KDD 2021 | Transformer、知识图谱等热点话题,微软亚洲研究院论文精选,速看!

(本文阅读时间:14 分钟)
HALO:云系统中基于层级关系感知的故障定位方法

论文链接:
https://www.microsoft.com/en-us/research/publication/halo-hierarchy-aware-fault-localization-for-cloud-systems/
在大规模工业云平台中,故障诊断对于维持系统的高可靠性至关重要。当云平台中发生故障报警时,快速缩小问题范围并找到根本原因是头等要务。本文主要聚焦于利用多维度监控数据(见表1)进行故障诊断。其旨在通过大量的监控数据,找出故障集中的一组属性值组合,进而圈定根因范围,以实现加速故障解决的目标。
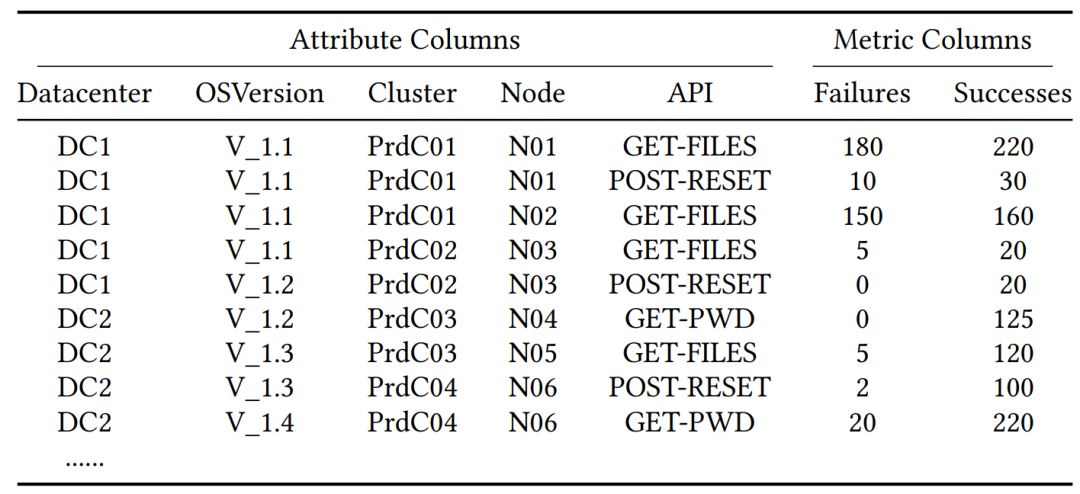
表1:多维度监控数据
事实上,面对复杂的云系统环境和高维度、大规模的监控数据,传统的人工分析十分低效且难以推广。针对这个问题,学术界近几年提出了很多种数据驱动的故障诊断方法。然而,由于待搜索的属性值组合空间呈指数量级,所以其中大多数方法的效率远达不到实时诊断的要求。而且在大部分的现有工作中,监控数据中各维度之间的层级关系都没有被考虑到。(如数据中心由若干集群组成,一个集群又包含多个节点,如图1)因此,相关工作很难将故障精确地定位到适当的层级粒度,以引导正确的诊断方向。
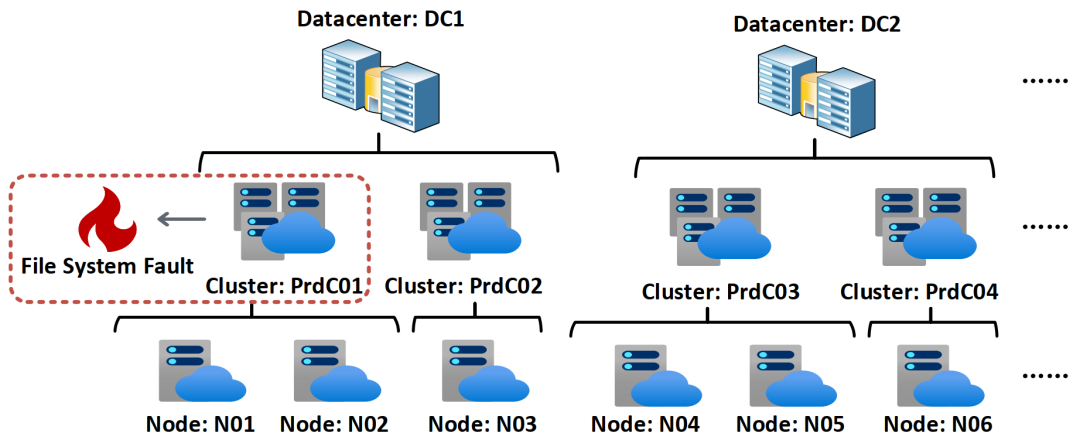
图1:云系统中的层级关系
