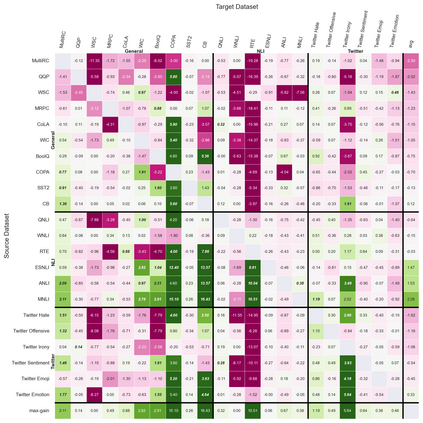
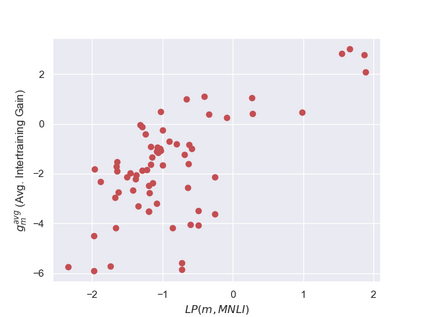
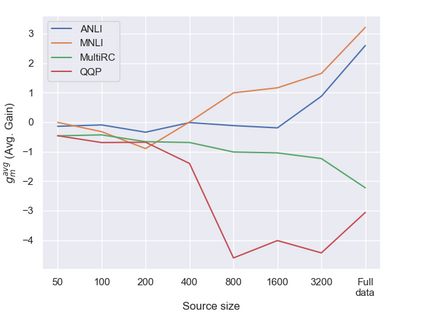
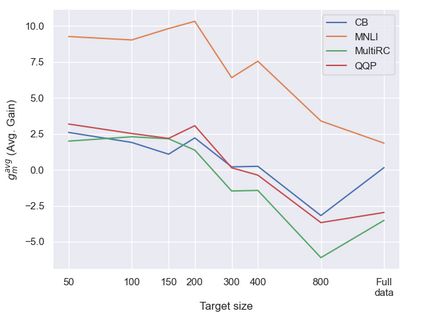
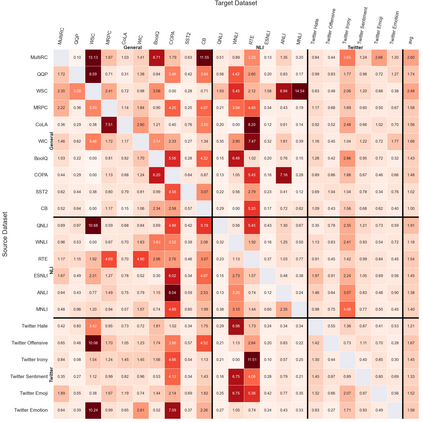
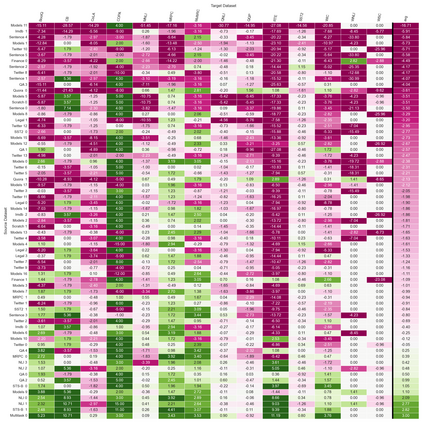
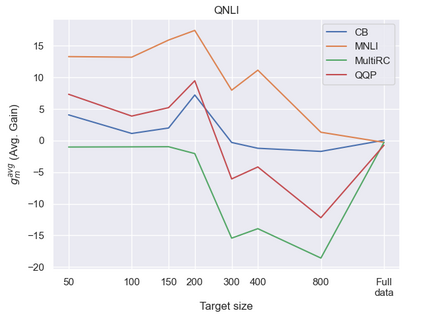
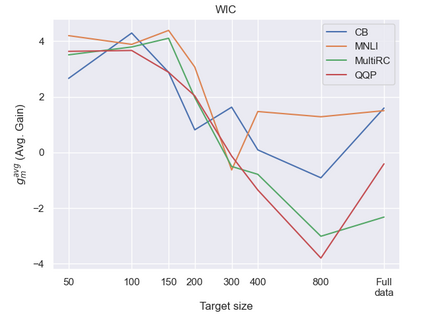
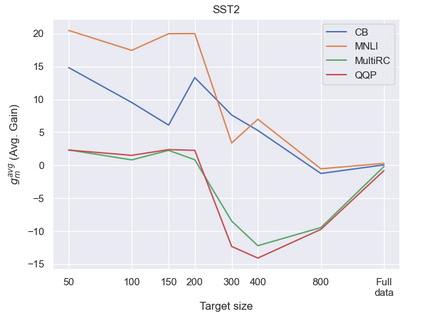
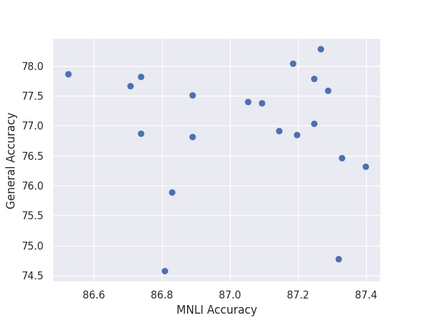
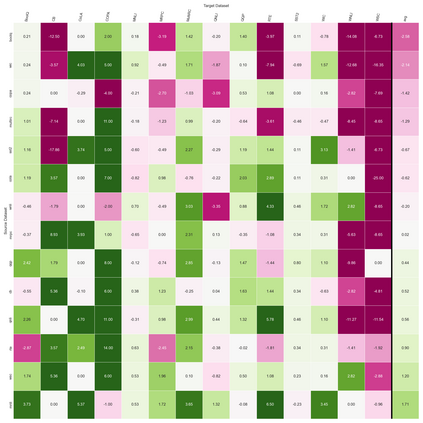
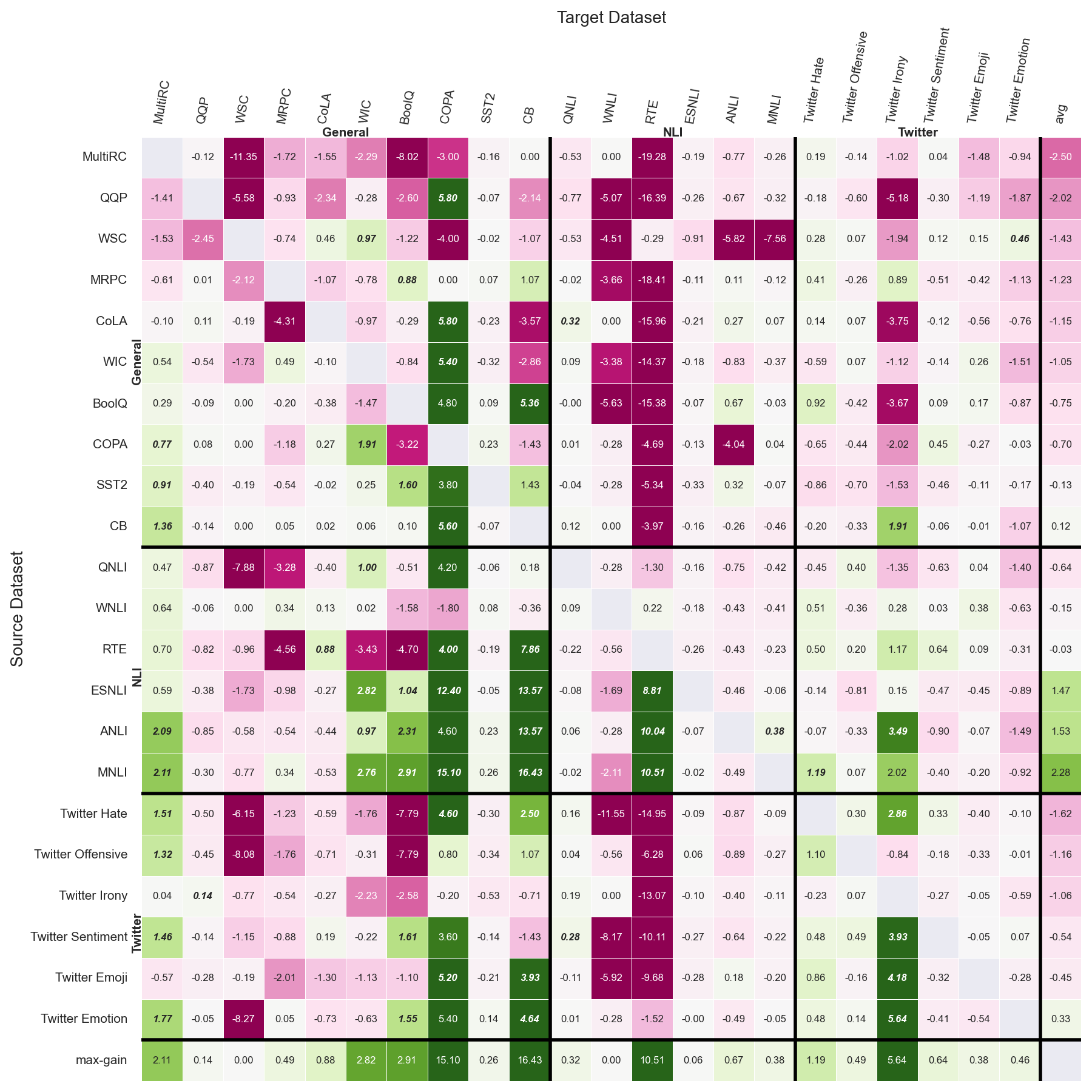
Previous studies observed that finetuned models may be better base models than the vanilla pretrained model. Such a model, finetuned on some source dataset, may provide a better starting point for a new finetuning process on a desired target dataset. Here, we perform a systematic analysis of this intertraining scheme, over a wide range of English classification tasks. Surprisingly, our analysis suggests that the potential intertraining gain can be analyzed independently for the target dataset