浙大CAD&CG实验室提出PVNet,实时且效果超群,已开源
点击上方“CVer”,选择加"星标"或“置顶”
重磅干货,第一时间送达

作者:彭思达(论文一作)
https://zhuanlan.zhihu.com/p/65400509
本文已授权,未经允许,不得二次转载
我们介绍一篇2019 CVPR oral的6D Pose Estimation的论文:PVNet: Pixel-wise Voting Network for 6DoF Pose Estimation,该论文由浙江大学CAD&CG国家重点实验室提出。截止目前,据我们所致,PVNet是6D Pose Estimation方法中效果最好的论文。PVNet的输入为RGB图片,效果与2019 CVPR的RGB-D方法DenseFusion相同。

论文链接:https://arxiv.org/abs/1812.11788
论文主页,包括了一个实时AR demo:https://zju3dv.github.io/pvnet/
论文代码:https://github.com/zju3dv/pvnet
作者还开源了他们用blender合成数据代码:https://github.com/zju3dv/pvnet-rendering
1. 引言
1.1 论文的问题描述
输入一张图片,6D Pose Estimation这个问题的目标是检测出物体在3D空间中的位置和姿态。随着计算机视觉算法的提升,对3D空间中物体状态的检测越来越受关注。在2018 ECCV上,最佳论文奖也授予给了6D Pose Estimation领域的论文。
通过感知图片中物体的状态,可以提高计算机对这个世界的认知,从而有诸多应用,比如机器抓取,物流仓库无人运输,AR/VR。近年来,亚马逊开展的Amazon Picking Challenge,预示着6D Pose Estimation在工业无人化的重要应用。
1.2 当前方法在这个问题的局限性
传统方法常常借助local descriptor来解决6D Pose Estimation这个问题。但是,对于没有表面问题的物体,local descriptor的提取往往很差。近年来,深度学习对场景理解的能力非常瞩目,也就有工作希望通过一个网络直接从图片中回归出物体的6D Pose,但发现网络的泛化能力一般。6D Pose的搜索空间大,是导致网络泛化能力一般的一个原因。
最新的6D Pose Estimation工作会先在2D图片中检测物体的关键点,然后通过2D-3D的对应,用PnP计算出物体的6D Pose。在2D图片中检测关键点大大减小了网络的搜索空间,深度学习方法在6D Pose Estimation的效果也有了很大的提升。但对于Occlusion,Truncation这些状态下的物体,效果仍然有局限性。
