论文浅尝 - ESWA | 知识图谱的自动扩充方法
论文笔记整理:谭亦鸣,东南大学博士。

来源:ESWA141(2020)
链接:https://www.sciencedirect.com/science/article/abs/pii/S0957417419306839
为了使计算机理解人类语言,并且实现推理,人类知识需要被表示并储存为能够被计算机处理的形式。知识图谱(KG)被设计为一种反应词及词间关系的结构形式。但是目前的知识图谱存在两个限制因素:其一是对于大部分人类语言来说,图谱的规模和范围存在局限性;其二则是新词跟进。为了解决这些问题,本文提出PolarisX,一种通过实时抓取分析网络新闻和社交媒体实现自动扩展的知识图谱,利用微调的BERT模型构建无语言依赖性的知识图谱。基于BERT的关系抽取模型被用来抽取新的关系,并将它们添加到知识图谱中。作者验证了PolarisX的novelty与准确性,确认其新词处理能力以及“无语言依赖性”。
动机与贡献
如上文所属,现有KG存在(大多数语言上的)规模不足,无法跟进新词等两个局限性。
如表1所示,这里的新词分为两种:1.新词新意;2.旧词新意。

对于这两个问题,作者认为解决的关键在于KG的构建需要跟上新词出现的节奏(考虑到新词出现的频率以及开放域等特点,显然依赖人工跟进解决不了这个问题),一种合理的方式是爬取社交媒体获取新词,而后抽取新的知识(尤其是关系),并添加到知识图谱中。
因此,本文提出了一种自动成长的知识图谱PolarisX(大数据处理平台Polaris的一个部分),通过爬取新闻网站以及社交媒体,抽取新的关系,生成对应的知识子图,然后添加到知识图谱中,并采用ConceptNet验证了它的有效性。
作者认为本文的主要贡献为:
1.处理新词:PolarisX能够利用已有数据生成KG并通过新闻和社交媒体实时跟进新词的涵盖
2.无语言依赖性:使用multilingual BERT模型通用的处理各种语言
模型与算法
下图是PolarisX的自动构建框架,主要包含三个部分:
1.Social Crawler用于扩充知识资源(社交媒体/新闻),并做关键词抽取
2.Semantic Analyzer的主要作用是确定新的关系
3.Knowledge Miner负责构建和扩充知识图谱
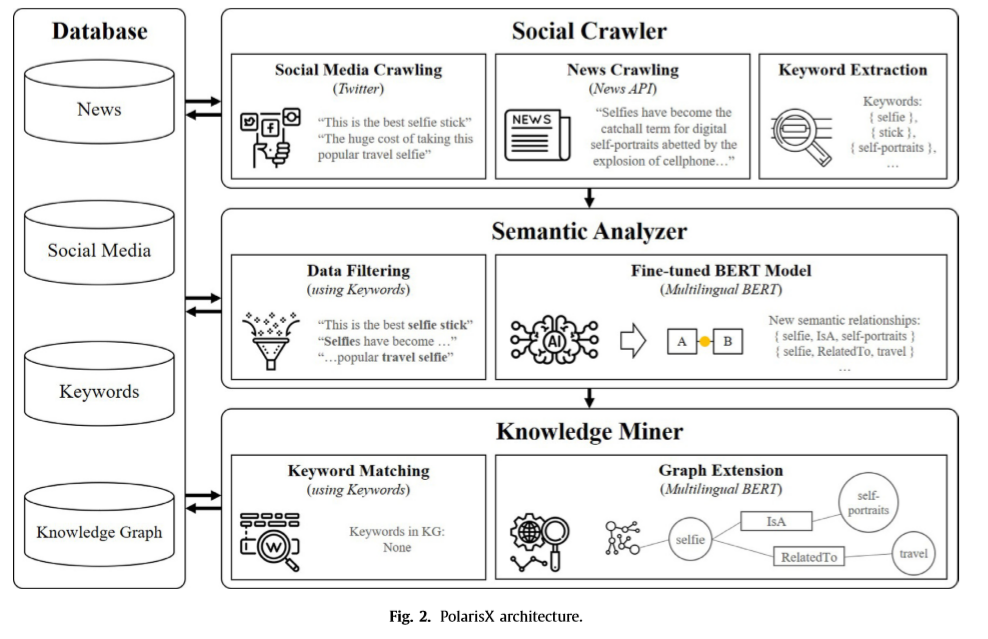
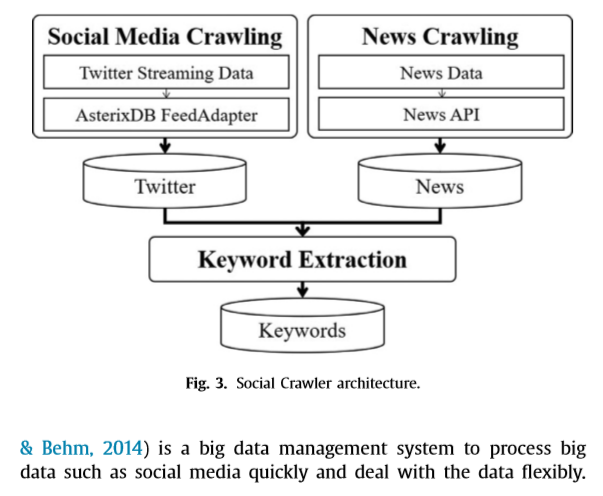
Social Crawler:
这里主要实时爬取Twitter和新闻数据,这些数据被作为扩充KG的原始资源,推特数据利用Apache AsterixDB系统的 Feed Adapter function实现实时收集,新闻数据则来自NewsAPI(https://newsapi.org/.),对于获取的资源使用LDA(Latent Dirichlet Allocation)抽取其中的关键词。
Semantic analyzer:
新关系(主要指关键词之间的关系)的抽取是通过BERT模型实现的(作者在这里使用的是BERT-base,Multilingual Cased预训练模型,支持104种语言),微调使用TACRED数据集实现。