针对上述问题,微软亚洲研究院的研究员们提出了基于层级关系感知的故障定位方法:HALO(见图2)。与以往的方法不同,HALO 将定位过程分为两个阶段:属性列搜索阶段和属性值搜索阶段。在属性列搜索阶段,HALO 首先可以自动识别监控数据中不同维度之间的层次关系,以构建 Attribute Hierarchy Graph(AHG);然后,HALO 在 AHG 上采用概率随机游走的方式来生成属性列搜索路径。在属性值搜索阶段,HALO 沿属性列搜索路径,通过宽度自适应 Beam Search 技术实现自顶向下的搜索,以得到属性值组合;最后,HALO 将采用反向截断策略,进一步精简搜索结果。

图2:HALO 示意图
通过在真实数据集上将 HALO 与其他方法进行对比(见表2),可以看出 HALO 能明显提高故障定位的准确率。并且通过对比运行时间(见图3),也可以看出 HALO 的运行效率远超同类别的其他方法。目前 HALO 已经成功地应用在微软多个产品的不同场景中,如 Microsoft Azure 云计算平台中的虚拟机故障诊断和 Microsoft 365 中的 Exchange Online 安全部署等。实际的应用效果都充分表明 HALO 具有很好的通用性和实用价值。
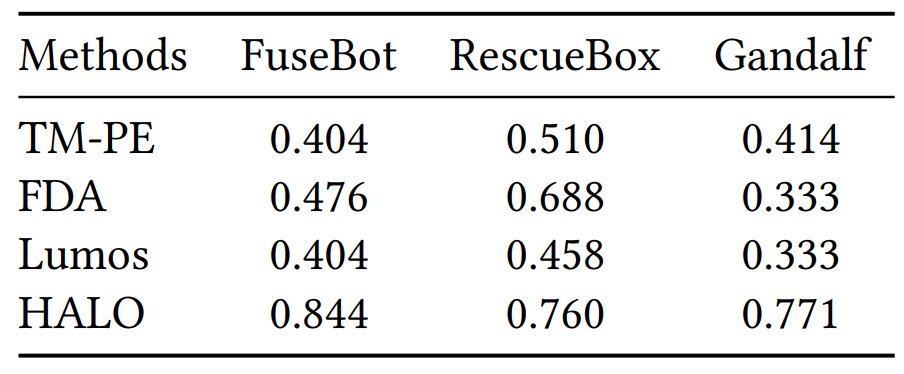
表2:真实数据集中 HALO 与其他方法的对比
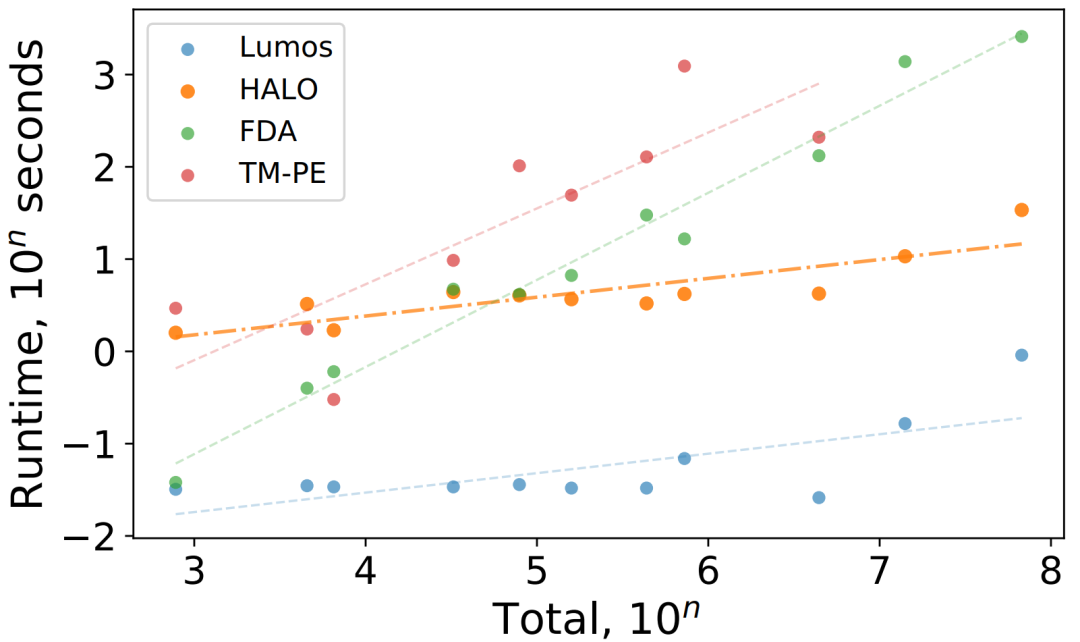
图3:HALO 与其他方法运行时间的对比
基于 TRA 和最优运输学习多种股票交易模式

论文链接:
https://arxiv.org/pdf/2106.12950.pdf
代码链接:
https://github.com/microsoft/qlib/tree/main/examples/benchmarks/TRA