1.3 我们的观察和对问题的解决
我们观察到,对于occlusion的物体,图片中有很多其他无关物体的干扰。因此,我们提出利用物体可见部位的局部信息,来检测关键点。首先,我们检测出物体的可见部位。然后,每个像素预测一个指向物体关键点的方向向量。
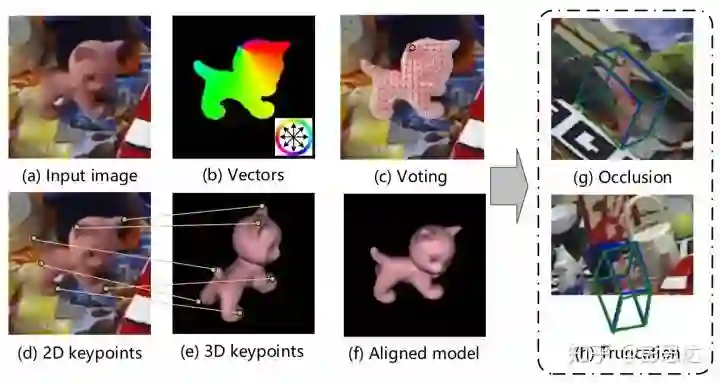
这个新的关键点定位方法相对于heatmap的关键点检测方法有三大优势。一个是heatmap方法对关键点只有一次预测,而在我们的方法中,物体可见部分的像素对关键点都有一个预测,极大提高了模型的鲁棒性。第二个优势是,我们对物体关键点的方向向量场的表示,很大程度的利用了刚体物体的性质。对于刚体物体,我们人只要见到物体露出的一部分,就能推测出物体其他部分的方向。通过方向向量场的表示,可以帮助网络学习到刚体物体的结构性质。第三个优势是,heatmap只能表示图片内的关键点,而方向向量场可以检测图片外的关键点,所以可以检测Truncation状态下的物体的6D Pose。
1.4 论文的效果
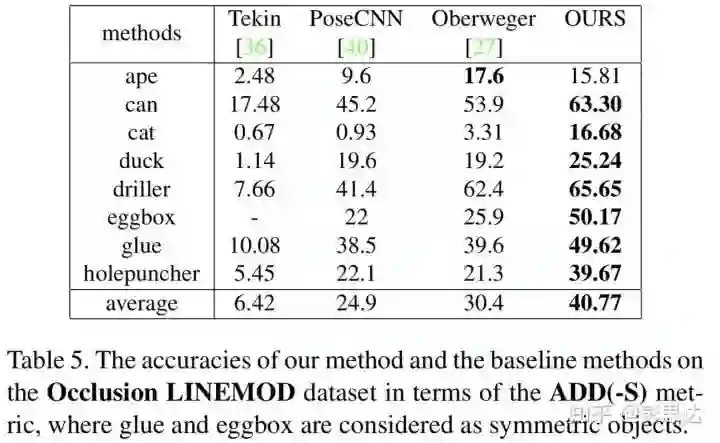
因为我们关键点定位方法的两大优势,我们的论文PVNet在6D Pose Estimation上有很大的提升。在经典的LINEMOD数据集上,我们方法在ADD(-S) metric上有30.32%的提升。在比较困难的Occlusion LINEMOD数据集上,有10.37%的提升。我们的论文方法只输入RGB图片,和目前效果最好的RGB-D方法DenseFusion在LINEMOD数据集上效果相同。而且,我们方法还能实时检测6D Pose,有25FPS的速度,在我们的论文主页中有一个实时demo。我们还发布了一个Truncation LINEMOD数据集,用于推动community对Truncation状态下的物体的6D Pose Estimation。
2. 论文方法
2.1 一种新的关键点定位方法
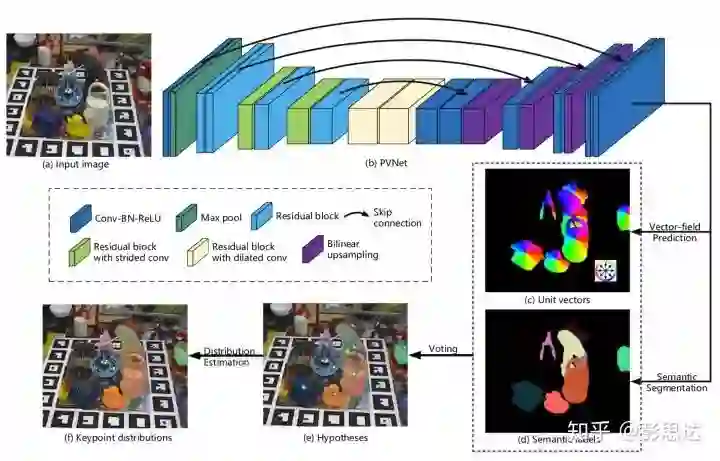
我们论文的主要贡献是提出了一个新的关键点定位方法。首先,PVNet读入一张RGB图片,然后输出目标物体的semantic segmentation和指向物体关键点的向量场。随后,通过Ransac voting,我们从方向向量场计算出物体的关键点。
在关键点的生成过程中,PVNet同时还会生成物体关键点的概率分布,也就是关键点空间分布的mean和covariance。我们随后在PnP中,利用关键点的不确定性,进一步提升了6D Pose Estimation的鲁棒性。
2.2 对物体关键点的新定义