under consideration, and for a base model being considered as a starting point. This is in contrast to current perception that the alignment between the target dataset and the source dataset used to generate the base model is a major factor in determining intertraining success. We analyze different aspects that contribute to each. Furthermore, we leverage our analysis to propose a practical and efficient approach to determine if and how to select a base model in real-world settings. Last, we release an updating ranking of best models in the HuggingFace hub per architecture https://ibm.github.io/model-recycling/.
翻译:先前的研究发现,微调模型可能是比香草预培训模型更好的基础模型。 这样的模型,在某种源数据集上进行微调,可以提供一个更好的起点,用于对理想的目标数据集进行新的微调进程。 在这里,我们系统地分析这一跨培训计划,涉及广泛的英国分类任务。 令人惊讶的是,我们的分析表明,潜在的跨培训收益可以独立分析,用于考虑中的目标数据集,并用作一个基准模型的起点。这与目前的看法相反,即目标数据集与用于生成基准模型的源数据集之间的对齐是确定跨培训成功的主要因素。我们分析了每个目标数据集的不同方面。此外,我们利用我们的分析,提出一个实用有效的方法,以确定是否以及如何选择现实世界环境中的基础模型。最后,我们发布了《Hugging Face中心》每个架构https://ibm.github.io/model-recylling/中的最佳模型的最新排名。