股票预测是量化投资中最为关键的任务。近年来,深度神经网络因其强大的表征学习能力和非线性建模能力,逐渐成为股票预测的主流方法。现有的预测方法均假设股票数据符合独立同分布(IID)且采用单一模型有监督地对股票数据建模。但实际上,股票数据通常会包含多种不同甚至对立的分布(Non-IID),比如动量(历史收益率高的股票未来收益率会高)和反转(历史收益率低的股票未来收益率会高)这两种分布形式同时存在于股票数据中,但是已有的模型并不具备同时学习股票数据中多种分布的能力。
因此,微软亚洲研究院的研究员们提出了 Temporal Routing Adaptor (TRA),来赋予已有模型学习多种分布的能力。具体而言,TRA 在给定骨干模型的基础上,引入了一组 Predictors 来建模不同分布,和一个 Router 来根据样本的规律 p(y_t│X_t) 将其分配到所属的 Predictor 上进行训练和推理。为了保证 Router 能够预测出样本的规律,研究员们设计并利用了两种与 p(y_t│X_t) 关联的信息作为其输入:1) 利用骨干模型的隐层来表征 p(y ̂_t |X_t),2) 利用Predictor的历史预测偏差来表征 p(y_(<t)│X_(<t))。实验表明,这两种信息对 Router 有能力预测出样本规律起到了重要作用。TRA 的两个主要模块和基于骨干模型的具体实现可以参考图4。
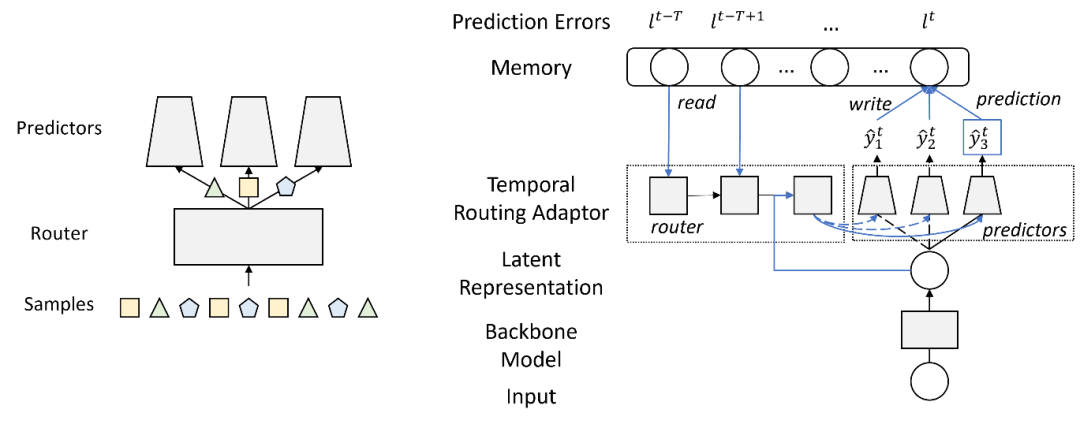
图4:TRA 结构示意图
为了有效地训练 TRA 模型,另一个需要解决的问题是,如何保证分配到不同 Predictor 的样本是属于不同规律的。因此,研究员们基于最优运输 (Optimal Transport) 设计了一个迭代优化的算法。最优运输被用来求解在分配的样本满足特定比例约束下,如何分配样本能够最小化整体预测偏差。求解得到的分配方案会用来更新对应的 Predictor,并继续下一轮迭代,直至收敛。