在实验中,我们还发现物体关键点的定义对关键点的定位影响很大。之前的深度学习方法将物体的关键点简单地定义为物体在3D空间中的bounding box的八个角点。这8个角点在2D图片中可能离物体比较远,加大了关键点检测的难度。我们用farthest point sampling算法,生成物体表面的8个关键点。在实验中可以看出,角点的covariance往往比较大,而物体表面关键点的不确定性比较小。
3. 实验分析
3.1 Ablation study
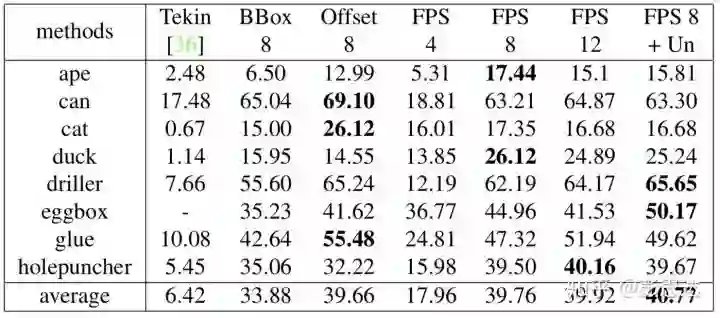
在实验中,我们首先验证了自己提出的做法的有效性,包括关键点定位方法和新的关键点定义。实验在Occlusion LINEMOD上进行,metric为ADD(-S) metric。
Tekin一列代表之前检测bounding box角点的工作,而BBox 8一列是PVNet检测bounding box角点时的6D Pose Estimation Accuracy。可以看出,我们提出的关键点定位方法有很大的提升。
FPS 8一列,是我们PVNet检测8个表面关键点时的6D Pose Estimation Accuracy。可以看出,检测表面关键点,可以让ADD(-S) metric有进一步的提升。
3.2 与其他方法的比较
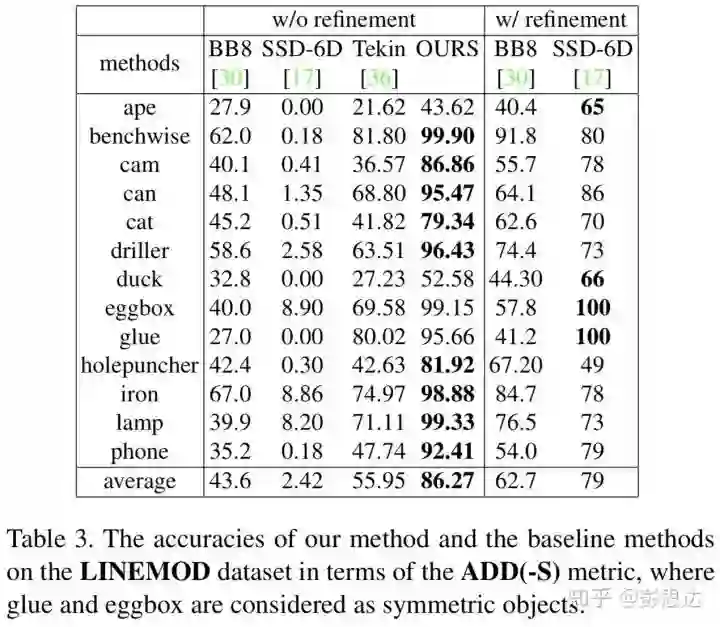
我们在LINEMOD数据集和Occlusion LINEMOD数据集上和之前的方法进行了比较。在经典的LINEMOD数据集上,我们方法在ADD(-S) metric上有30.32%的提升。在比较困难的Occlusion LINEMOD数据集上,有10.37%的提升。值得注意的是,在LINEMOD上,我们的方法和使用RGB-D输入的DenseFusion效果一样。
4. 参考文献
[1] Tekin, Bugra, Sudipta N. Sinha, and Pascal Fua. "Real-time seamless single shot 6d object pose prediction." CVPR. 2018.
[2] Wang, Chen, et al. "DenseFusion: 6D Object Pose Estimation by Iterative Dense Fusion." CVPR. 2019.
CVer学术交流群
扫码添加CVer助手,可申请加入CVer-目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、人群密度估计、姿态估计、强化学习和竞赛交流等群。一定要备注:研究方向+地点+学校/公司+昵称(如目标检测+上海+上交+卡卡),不根据格式申请,一律不通过。

▲长按加群
这么硬的论文分享,麻烦给我一个在在看

▲长按关注我们
麻烦给我一个在看!


