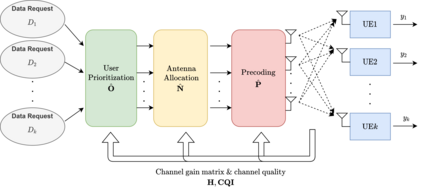
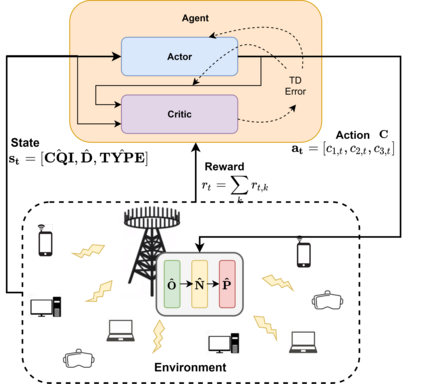
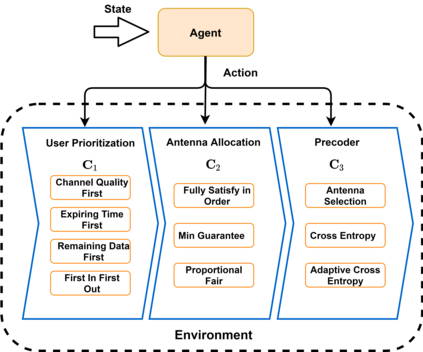
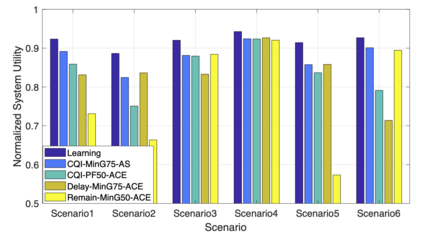
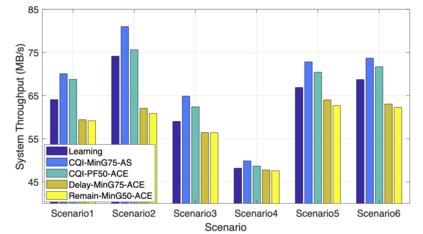
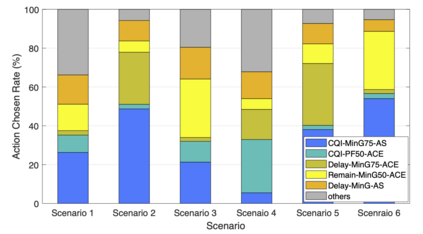
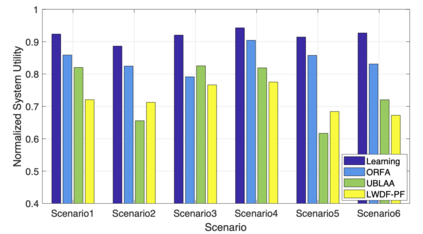
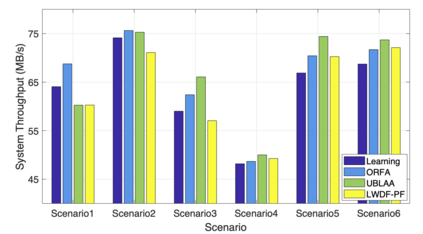
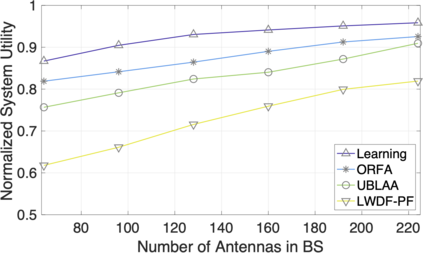
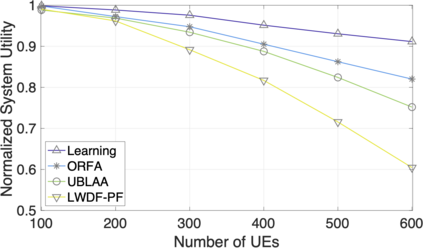
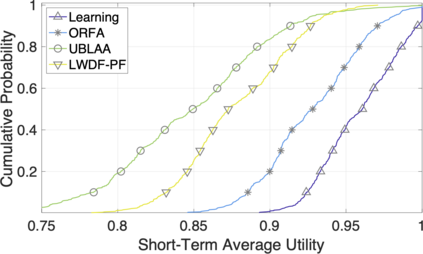
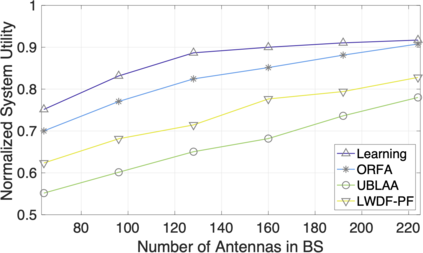
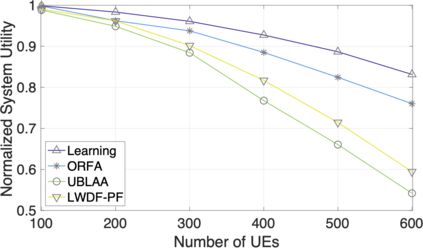
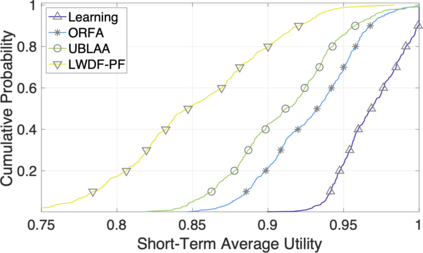
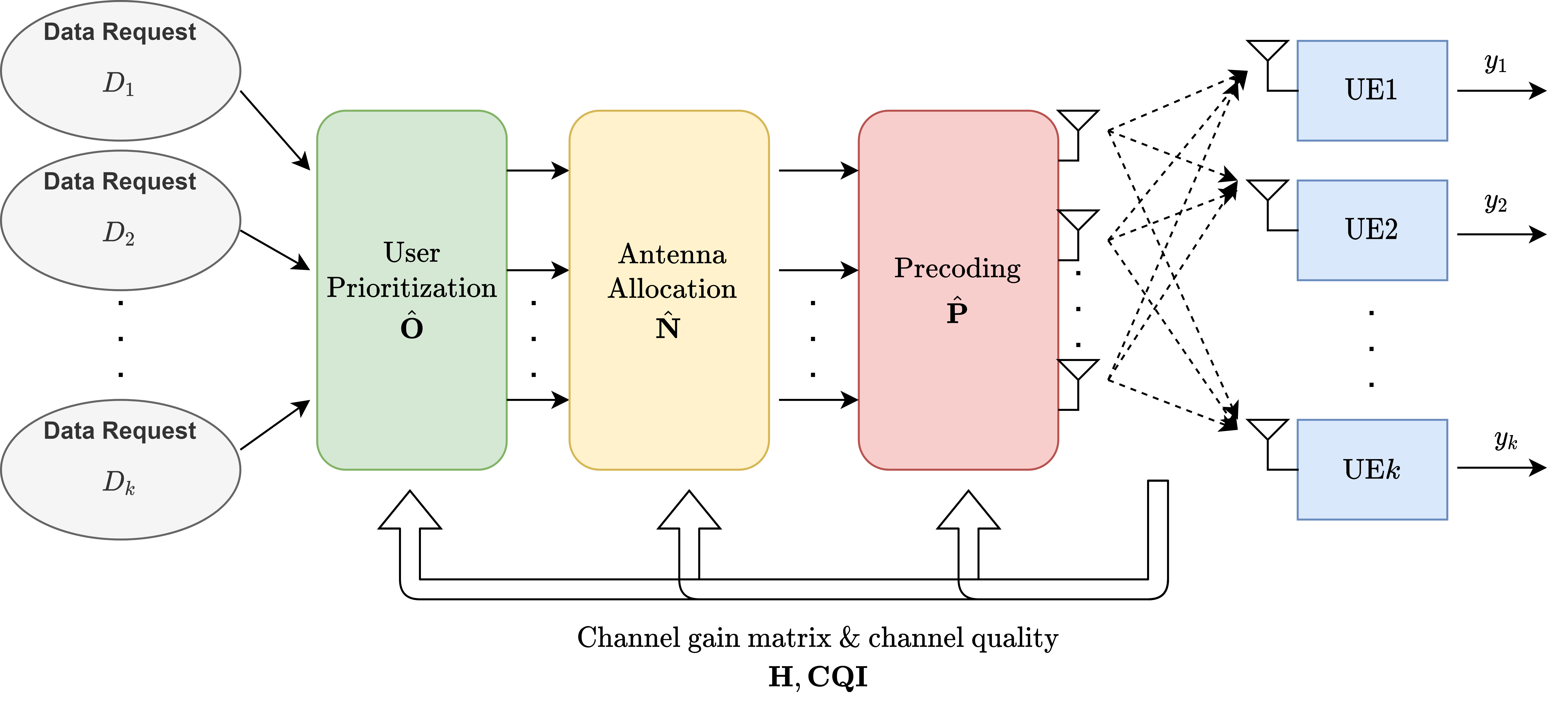
The rapid development of mobile networks proliferates the demands of high data rate, low latency, and high-reliability applications for the fifth-generation (5G) and beyond (B5G) mobile networks. Concurrently, the massive multiple-input-multiple-output (MIMO) technology is essential to realize the vision and requires coordination with resource management functions for high user experiences. Though conventional cross-layer adaptation algorithms have been developed to schedule and allocate network resources, the complexity of resulting rules is high with diverse quality of service (QoS) requirements and B5G features. In this work, we