Ballerina:面向数据编程

在我过去十年开发的信息系统中,数据在前端应用程序、后端服务器和服务等程序之间流动。这些程序使用诸如 JSON 之类的交换格式进行网络通信。
多年来,我注意到程序的复杂性不仅取决于业务需求的复杂性,还取决于数据的表示方法。
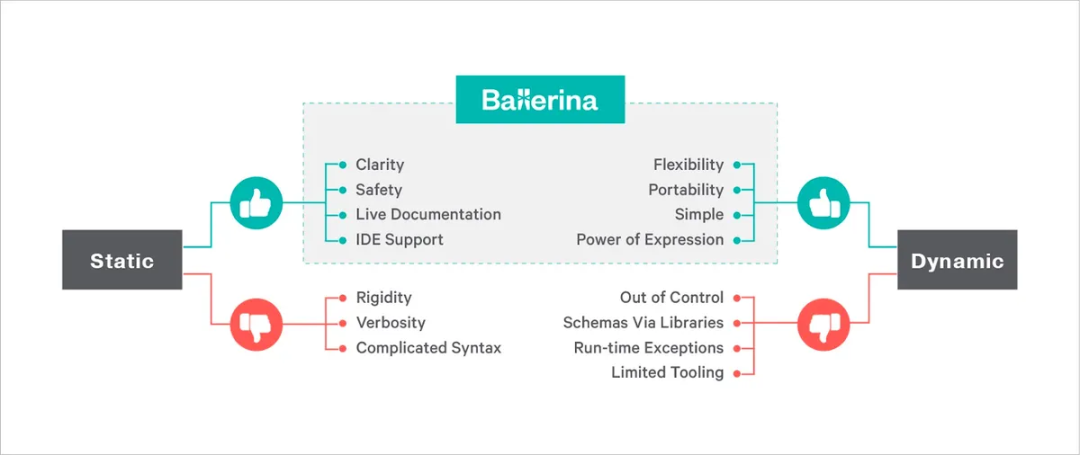
在静态类型语言 (如 Java、C#、Go、OCaml 或 Haskell) 中,用自定义类型或类表示数据似乎很自然的,而在动态类型语言 (如 JavaScript、Ruby、Python 或 Clojure) 中,我们通常会使用泛型数据结构,如 Map 和数组。
每种方法都有其优点和成本。当我们用静态类型表示数据时,IDE 可以为我们提供很大的支持,并且类型系统也为我们带来很大的安全性,但也导致代码变得更加冗长,数据模型更加严格。
在动态类型语言中,我们用灵活的 Map 来表示数据。我们可以快速地创建中小规模的代码,而不需要任何形式的繁文缛节,但 IDE 无法为我们提供自动完成支持,如果我们输入了错误的字段名时,在运行时会遇到错误。
在接触 Ballerina 之前,我认为这种权衡是编程固有的组成部分,我们不得不接受这种权衡。但后来我发现我错了:把两种类型系统的优点结合起来是可能的。在不影响安全和清晰度的情况下实现快速编码是可能的。我们可以从灵活的类型系统中受益。
我不能慢路,因为太慢了。
我害怕小跑,因为风险太大了。
我想要轻松而自信地流动,像一个芭蕾舞演员。
当我们在开发一个操作数据的程序时,通常把数据当作一等公民来对待。一等公民的特权之一是,它们可以像数字和字符串一样,不需要额外的步骤就可以创建好。
不幸的是,在静态类型语言中,数据通常无法绕过很多必要的约束。你需要使用命名的构造函数来创建数据。如果数据没有嵌套,尽管缺少字面量也并不会太麻烦。例如,创建一个叫作 Kelly Kapowski 的 17 岁图书馆会员:
Member kelly = new Member("Kelly","Kapowski",17);
但如果数据是嵌套的,那么使用命名构造函数就会变得很啰嗦。如果加入 Kelly 当前持有的书籍,那么数据看起来是这样的(假设一本书只有一个书名和一个作者):
Member kelly = new Member("Kelly","Kapowski",17,List.of(new Book("The Volleyball Handbook",new Author("Bob", "Miller"))));
在动态类型的语言中,如 JavaScript,使用字面量来创建嵌套数据会更加自然一些。
var kelly = {firstName: "Kelly",lastName: "Kapowski",age: 17,books: [{title: "The Volleyball Handbook",author: {firstName: "Bob",lastName: "Miller"}}]};
在处理数据的方式上,动态类型语言的问题在于数据不受控制。你只知道你创建的数据是一个嵌套的 Map。因此,你需要依靠文档来了解确切的数据类型是什么。
Ballerina 的第一个优势是,我能够用它创建自定义类型,并保持使用数据字面量创建数据的便利性。
与静态类型语言一样,在 Ballerina 中,我们可以创建自定义记录类型来表示数据模型。下面是创建 Author、Book 和 Member 记录类型的方法:
type Author record {string firstName;string lastName;};type Book record {string title;Author author;};type Member record {string firstName;string lastName;int age;Book[] books;};
同样,与动态类型语言一样,在 Ballerina 中,我们也可以用数据字面量来创建数据。
Member kelly = {firstName: "Kelly",lastName: "Kapowski",age: 17,books: [{title: "The Volleyball Handbook",author: {firstName: "Bob",lastName: "Miller"}}]};
当然,与传统的静态类型语言一样,如果我们遗漏了记录类型的某个字段,类型系统会让我们知道。我们的代码无法通过编译,编译器会告诉我们确切的原因。