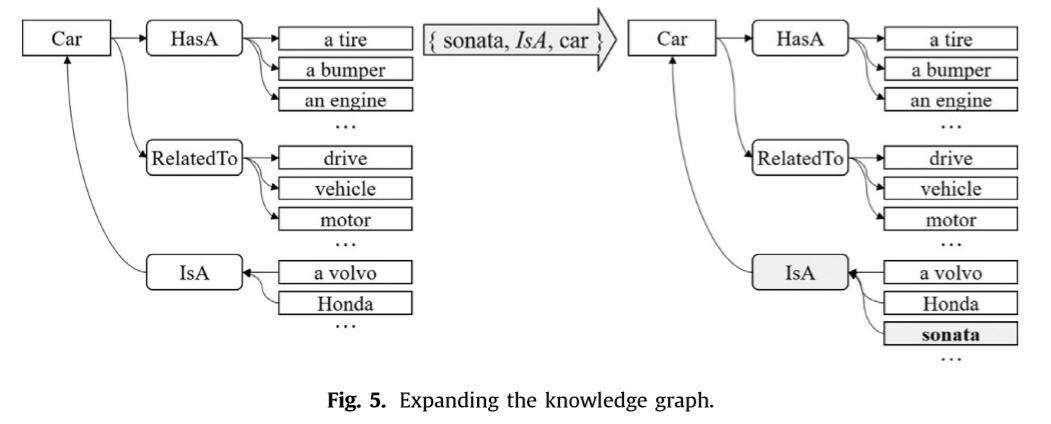
Knowledge Miner
如下图,knowledge miner利用字符串匹配将新发现的关系链接到现有知识图谱上
实验与结果
为了验证自动扩充KG方法的效果,作者提出了四个实验方式:
1.验证处理新词的能力
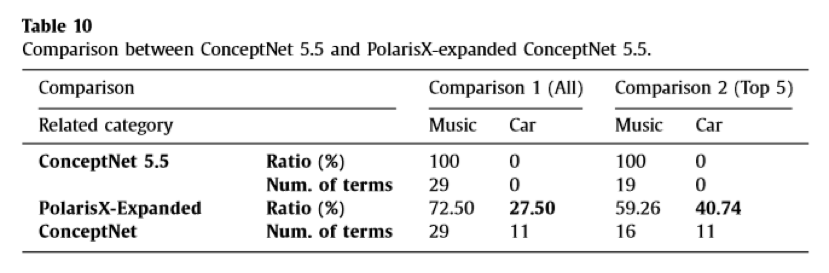
使用ConceptNet 5.5(英语/韩语)以及使用PolarisX扩充的ConceptNet 5.5对比其中一词“Sonata”(一般视作一个音乐术语,在韩国则还有相同名字的汽车品牌)


从效果上看,使用PolarisX扩充的ConceptNet涵盖了许多Sonata汽车的信息,下表展示了ConceptNet及ConceptNet+PolarisX两者的一个对比:
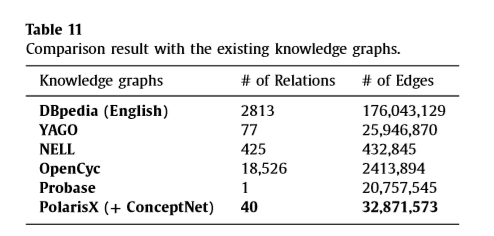
2.知识图谱扩充
与DBpedia,YAGO等现有KG的对比来看,ConceptNet+PolarisX具有更多的边,作者认为这粗略的表明具有更加丰富的知识(A higher total number of edges roughly means a richer knowledge base)
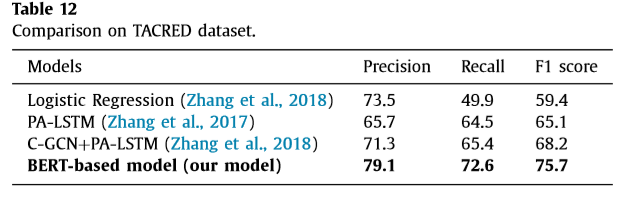
3.语义解析准确率
作者验证BERT-based关系抽取模型的效果如下表所示:
OpenKG
开放知识图谱(简称 OpenKG)旨在促进中文知识图谱数据的开放与互联,促进知识图谱和语义技术的普及和广泛应用。

点击阅读原文,进入 OpenKG 博客。





