观点 | 多模态大模型成为AI基础设施,模型研发从“手工作坊”迈入工业化生产时代

| 作者 |
朱贵波,周世玉,刘静,张家俊,王金桥
当前,人工智能已成为世界各国的竞争焦点,抢先占领未来技术战略制高点意义重大。由于开放的环境和各领域不断上升的系统复杂度、数据总量,智能技术应用需求不断增长,智能形态和水平持续深入发展。从互联网到移动互联网再到物联网时代,计算硬件不断压缩体积、功耗与成本,人工智能已经成为共性支撑技术,推动经济、社会、国防等领域发展。另一方面,伴随大数据、计算能力、学习算法的突破和人类智能本质探索的深入,人工智能发展还在继续加速。
随着GPT/Bert、GPT-3、DALLE-E、Swin Transformer、华为盘古等大规模预训练模型快速涌现,人工智能研究领域正在经历着一场有监督学习向无监督学习条件下“大数据+大模型”的大规模预训练范式转变,即基于海量广域数据训练并且可经过微调自适用于广泛下游任务的模型。大规模预训练模型起源于自监督的语言模型,自监督的深度语言神经网络模型起初只在自然语言处理领域展开研究,直到2018年BERT在11项NLP任务上都取得了巨大成功。2019年以后,基于自监督学习的语言模型已成为基础性方法,这与2012年基于卷积神经网络AlexNet在ImageNet2012上的突破很相似,标志着一个大模型时代的开始。当下,NLP领域几乎所有的SOTA模型都是由少数几个基于Transformer的大模型架构进化而来的,而这种趋势也正在向图像、视频、语音等不同模态、不同领域扩散蔓延。
AI 行业落地难,碎片化严重,模型研发仍处于“手工作坊”阶段
人工智能正处于从“可以用”逐渐走向“好用”的落地应用阶段,但目前仍处于商业落地早期,主要面临着场景需求碎片化、人力研发和应用计算成本高、模型算法从实验室场景到真实场景效果差距大等行业痛点。大部分AI项目落地还停留在“手工作坊”阶段,AI模型投入应用需要完成包括确定需求、数据收集、模型算法设计、训练调优、应用部署和运营维护等阶段组成的整套流程。这意味着除了需要好的产品经理确定需求之外,还需要AI研发人员扎实的专业知识和协同合作能力完成大量复杂的工作。