Author yehonathan = {firstName: "Yehonathan"};ERROR [...] missing non-defaultable required record field 'lastName'
如果 VSCode 中安装了 Ballerina 插件,就会获得关于缺失字段的警告。

现在,你可能会问自己,Ballerina 的类型系统是静态的还是动态的。接下来,让我们来看一看。
在面向数据的程序中,用字段来填充数据是非常常见的。例如,假设我想给图书作者的数据增加 fullName 字段,这个字段表示作者的全名。
在传统的静态类型语言中,我需要为新填充的数据创建一个新的类型,比如一个叫作 EnrichedAuthor 的新类型。但在 Ballerina 中,这不是必需的,它的类型系统允许你使用中括号表示法动态地添加字段,就跟动态类型语言一样。例如,在下面的例子中,我们将 fullName 字段添加到 Author 记录中:
Author yehonathan = {firstName: "Yehonathan",lastName: "Sharvit"};yehonathan["fullName"] = "Yehonathan Sharvit";
这种语言特性让人感到惊艳。从某种意义上说,Ballerina 优雅地引入了两种不同符号之间的语义差异,让开发人员可以鱼和熊掌兼得:
当我们使用点号访问或修改记录字段时,Ballerina 为我们提供了与静态类型语言相同的安全性。
当我们使用中括号来访问或修改记录字段时,Ballerina 为我们提供了动态类型语言的灵活性。
在某些情况下,我们希望严格一些,不允许添加字段。这没问题,因为 Ballerina 支持封闭记录。封闭记录的语法与开放记录的语法类似,只是字段列表包含在两个|字符中间。
type ClosedAuthor record {|string firstName;string lastName;|};ClosedAuthor yehonathan = {firstName: "Yehonathan",lastName: "Sharvit"};
类型系统不允许你向封闭记录添加字段。
yehonathan["fullName"] = "Yehonathan Sharvit";ERROR [...] undefined field 'fullName' in 'ClosedAuthor'
Ballerina 还支持使用问号来表示可选字段。在下面的记录中,作者的名字是可选的。
type AuthorWithOptionalFirstName record {string firstName?;string lastName;};
在访问记录的可选字段时,你需要处理好字段不存在的情况。在传统的动态类型语言中,由于缺少静态类型检查器,开发人员很容易就忘了处理这种情况。1965 年,Tony Hoare 在一门叫作 ALGOL 的编程语言中引入了空引用,后来,他认为这是 一个价值数十亿美元的错误。
Ballerina 的类型系统已经为你准备好了一切。假设你想要编写一个将作者的名字转换成大写的函数。
function upperCaseFirstName(AuthorWithOptionalFirstName author) {author.firstName = author.firstName.toUpperAscii();}
这段代码无法通过编译:类型系统 (和 VSCode 的 Ballerina 扩展插件) 会提醒你无法保证可选字段的存在。
ERROR [...] undefined function 'toUpperAscii' in type 'string?'那么,我们该如何修改我们的代码,以便正确地处理可选字段缺失的情况呢?很简单,就是在访问可选字段后,检查它是否存在。在 Ballerina 中,字段的缺失使用 () 来表示。
function upperCaseFirstName(AuthorWithOptionalFirstName author) {string? firstName = author.firstName;if (firstName is ()) {return;}author.firstName = firstName.toUpperAscii();}