consider a joint user scheduling, antenna allocation, and precoding problem in a massive MIMO system. Instead of directly assigning resources, such as the number of antennas, the allocation process is transformed into a deep reinforcement learning (DRL) based dynamic algorithm selection problem for efficient Markov decision process (MDP) modeling and policy training. Specifically, the proposed utility function integrates QoS requirements and constraints toward a long-term system-wide objective that matches the MDP return. The componentized action structure with action embedding further incorporates the resource management process into the model. Simulations show 7.2% and 12.5% more satisfied users against static algorithm selection and related works under demanding scenarios.
翻译:移动网络的迅速发展增加了第五代(5G)及以后(B5G)移动网络的高数据率、低潜值和高可靠性应用的要求。与此同时,庞大的多投入-多输出(MIIMO)技术对于实现这一愿景至关重要,需要与资源管理功能协调,以便产生高用户经验。虽然传统的跨层次适应算法已经制定,以便排定和分配网络资源,但由此产生的规则的复杂性与服务(QOS)要求和B5G特点的不同质量要求和高度可靠性。在这项工作中,我们考虑在大型MIMOT系统中联合使用用户时间表、天线分配和预编码问题。分配过程不是直接分配资源,例如天线的数量,而是转变为基于高效的Markov决策程序模型和政策培训的深度强化学习(DRL)动态算法选择问题。具体地说,拟议的公用事业功能将QOS要求和制约因素结合到一个长期的全系统目标,从而与MDP返回的目标相匹配。我们考虑的是,在大型MIMOD系统中,将行动结构结构与行动结合,在Simaliming ASimimim im im immastra resmastrisal resmastrisal strage strismaskisal works works