首先,为了应对各式各样的场景需求,AI研发人员需要设计专网专用的个性定制化神经网络模型。模型设计过程要求研究人员具有充分的网络结构和场景任务专业知识,且需承受人力设计网络结构的试错成本和时间成本。一种降低专业人员设计门槛的思路是通过网络结构自动搜索的技术路线,但是这种方案对算力要求很高,并且不同场景任务都要调用大量机器进行自动搜索以获取最优模型,算力成本和时间成本仍然很高。一个项目往往需要专家团队实地驻场数月才能完成,其中数据收集和模型训练评估是否能够达到指标要求往往需要多次循环迭代,人力成本极高。
根据BOSS直聘发布的《2020人才资本趋势报告》,2019年人工智能岗位的平均月薪在两万元以上。作为国内人工智能行业“四小龙”商汤科技、旷视科技、依图科技和云从科技也面临着持续亏损、落地困难的商业困境,这里一个重要的原因是营收相对较少、研发成本高企。根据旷视科技此前提交的招股书,从2018年到2020年9月末公司累计未弥补亏损为142.5亿元;依图科技累计未弥补亏损72.20亿元。云从科技虽然今年顺利通过了科创板审议,但根据云从科技招股书来看,2018-2020年云从科技研发费用分别为1.5亿元、4.5亿元、5.8亿元,占各期营收比例分别是30.61%、56.25%和76.59%,三年持续走高。因此,如何降低研发和运维人力成本是人工智能企业亟待解决的关键问题之一。
其次,传统网络模型参数训练需要海量与行业、领域相关的且经过整理标注的数据。然而许多行业数据获取非常困难、标注成本极高,同时项目研发人员需要花费大量的时间收集原始数据。譬如,人工智能在医疗行业病理学、皮肤病学和放射学等医学图像密集领域的影响扩展增长,但是医学图像通常涉及到用户数据隐私,很难大规模获取到用于训练AI模型。而在工业视觉瑕疵检测领域,以布匹瑕疵为例,市场上需要检测的布匹种类包括白坯布、色坯布、成品布、有色布、纯棉、混纺等等,瑕疵种类繁多,颜色、厚薄难以识别,需要在工厂里长时间地收集数据并不断优化算法才能做好瑕疵检测。工业视觉应用场景千变万化,每个场景都具有专业知识的个性化的需求,而不同行业的数据在另一个场景或任务可能并不适用,还需重新收集、标注数据和训练模型,造成重复造车轮子现象,研发流程虽然相通,但研发的模型却难以复用。此外,AI模型也需要完整的、实时的支持机器自学习的数据闭环,从而能够不断迭代优化。
再次,AI模型在许多垂直行业场景任务不通用,单个模型常常只适用于特定任务特定场景,还未实现“一模型通用”的功能,譬如无人自动驾驶全景感知领域,常常需要多行人跟踪、场景语义分割、视野内目标检测等多个模型协同作战才行。而同样是目标检测和分割应用,在医学图像领域训练的皮肤癌检测和分割AI模型也无法直接应用到监控场景的行人车辆检测和场景分割。

最后,AI模型在不同领域的泛化性差。在源领域训练的模型应用到目标领域通常具有比较大的分布差异,导致性能急剧下降。譬如在工业生产场景下,虽然在实验室里测试效果较好,但是AI模型算法和场景的适配却存在偏差。一般有效的工作流程是在做算法开发前要先到工厂或者其他地方熟悉场景,再回公司研发模型算法写代码,最后在应用AI模型产品或系统时再到工厂现场或者实际场景调试部署。不同的应用场景就需要熟悉一遍,这对AI模型的研发人员要求比较高,因为大部分研发人员对实际应用场景的理解程度仍不足够。
这种高度定制化“手工作坊”式解决方案的主要特点是个性化定制和集成交付,同时存在行业数据获取难、销售获客周期长、产品有施工成本、成长呈线性增长的情况,是对产品品质要求极高的价值敏感型。
预训练模型高速发展,视觉、语言、语音等领域大模型在持续提出
互联网音视频数据呈高速增长,占比超过80% ,纯文本的预训练模型只涵盖了互联网数据中的较少部分,更丰富的语音、图像、视频等数据并未被充分利用与学习。

