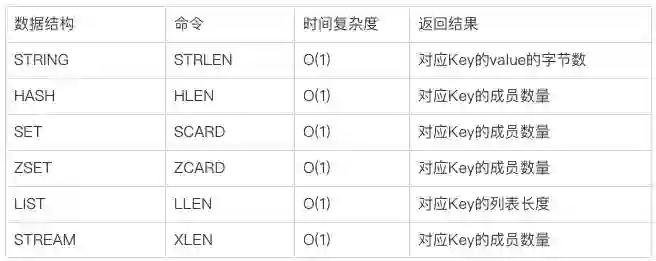
一文详解Redis中BigKey、HotKey的发现与处理

一 前言
二 大Key与热Key的定义
1 什么是大Key
-
一个STRING类型的Key,它的值为5MB(数据过大)
-
一个LIST类型的Key,它的列表数量为20000个(列表数量过多)
-
一个ZSET类型的Key,它的成员数量为10000个(成员数量过多)
-
一个HASH格式的Key,它的成员数量虽然只有1000个但这些成员的value总大小为100MB(成员体积过大)
2 什么是热Key
-
某Redis实例的每秒总访问量为10000,而其中一个Key的每秒访问量达到了7000(访问次数显著高于其它Key)
-
对一个拥有上千个成员且总大小为1MB的HASH Key每秒发送大量的HGETALL(带宽占用显著高于其它Key)
-
对一个拥有数万个成员的ZSET Key每秒发送大量的ZRANGE(CPU时间占用显著高于其它Key)
三 大Key与热Key带来的问题
1 大Key带来的常见问题
-
Client发现Redis变慢;
-
Redis内存不断变大引发OOM,或达到maxmemory设置值引发写阻塞或重要Key被逐出;
-
Redis Cluster中的某个node内存远超其余node,但因Redis Cluster的数据迁移最小粒度为Key而无法将node上的内存均衡化;
-
大Key上的读请求使Redis占用服务器全部带宽,自身变慢的同时影响到该服务器上的其它服务;
-
删除一个大Key造成主库较长时间的阻塞并引发同步中断或主从切换;
2 热Key带来的常见问题
-
热Key占用大量的Redis CPU时间使其性能变差并影响其它请求;
-
Redis Cluster中各node流量不均衡造成Redis Cluster的分布式优势无法被Client利用,一个分片负载很高而其它分片十分空闲从而产生读/写热点问题;
-
在抢购、秒杀活动中,由于商品对应库存Key的请求量过大超出Redis处理能力造成超卖;
-
热Key的请求压力数量超出Redis的承受能力造成缓存击穿,此时大量强求将直接指向后端存储将其打挂并影响到其它业务;
四 大Key与热Key的常见产生原因
-
将Redis用在并不适合其能力的场景,造成Key的value过大,如使用String类型的Key存放大体积二进制文件型数据(大Key);
-