图5:基于最优运输将样本分配到一组 Predictors
实验表明,TRA 可以稳定提升之前在股票预测中表现最强的基准模型如 Attention LSTM 和Transformer 的预测性能,并取得更高的投资收益(结果见表3)。
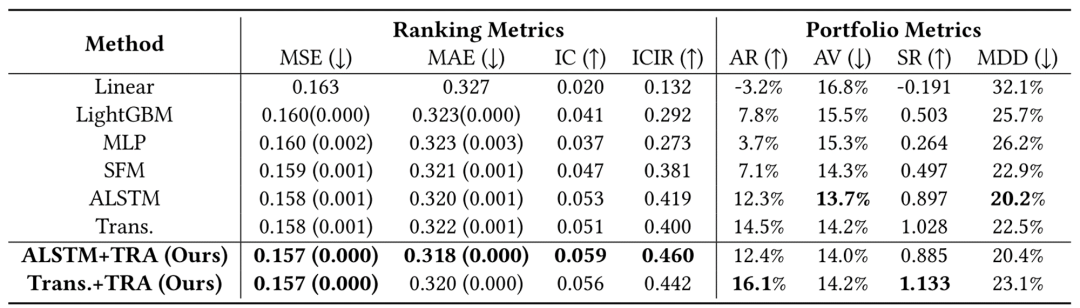
表3:TRA 模型相比于其他基准模型在股票排序预测任务下的性能
锚点知识图生成:一种为新闻推荐提供推理的新范式

论文链接:
https://www.microsoft.com/en-us/research/uploads/prod/2021/05/KDD2021-anchorkg.pdf
知识图谱不仅可以用于提高推荐算法的准确性,还可以为推荐提供推理(reasoning)的能力。然而在新闻场景中,现有的推荐推理方法存在一定的缺陷,例如计算成本高,只能用于排序;只能寻找单一路径,不能很好的结合新闻文本信息等。
在本文中,微软亚洲研究院的研究员们提出了一种新的基于知识图谱的推理范式 AnchorKG,它的优点有以下几点:
(1)可拓展性强,支持大规模的通用知识图谱;
(2)能够结合知识图谱和文本内容;
(3)不局限于只提供单一解释路径;
(4)能够灵活地应用于推荐的不同阶段:召回和排序。
对于每篇新闻文章,研究员们从知识图谱中生成一个和这篇新闻内容紧密相关的小规模子图(Anchor KG)。这个子图包含了出现在新闻中的重要实体,以及在知识图谱中与这篇新闻紧密相关的信息。当在进行新闻间的推荐推理时,研究员们利用两篇新闻 Anchor KG 的重合关系,就可以找出两篇相关新闻间的推理路径。