面对如此复杂多元的内容数据,我们人类的信息获取、环境感知、知识学习与表达,采用的是跨模态的输入输出方式,语音、图像与视频共同丰富着我们对事物的认知。那么,对于AI应用来说,又该如何理解如此复杂的互联网数据,突破模型碎片化难题?如何设计计算机模型并使其具有强大的无监督学习与通用知识迁移能力?如何使不同领域任务在统一框架下实现基于低标注代价的性能提升呢?
一种可行的路径是通过跨模态语义关联,提升多模态融合理解以及跨模态转换与生成性能。现有工作大多是以Bert为基本框架的两模态预训练模型(图像-文本、视频-文本),如VideoBert, VLBert等。VL-BERT提出一种视觉语言多模态预训练模型,该模型将图像的描述文本和关键物体特征作为BERT的输入,通过遮盖掉文本输入和图像输入来进一步增强预训练模型。VideoBERT使用融合文本信息和视频序列作为模型的输入,来进行视频预训练模型的训练。近期比较有影响力的DALLE和CLIP,他们是基于图像和文本两模态数据的、功能单一的预训练模型,前者是用于给定模板化文本输入的图像生成,而后者用于图像特征表示。上述工作虽然验证了基于大规模预训练模型的多模态理解技术路线的可行性,但主要是基于英文的单一模态和两模态预训练模型,面向中文数据的多模态预训练模型仍然较少,并且针对多模态预训练模型的小型化技术研究还很缺乏。
多模态大模型实现图文音统一知识表示,成为人工智能基础设施。
由于具有在无监督情况下自动学习不同任务、并快速迁移到不同领域数据的强大能力,多模态大训练模型被广泛认为是从限定领域的弱人工智能迈向通用人工智能的路径探索。
OpenAI 联合创始人、首席科学家 Ilya Sutskever 在推特上发文表示,“人工智能的长期目标是构建多模态神经网络,即AI能够学习不同模态之间的概念,从而更好地理解世界”。为实现更加通用的人工智能模型,预训练模型必然由单模态往多模态方向发展,将文本、语音、图像、视频等多模态内容联合起来进行学习。作为人工智能基础层算法的重要组成部分,多模态大模型及相应智能算法由于实现图文音语义空间的统一表示,正成为人工智能基础设施。
“多模态+大模型+多任务”的统一学习,模型研发进入工业化时代
实现AI模型工业化的必要条件是标准化、轻量化和通用化,并结合SaaS商业模式增强效用比,即模式轻、无需定制、一套产品可以重复使用、收入可持续、高毛利等。譬如云端协同方式,在大规模分布式云计算系统上训练大模型,然后形成能够在终端运行的高性能轻量标准化模型。轻量化标准化的模型既可以快速生产,也可以快速普及,规模化落地应用。“多模态+大模型+多任务”的统一学习为这一目标的实现提供了可行路径,将打破传统AI模型 “手工作坊式”的行业瓶颈。
近期,自动化所团队提出的视觉-文本-语音三模态预训练大模型“紫东太初”,即瞄准了模型研发的工业化,将有力改变当前单一模型对应单一任务的人工智能研发范式和产业范式,是迈向通用人工智能路径的重要探索。

“紫东太初”三模态大模型采用分别基于词条级别(Token-level)、模态级别(Modality-level)以及样本级别(Sample-level)的多层次、多任务子监督学习框架,更关注图-文-音三模态数据之间的关联特性以及跨模态转换问题,对更广泛、更多样的下游任务提供模型基础支撑。该模型不仅可实现跨模态理解(比如图像识别、语音识别等任务),也能完成跨模态生成(比如从文本生成图像、从图像生成文本、语音生成图像等任务)。同时,“多模态+大模型+多任务”的统一学习模式,具有灵活的自监督学习框架,可同时支持三种或任两种模态弱关联数据进行预训练,有效降低了多模态数据收集与清洗成本,使得一个视觉-文本-语音三模态预训练大模型可以支撑多重任务、众多场景通用、具有强大的泛化适应和规模化复制能力,减少对特定行业数据标注的强依赖。
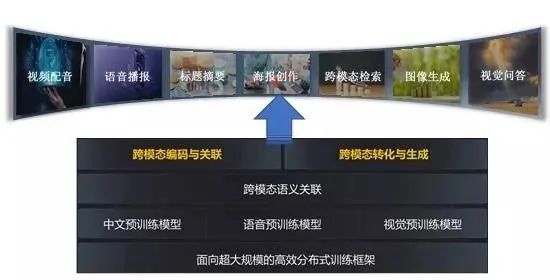
在以多模态大模型为核心的通用人工智能平台上,AI模型的研发将从“手工作坊”的高成本、定制化模式向工业化协同、高效开发的新范式转变,大大降低模型研发边际成本,提升模型的生产效率,让人工智能真正高效赋能社会经济生活、满足社会多元需求,引领未来!
图片来源于网络
欢迎后台留言、推荐您感兴趣的话题、内容或资讯!
如需转载或投稿,请后台私信。