需要注意的是,这里不需要进行类型转换。类型系统足够聪明,它知道在检查变量 firstName 不是 () 之后,就可以保证它是一个字符串。
我发现 Ballerina 的类型系统还有一个非常有用的地方,即记录类型只需要通过字段结构来定义。这个让我来解释一下。
当我们在开发一个操作数据的程序时,大部分代码都是由接收数据和返回数据的函数组成。每个函数都对它接收的数据格式有所要求。
在静态类型语言中,这些要求表示为类型或类。通过查看函数签名就可以确切地知道参数的数据格式。问题是,这样会在代码和数据之间造成紧密的耦合。
让我举个例子。假设你想写一个返回作者全名的函数,你可能会这样写:
function fullName(Author author) returns string {return author.firstName + " " + author.lastName;}
这个函数的局限性是它只能处理 Author 类型的记录。它不接受 Member 类型的记录,这让我感到有点失望。毕竟,Member 记录也会有 firstName 和 lastName 字段。
需要注意的是,一些静态类型语言允许你通过创建数据接口来绕开这个限制。
动态类型语言要灵活得多。例如,在 JavaScript 中,你可以像这样实现函数:
function fullName(author) {return author.firstName + " " + author.lastName;}
函数的参数名是 author,但实际上,它可以接受任何具有 firstName 和 lastName 字符串字段的数据。问题是,当你传给它一个不包含这些字段(或其中一个)的数据时,它将会抛出运行时异常。此外,参数的预期数据格式并没有在代码中体现。因此,要知道函数需要什么样的数据,我们要么依赖于文档 (它并不总是最新的),要么需要研究一下函数的代码。
Ballerina 的类型系统允许你在不牺牲灵活性的情况下指定函数参数的格式。你可以创建一个新的记录类型,并只提到正常调用函数所需的字段。
type Named record {string firstName;string lastName;};function fullName(Named a) returns string {return a.firstName + " " + a.lastName;}
小贴士:你可以使用匿名记录类型来指定函数参数的格式。
function fullName(record {string firstName;string lastName;} a)returns string {return a.firstName + " " + a.lastName;}
你可以使用任何包含必需字段的记录来调用函数,无论它是 Member 或 Author,还是任何其他具有函数所期望的字段的记录。
Member kelly = {firstName: "Kelly",lastName: "Kapowski",age: 17,books: [{title: "The Volleyball Handbook",author: {firstName: "Bob",lastName: "Miller",fullName: "Bob Miller"}}]};fullName(kelly);// "Kelly Kapowski"fullName(kelly.books[0].author);// "Bob Miller"
我觉得 Ballerina 处理类型的方式可以用一个类比来说明:类型就像是我们在程序中用来观察现实的透镜。但需要注意的是,我们透过透镜看到的只是现实的一个方面,它不是现实本身。就像谚语说的:地图并不是领土。
例如,我们不能确切地说 fullName 函数接受的一定是一个有名字的记录,而应该是说,fullName 函数通过有名字的记录透镜来决定要接收的数据。
让我们来看另一个例子。在 Ballerina 中,具有相同字段值的两种不同类型的记录被认为是相等的。
Author yehonathan = {firstName: "Yehonathan",lastName: "Sharvit"};AuthorWithBooks sharvit = {firstName: "Yehonathan",lastName: "Sharvit"};yehonathan == sharvit;// true
首先,这种行为让我感到惊讶。两种不同类型的记录为什么被认为是相等的?但当我想到透镜的类比时,我明白了:
这两种类型是两种不同的透镜,它们看到的是同一个现实。在我们的程序中,最重要的是现实,而不是透镜。有时候,传统的静态类型语言似乎更强调透镜,而不是现实。
到目前为止,我们已经看到了 Ballerina 的类型系统不仅不会妨碍到我们,还让我们的开发工作流更高效。但其实 Ballerina 在这个基础上更进一步,提供了一种强大且便利的方式,允许我们通过表达性查询语言来操作数据。
作为一个函数式编程行家,在操作数据时,我常用的命令都是一些高阶函数,如 map、filter 和 reduce。Ballerina 支持函数式编程,但在 Ballerina 中处理数据操作的惯用方式是使用表达性查询语言,我们可以用它非常流畅地表达业务逻辑。
假设我们有一个记录集合,我们只想保留满足特定条件的记录,并用一个字段填充这些记录。例如,假设我们只想保存书名包含单词“Volleyball”的书籍,并用作者的全名来填充它们。
这是一个填充书籍作者记录的函数。
function enrichAuthor(Book book) returns Book {book.author["fullName"] = fullName(book.author);return book;}
我们可以用 map、filter 和一些匿名函数来填充书籍。
function enrichBooks(Book[] books) returns Book[] {return books.filter(function(Book book) returns boolean {return book.title.includes("Volleyball");}).map(function(Book book) returns Book {return enrichAuthor(book);});}
但这样很繁琐,声明这两个匿名函数的类型也有点烦人。但如果使用 Ballerina 的查询语言,代码就会更紧凑,更容易阅读。
function enrichBooks(Book[] books) returns Book[] {return from var book in bookswhere book.title.includes("Volleyball")select enrichAuthor(book);}
Ballerina 的查询语言将在我们的 Ballerina 系列文章中详细介绍。
在继续介绍 JSON 相关的特性之前,我们先为函数编写一个单元测试。在 Ballerina 中,当记录具有相同的字段和值时,它们就被认为是相等的。因此,要比较函数返回的数据和我们期望的数据就很容易了。
Book bookWithVolleyball = {title: "The Volleyball Handbook",author: {firstName: "Bob",lastName: "Miller"}};Book bookWithoutVolleyball = {title: "Friendship Bread",author: {firstName: "Darien",lastName: "Gee"}};Book[] books = [bookWithVolleyball, bookWithoutVolleyball];Book[] expectedResult = [{title: "The Volleyball Handbook",author: {firstName: "Bob",lastName: "Miller",fullName: "Bob Miller"}}];enrichBooks(books) == expectedResult;// true
小贴士:Ballerina 自带一个开箱即用的单元测试框架。
我们已经看到了 Ballerina 为程序内的数据表示和数据操作提供了灵活性和易用性,接下来我们来看看如何在 Ballerina 和其他程序之间交换数据。
JSON 可能是最为流行的数据交换格式。信息系统中的程序通常通过相互发送 JSON 字符串进行通信。当程序需要通过网络发送数据时,它将数据结构序列化为 JSON 字符串。当程序接收到 JSON 字符串时,会解析它,并将其转换为数据结构。
Ballerina 是为云计算时代而设计的编程语言,它支持 JSON 序列化和 JSON 解析。任何记录都可以序列化成 JSON 字符串,如下所示:
AuthorWithBooks yehonathan = {firstName: "Yehonathan",lastName: "Sharvit",numOfBooks: 1};yehonathan.toJsonString();// {"firstName":"Yehonathan", "lastName":"Sharvit", "numOfBooks":1}
反过来,一个 JSON 字符串可以被解析成一条记录。在这里,我们需要确保我们处理的 JSON 字符串是有效的 JSON 字符串和符合预期的数据格式。
function helloAuthor(string authorStr) returns error? {Author|error author = authorStr.fromJsonStringWithType();if (author is error) {return author;} else {io:println("Hello, ", author.firstName, "!");}}
小贴士:Ballerina 为我们提供了一个特殊的检查(check)结构,可以通过更紧凑简洁的方式编写相同的逻辑。
function helloAuthor(string authorStr) returns error? {Author author = check authorStr.fromJsonStringWithType();io:println("Hello, ", author.firstName, "!");}
需要注意的是,Ballerina 对 JSON 的支持不仅限于序列化和解析。事实上,Ballerina 提供了一个 JSON 类型,让你可以像在动态语言中那样操作数据。Ballerina 的高级 JSON 特性将在我们的 Ballerina 系列文章中介绍。
我们已经探索了 Ballerina 提供的关于数据表示、数据操作和数据通信的优势。我们将用一个面向数据的小型程序示例来说明这些优势,并以此来结束我们的探索。
假设我们正在构建一个由多个程序组成的图书馆管理系统,这些程序可以交换关于会员、图书和作者的数据。其中一个程序需要处理会员数据,填充会员全名字段,只保留书名包含“Volleyball”的书籍,并在每本书中添加作者的全名。
程序使用 JSON 进行通信:它接收 JSON 格式的会员数据,并期望以 JSON 格式返回数据。
以下是这个程序的代码。
首先,我们创建自定义记录类型。
type Author record {string firstName;string lastName;};type Book record {string title;Author author;};type Member record {string firstName;string lastName;int age;Book[] books?; // books 是一个可选字段};
然后,用一个函数计算具有 firstName 和 lastName 字符串字段的记录的全名。我们使用匿名记录来表示这个约束。
function fullName(record {string firstName;string lastName;} a)returns string {return a.firstName + " " + a.lastName;}
我们使用 Ballerina 查询语言来过滤和填充书籍信息:
只保存书名包含“Volleyball”的书籍;
用作者的全名填充书本的信息。
function enrichAuthor(Author author) returns Author {author["fullName"] = fullName(author);return author;}function enrichBooks(Book[] books) returns Book[] {return from var {author, title} in bookswhere title.includes("Volleyball") // 过滤书名不包含 Volleyball 的书籍let Author enrichedAuthor = enrichAuthor(author) // 填充作者字段select {author: enrichedAuthor, title: title}; // 选择一些字段
现在,我们来编写业务逻辑:它是一个函数,通过以下方式来填充会员记录:
会员的全名;
经过筛选和填充的书籍。
function enrichMember(Member member) returns Member {member["fullName"] = fullName(member); // fullName 函数可以接受会员和作者作为参数Book[]? books = member.books; // books 是一个可选字段if (books is ()) { // 显式处理字段不存在的情况return member;}// 类型系统足够聪明,它知道这里的书籍一定是一个数组member.books = enrichBooks(books);return member;}
最后,我们编写程序入口,它将会做以下这些工作:
将 JSON 解析为 Member 记录;
调用处理业务逻辑的函数来获得一个填充过的会员记录;
将结果序列化为 JSON。
需要注意的是,我们必须处理接收到的 JSON 字符串可能无效的问题。我们是这样处理的:
我们声明返回值可以是一个字符串或一个错误;
我们针对 fromJsonStringWithType 返回的内容调用 check。如果收到的 JSON 字符串是无效的,Ballerina 将自动抛出一个错误。
function entryPoint(string memberJSON) returns string|error {Member member = check memberJSON.fromJsonStringWithType();var enrichedMember = enrichMember(member);return enrichedMember.toJsonString();}
这就是处理逻辑本身的代码。你可以在 GitHub 上找到完整的代码。
为了让它变为一个真正的应用程序,我将使用 Ballerina 提供的众多通信协议中的一个,如 HTTP、GraphQL、Kafka、gRPC、WebSockets 等。
在编写本文中出现的那些代码片段时,我有一种感觉,我重新体验了 IDE 在处理静态类型语言时带给我的那种愉快的感觉。我惊讶地发现,为了这种体验,这次我不需要在表达性和灵活性上做出妥协。要知道,自从我开始使用动态类型语言以来,其灵活性让我沉迷到无法自拔。
Ballerina 缺少在不改变数据的情况下更新数据的能力,我已经习惯了在函数式编程中这么做了。我无法在 Ballerina 中通过自定义函数来达到这一目的,因为它需要支持泛型类型。但我希望在不久的将来,这个功能将被添加到 Ballerina 中。
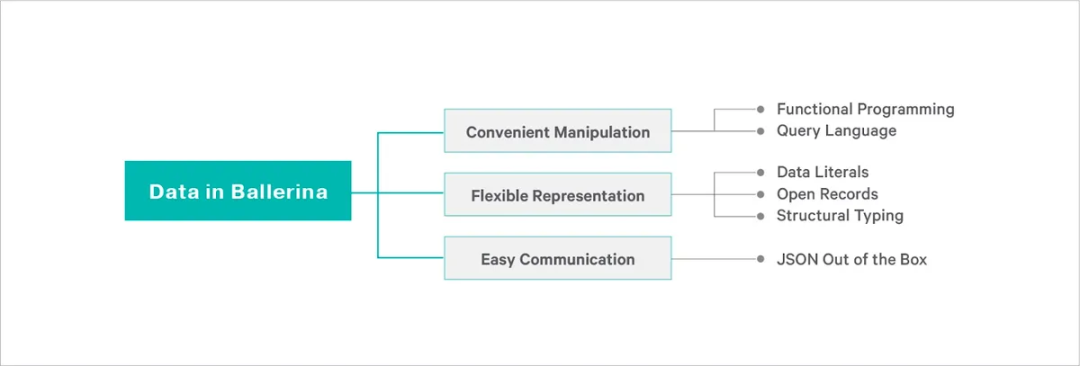
我认为 Ballerina 是一种通用的编程语言,它处理数据的方式非常适合用来构建信息系统。在我看来,这是因为 Ballerina 的主要价值是围绕数据表示、数据操作和数据通信。
它把数据视为一等公民;
它灵活的类型系统提供了比传统静态类型语言更大的灵活性,并且不会在安全性和工具方面做出妥协;
与动态类型语言相比,它灵活的类型系统提供了更多的工具和安全性,并且不会影响表达的速度和能力;
它为数据操作提供了表达性查询语言;
它内置了 JSON 支持。
你可以访问 ballerina.io 了解更多关于 Ballerina 的信息。
在后续的 Ballerina 系列文章中,我们将介绍 Ballerina 的其他方面,如表、高级查询、错误处理、Map、JSON 类型、连接器等……你可以订阅我们的 新闻源,以便在 Ballerina 系列的下一篇文章发布时收到通知。
作者简介:
Yehonathan Sharvit 是《面向数据编程》一书的作者。他从 2001 年开始用 C++、Java、JavaScript、Ruby、Python、Clojure 和 Ballerina 等语言编写代码。他目前在 CyCognito 工作,是作为 Clojure 布道师。除了开发用于大规模构建数据管道的软件库,他还帮助其他开发人员编写优雅且易于维护的代码。
原文链接:
https://www.infoq.com/articles/ballerina-data-oriented-language
点击底部阅读原文访问 InfoQ 官网,获取更多精彩内容!
腾讯薪酬大改革:升职不直接调薪;马斯克称特斯拉需裁员10%,暂停全球招聘;华为成立第三批军团|Q资讯

点个在看少个 bug 👇