为了得到 Anchor KG 的生成器,研究员们还提出了一种基于强化学习的框架,并用经典的演员-评论家(actor-critic)算法进行优化,如图7所示。生成器(即演员)学习动作策略函数 ,它以状态和可能的动作空间为条件,来计算动作的概率分布,同时使用多层感知器来建模演员网络。评论家则通过估计 MDP 环境中的动作价值函数,来评估动作好坏,并使用时间差异方法进行训练。此外,为了更好地学习模型,研究员们设计了几种训练技巧,包括:1)热启动训练;2)基于知识图谱的负采样;3)多任务学习。
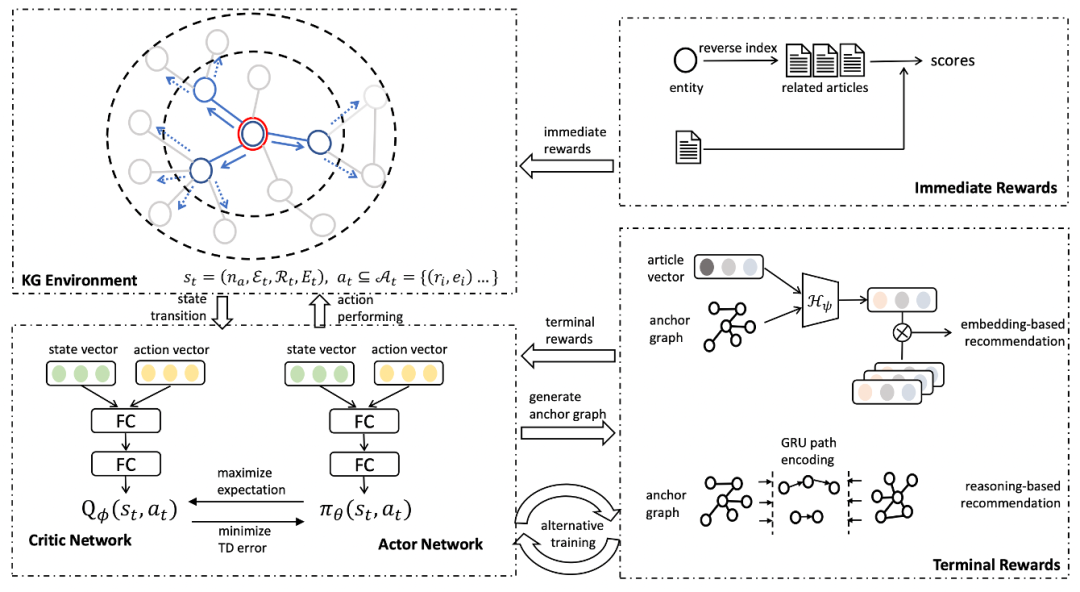
图6:基于强化学习的学习框架
研究员们在两个新闻数据集上验证了本文提出模型的效果(如图8所示),与多种基线方法相比,AnchorKG 不仅准确率更高,而且还能提供高质量的解释路径(见表4和表5)。
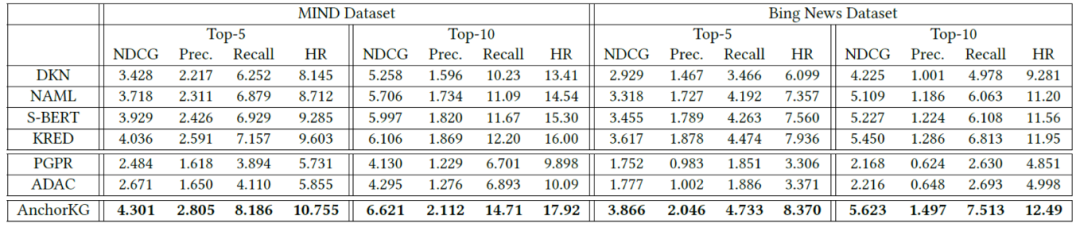
表4:不同模型的推荐准确性比较
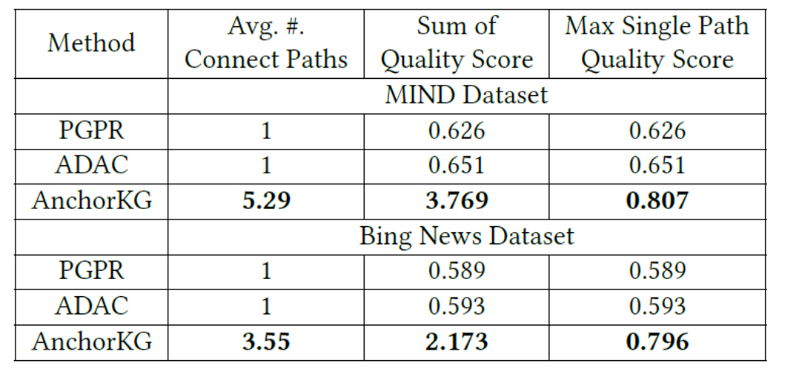
表5:不同模型的推荐可解释性比较
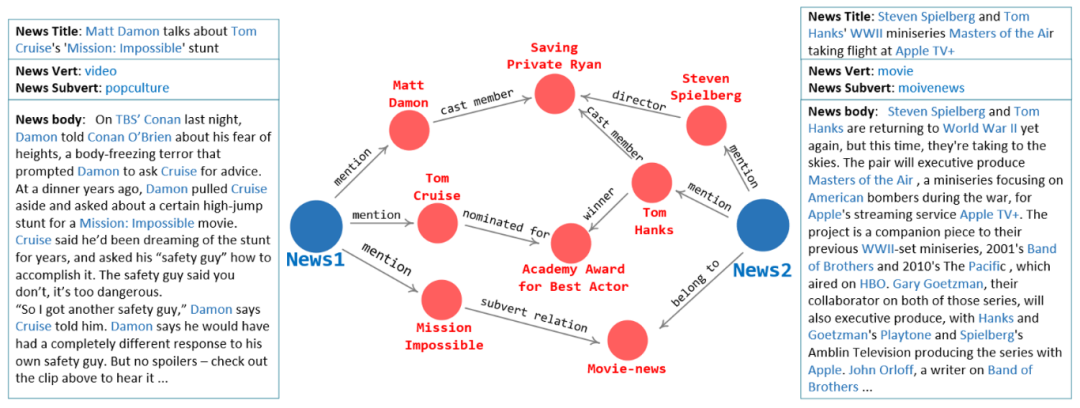
图7:利用两篇新闻的 AnchorKG 进行推荐推理的样例
Table2Charts: 基于共享表格表征的图表推荐

论文链接:
https://arxiv.org/abs/2008.11015
表格(table)是由一系列具有相同或相似属性的多维数据组成的半结构化数据。制作图表(charts)是人们对表格内容进行理解和交流的一种重要方式。在制图的过程中,人们常常会遇到不同的问题。一方面,从表格数据中抽取有意义的关系和模式需要一定的专业知识,想要更好地展现数据的特征,还需要挑选合适的图表类型。另一方面,在办公软件中制作图表,要经过框选数据、类型选择、参数选择等一系列复杂的操作,不利于办公效率的提升。因此,本文提出了 Table2Charts 模型,通过学习共享表格表征,以实现多种类型的图表推荐。