业务上线前规划设计考虑不足没有对Key中的成员进行合理的拆分,造成个别Key中的成员数量过多(大Key);
-
没有对无效数据进行定期清理,造成如HASH类型Key中的成员持续不断的增加(大Key);
-
预期外的访问量陡增,如突然出现的爆款商品、访问量暴涨的热点新闻、直播间某大主播搞活动带来的大量刷屏点赞、游戏中某区域发生多个工会间的战斗涉及大量玩家等(热Key);
-
使用LIST类型Key的业务消费侧代码故障,造成对应Key的成员只增不减(大Key);
五 找出Redis中的大Key与热Key
1 使用Redis内置功能发现大Key及热Key
通过Redis内置命令对目标Key进行分析
通过Redis官方客户端redis-cli的bigkeys参数发现大Key
通过Redis官方客户端redis-cli的hotkeys参数发现热Key
通过业务层定位热Key
使用monitor命令在紧急情况时找出热Key
2 使用开源工具发现大Key
使用redis-rdb-tools工具以定制化方式找出大Key
3 依靠公有云的Redis分析服务发现大Key及热Key
阿里云Redis控制台中的CloudDBA
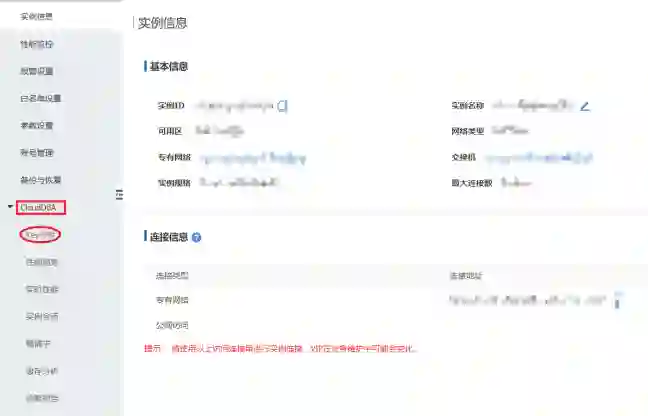
-
实时:对当前实例立即开始分析当前实例,展示当前存在的所有大Key及热Key。
-
历史:展示该实例近期曾出现过的大Key及热Key,在历史页面中,所有出现过的大Key及热Key都会被记录,哪怕这些Key当前已经不存在。该功能能够很好的反映Redis的历史Key状态,帮助追溯过去或现场已遭破坏的问题。
六 大Key与热Key的处理
1 大Key的常见处理办法
对大Key进行拆分
对大Key进行清理
时刻监控Redis的内存水位
对失效数据进行定期清理
使用阿里云的Tair(Redis企业版)服务避开失效数据的清理工作
2 热Key的常见处理办法
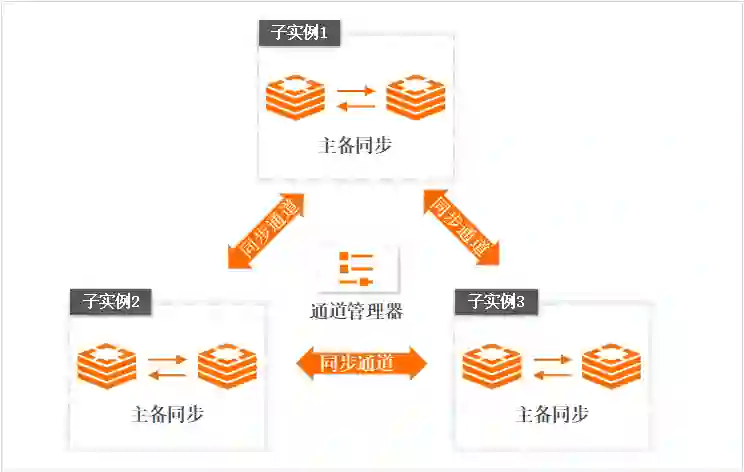
在Redis Cluster结构中对热Key进行复制
使用读写分离架构
使用阿里云Tair的QueryCache特性
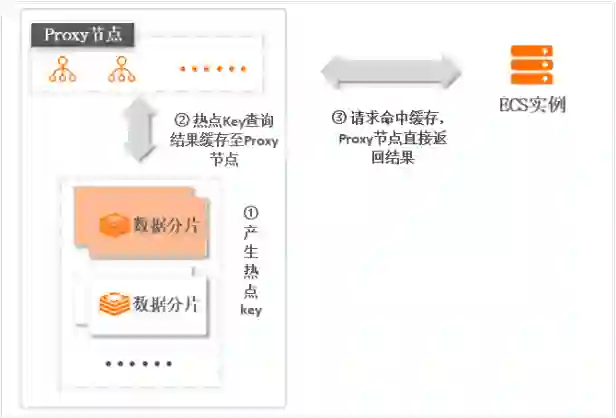
使用阿里云Redis全球分布式缓存服务
Redis入门到精通(基础篇)
点击阅读原文查看课程~
登录查看更多
相关内容

Arxiv
0+阅读 · 2022年4月20日
Arxiv
0+阅读 · 2022年4月20日





相关VIP内容
相关资讯