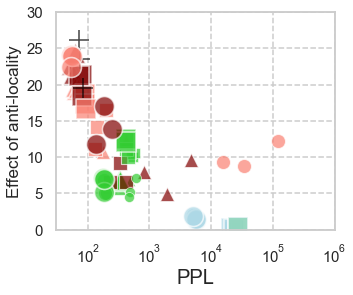
In computational psycholinguistics, various language models have been evaluated against human reading behavior (e.g., eye movement) to build human-like computational models. However, most previous efforts have focused almost exclusively on English, despite the recent trend towards linguistic universal within the general community. In order to fill the gap, this paper investigates whether the established results in computational psycholinguistics can be generalized across languages. Specifically, we re-examine an established generalization -- the lower perplexity a language model has, the more human-like the language model is -- in Japanese with typologically different structures from English. Our experiments demonstrate that this established generalization exhibits a surprising lack of universality; namely, lower perplexity is not always human-like. Moreover, this discrepancy between English and Japanese is further explored from the perspective of (non-)uniform information density. Overall, our results suggest that a cross-lingual evaluation will be necessary to construct human-like computational models.
翻译:在计算心理语言学中,针对人类阅读行为(例如眼睛运动),对各种语言模型进行了评估,以建立类似人类的计算模型;然而,尽管近来一般社区内出现了语言普遍化的趋势,但以往的多数努力几乎完全集中在英语上;为了填补这一空白,本文件调查了计算精神语言学的既定结果能否在各种语言之间普及。具体地说,我们重新审查了既定的概括性 -- -- 语言模型的难度较低,语言模型更像日本语,其类型与英语结构有不同。我们的实验表明,这种既定的概括性显示出令人惊讶的普遍性不足;即,更低的半透明性并不总是像人类一样。此外,从(非)统一信息密度的角度进一步探讨了英语和日语之间的这种差异。总体而言,我们的结果表明,为了构建像人类一样的计算模型,有必要进行跨语言评估。