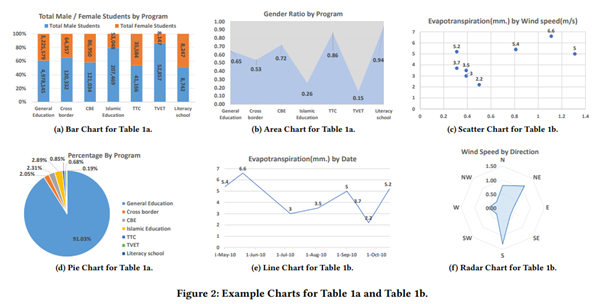
图8:Table2Charts 能推荐的多种图表类型
在现实生活中,由于图表类型的多样性以及表格内容的丰富性,图表推荐面临着以下几个挑战:1)分散模型成本高昂,为每种类型的图表分别提供推荐模型,会降低推荐效率并成倍增加内存开销;2)数据不平衡,绝大部分表格都属于四种主要类型,其它类型的数据非常稀少;3)表格整体理解,数据列的语义受到表头、数值组合乃至其余数据列的共同影响,而正确理解数据列对于推荐决策至关重要。
针对这些挑战,本文设计了共享的表格表征以及统一的图表抽象方式。对于给定的表格,每个数据列被分别编码成特征向量,并抽象为一个 field token。特征向量包含表头文本的 embedding、数值的统计特征以及数据列类型和角色等多方面信息,以帮助编码器准确地理解数据列。同时,本文为不同的图表类型设计了一套语法模板,使用固定的 command tokens 和可变的 field tokens 将图表抽象为序列,将图表推荐转化为 table2sequence 形式的任务。
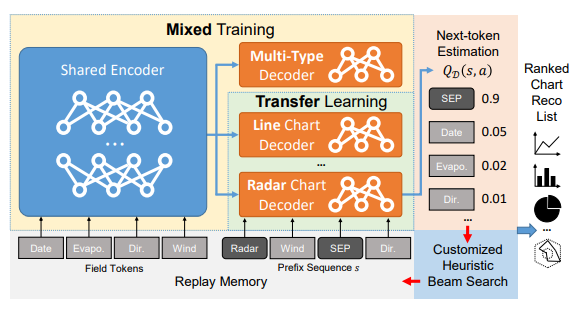
图9:Table2Charts 框架
在 Encoder-Decoder 框架的基础上,本文采用了深度 Q 值网络的思想,使用 next-token estimation 任务进行训练。在推荐时,使用语法约束的 beam search 得到有序的图表推荐结果。表格理解部分是一个统一的共享编码器。对于不同类型的图表推荐,模型分别训练不同的小型解码器,以应对不同的需求场景。每个解码器由一个独立的带有 copy 机制的序列生成模块构成。
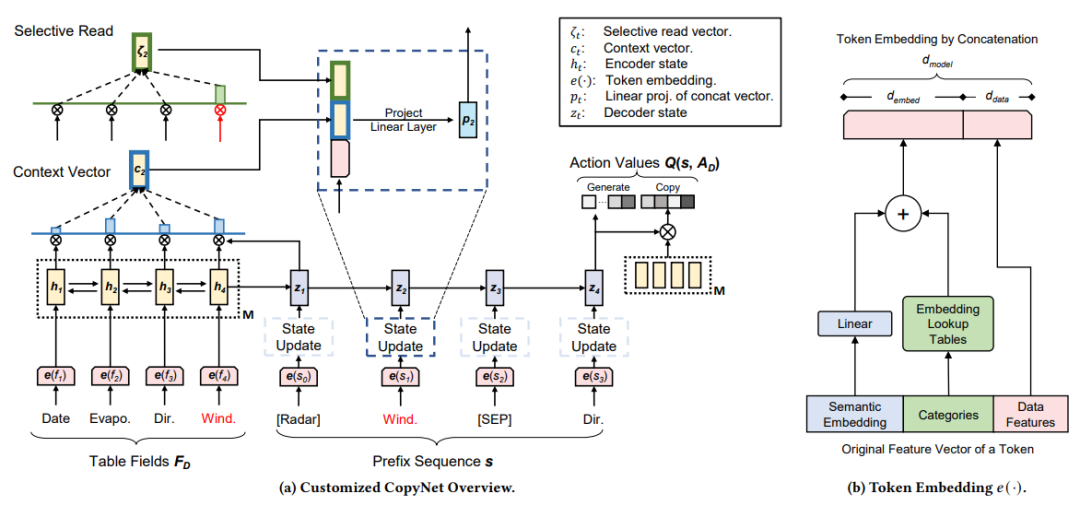
图10:深度 Q 值网络结构
本文使用不同的图表数据进行了两类解码器的训练:1)采用所有数据训练得到 multi-type 解码器,能够根据输入的表格推荐合适类型的图表,适用于从零开始的推荐场景;2)在共享编码器的基础上,采用单类型数据训练得到 single-type 解码器,适用于特定类型的图表推荐场景。后者受益于从其他类型数据中迁移过来的表格理解知识,同时也保证了特定类型的图表生成质量。
在实验中,本文提出的 Table2Charts 在数据选择与制图设计两个步骤的表现,均大幅优于现有的图表推荐模型或工具。共享表格表征的迁移为所有类型的图表推荐带来了一致的提升,对于数据稀少的类型,提升效果尤为显著。同时这也表明,共享编码器确实学习到了通用的模式和特征。
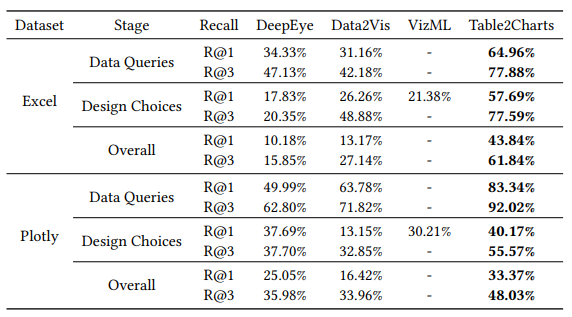
表6:Multi-type 图表推荐任务效果对比
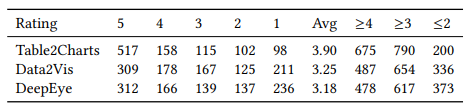
表7:各模型推荐图表人类评分
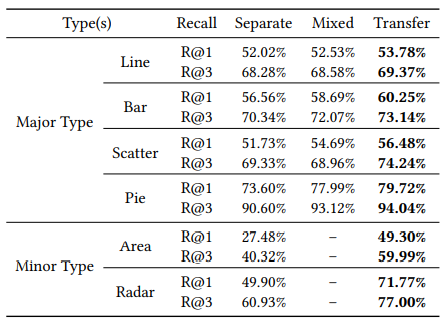
表8:Single-type 图表推荐任务效果对比
TUTA: 通用表格预训练的树结构Transformer

论文地址:
https://arxiv.org/abs/2010.12537
表格是一种非常重要和常见的半结构化数据,广泛使用在文档和网页中。在收集的六千万个文档和网页表格(包括超过二十亿单元格)中,微软亚洲研究院的研究员们首次对通用结构的表格进行了大规模的预训练。并且在表格结构理解的六个下游数据集上,也都取得 SOTA 的效果。
理解表格面临着各种挑战,需要综合理解语义、空间和结构,如:需要在简短的单元格文本里来捕捉表格里的语义;需要在二维的表格空间中进行理解;需要对表格的层级信息理解。
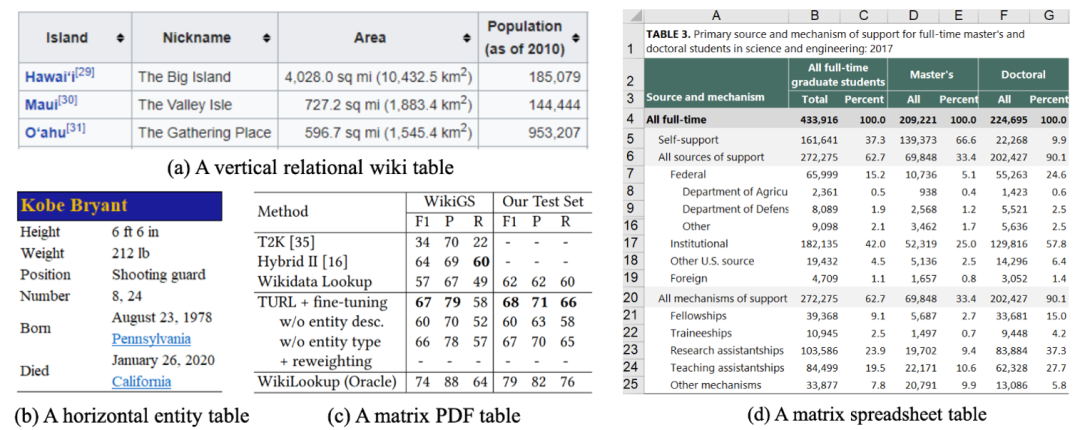
图11:表格结构示例
Transformer 在自然语言的预训练上已经取得了较好的效果。但是,针对通用表格位置、结构建模困难等一系列问题,本文相应地提出了 Tree-based Transformer。同时,研究员们还设计了二维树来建模单元格的空间和层级,并对单元格的二维树坐标和单元格间的二维树距离进行了量化,进一步设计了基于二维树结构的注意力机制。
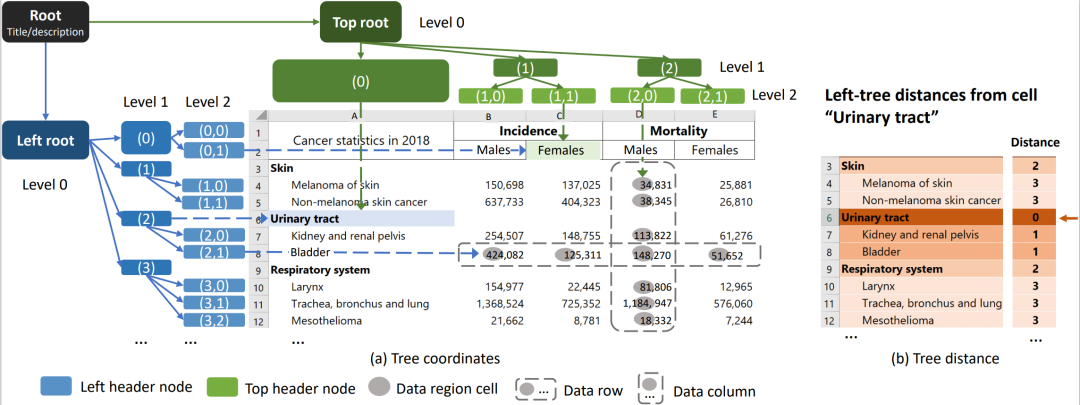
图12:基于二维树结构的位置编码和距离度量
在表格预训练任务上,为了可以学习到不同层级的表征,且更好的应用到不同级别的下游任务上,本文除了使用经典的 token MLM 任务,还进一步设计了 cell-level cloze 的任务和 table-level 的 context retrieval 任务。
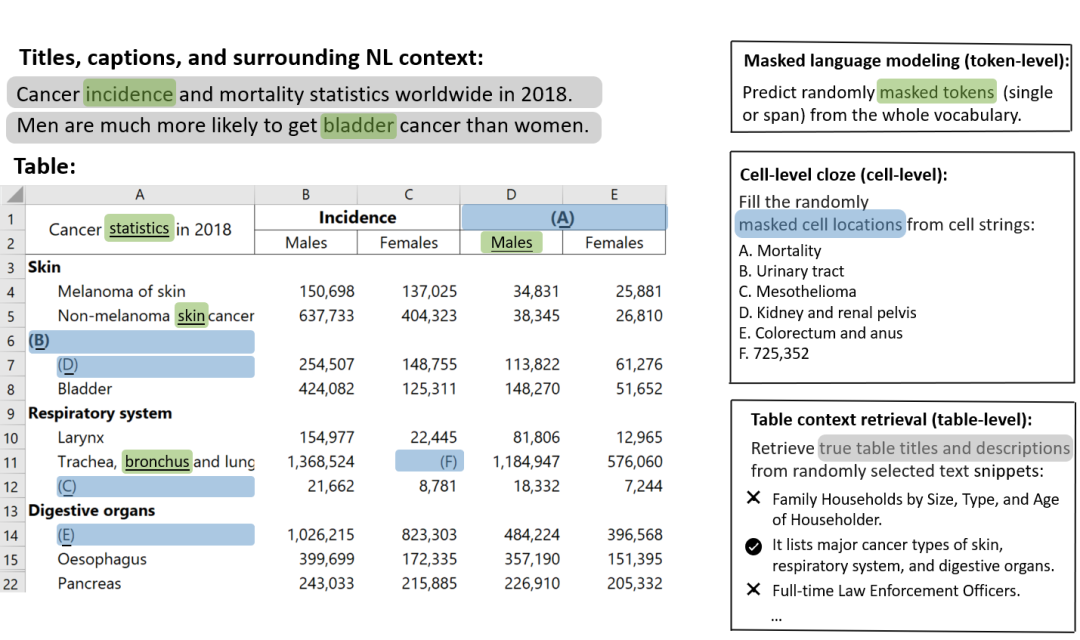
图13:token、cell 和 table 粒度上的表格预训练任务
实验表明,模型在表格结构理解(表格类型识别和单元格类型识别)的六个下游数据集上均取得了最好的效果。消融实验也证明了利用树结构对理解通用结构表格的有效性。同时,结合三个预训练任务,也有助于提高下游任务的表现。
请在下面的选项中,选出你最感兴趣的论文题目,得票最高的论文,我们将邀请论文作者进行专题深度讲解!另外,此前推送的 KDD 2021 文章 “用NAS实现任务无关且可动态调整尺寸的BERT压缩” 也参与到本次投票中,回顾详细内容可点击上述链接!
你也许还想看: