CVPR 2022|处理速度仅用0.2秒!港科大&腾讯AI Lab开源基于GAN反演的高保真图像编辑算法
点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
导读
本文介绍了一篇来自港科大和腾讯 AI Lab已被CVPR 2022收录的工作。工作提出了一种新颖的高保真GAN反演框架,该框架能够在保留图像特定细节(例如背景、外观和照明)的情况下进行属性编辑。不仅处理速度能够达每张图 0.2s,还能保证编辑后图像的高保真度与高质量。

代码:https://github.com/Tengfei-Wang/HFGI
主页:https://tengfei-wang.github.io/HFGI/
视频:https://www.bilibili.com/video/BV1Xq4y1i7ev
只需一张照片,这个AI算法就能按照用户需求快速编辑图像属性,下面是AI脑补出照片微笑的样子:



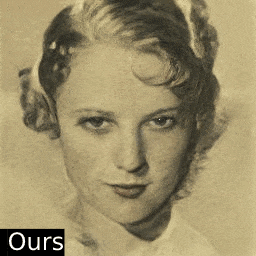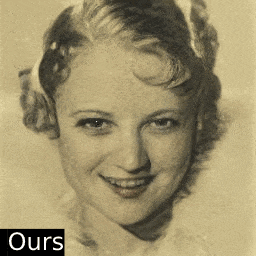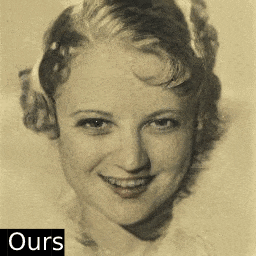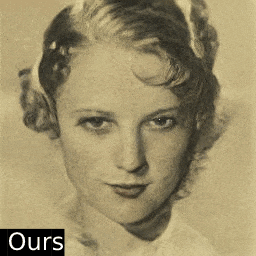


再也不用担心拍照时把握不住微笑的时机了呢。除了表情,年龄、姿态也可以随心所欲变变变:




而且编辑后的图像可以高保真地保留原图的细节,比如背景、光照、装扮。
再从网络上找几张大家熟悉的名人照片试试,十年后的马斯克,假笑男孩Lecun,还有… … 涂了口红的约翰逊?

该项研究已经被CVPR 2022收录。
一、基于GAN Inversion的高保真图像编辑
GAN inversion技术最近被广泛研究,它可以将一张照片映射到一个GAN生成器的隐空间中,从而利用StyleGAN强大的能力对图片进行编辑。目前的GAN inversion方法分为三类:
-
基于编码器(encoder-based) 这类方法编辑图片的速度很快 (每张图 < 1s),但是编辑后的图片会丢掉很多原图中的细节,保真度低。 -
基于优化 (optimization-based) 这类方法对每张照片分别迭代, 保真度高,但 速度很慢(每张图几分钟)。 -
混合方法 这类方法先用编码器得到一个初始化的隐变量,然后对每个隐变量优化,速度介于基于第一类和第二类之间 (每张图数十秒至数分钟),但依旧缓慢,影响实用性。
这就导致大家在选择模型的时候需要做出权衡和取舍,是选择更快的速度呢,还是选择更高的保真度呢?对于有选择困难的小伙伴来说,简直太纠结了!
那么,本篇论文是如何选择速度和质量的呢?答案是:全都要。养一只会捕鱼(丢失的细节)的熊(补充编码器),就可以鱼和熊掌一块得到啦。在快速处理(每张图 0.2s)的同时,又能保证编辑后图像的高保真度与高质量。
二、方法
在介绍算法之前,作者先分析了基于编码器的方法进行重建或者编辑保真度低的原因。这里提到信息论中大名鼎鼎的率失真理论(Rate-Distortion theory),即对于一个编码-解码系统,隐编码(latent code)的bit-rate对重建信号的保真度(重建信号与源信号的distortion)存在限制。
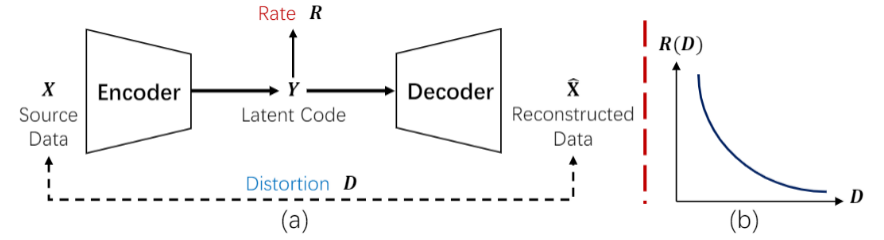
也就是说,之前的编码器压缩得到的隐编码很小(low-rate),通常是1x512或者18x512,这就会导致在生成器重建过程中必然会损伤掉一些信息,造成较大的distortion,使得重建或者编辑后的图像和原图相比发生失真。
那么,是不是我们直接增大编码器输出隐编码的大小(high-rate),问题就解决了呢?答案是:yes and no。这样做确实可以提升重建图像的保真度,但是我们的目的是对图像进行编辑而不是重建。Low-rate隐编码由于是通过高度压缩的,所以可以编码一些高级、丰富、解耦的语义,这些隐编码在隐空间里通过操控(vector arithmetic)可以方便的编辑图像属性。但对于high-rate隐编码,冗余会造成隐编码耦合,而且编码通常缺乏语义信息(low-level),这就导致图像难以有效编辑。
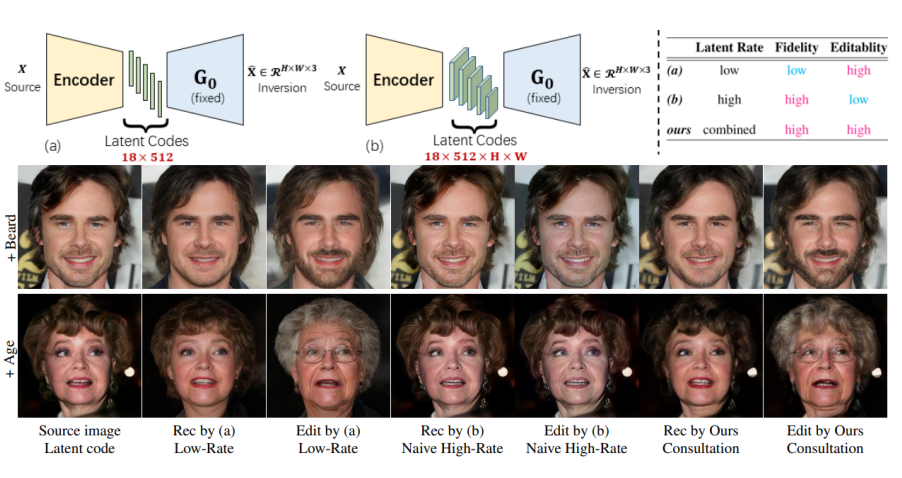
为了解决这个问题,本文提出了一种名为信息参照(information consultation)的方法,同时利用low-rate和high-rate隐编码。该模型包括两个编码器,基础编码器压缩低率隐编码,用于保证图像的可编辑性;参照编码器对低率重建图像的失真信息进行补充编码,得到一个高率的隐编码,补充丢失的细节信息。
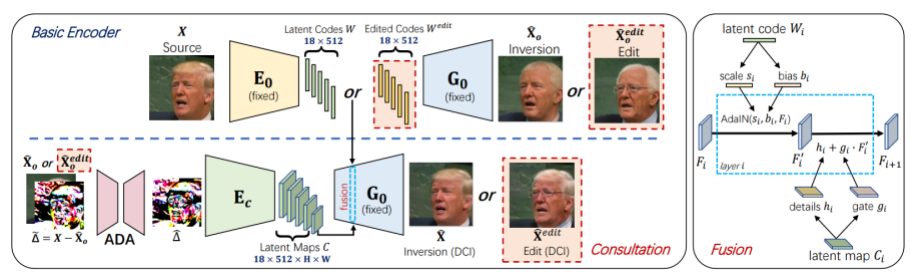
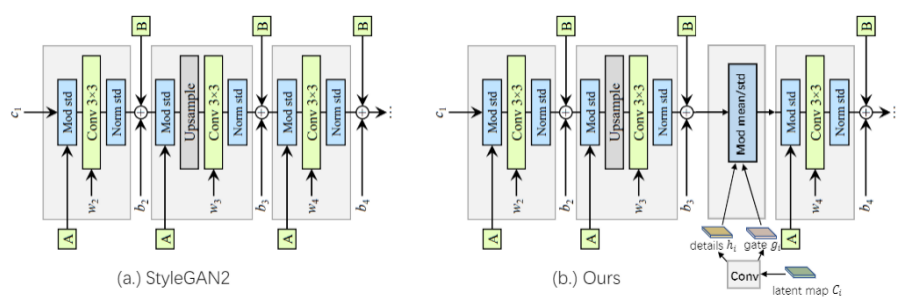
这两部分隐编码在生成器中通过参照融合层(consultation fusion)整合,共同用于图像生成。参照融合层参照下图:
由于缺少成对的编辑图像进行训练,作者还提出了相应的自监督训练方法以及自适应失真校正模块(ADA)。
三、实验结果
论文提供了人脸和车辆照片上的对比结果。首先是和基于编码的方法的对比:

然后是和优化方法以及混合方法的对比:

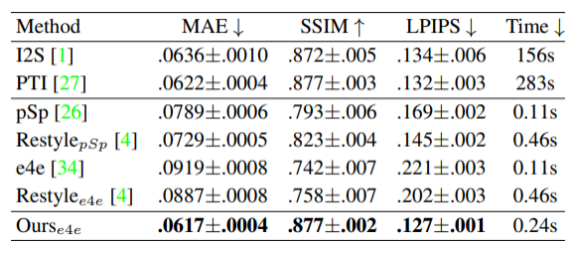
以及定量对比:
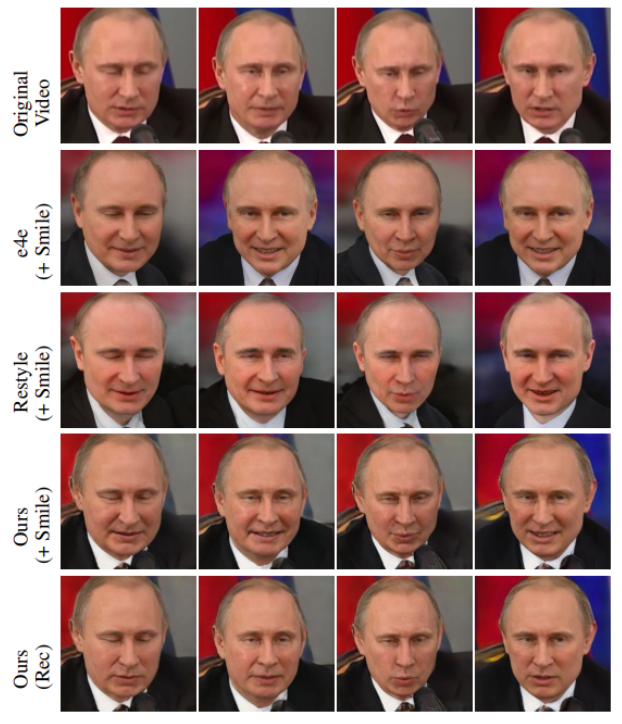
四、更多结果
该方法不仅可以用于图像编辑,也可以用来做视频的编辑,更多结果可以在作者的主页找到:https://tengfei-wang.github.io/HFGI/




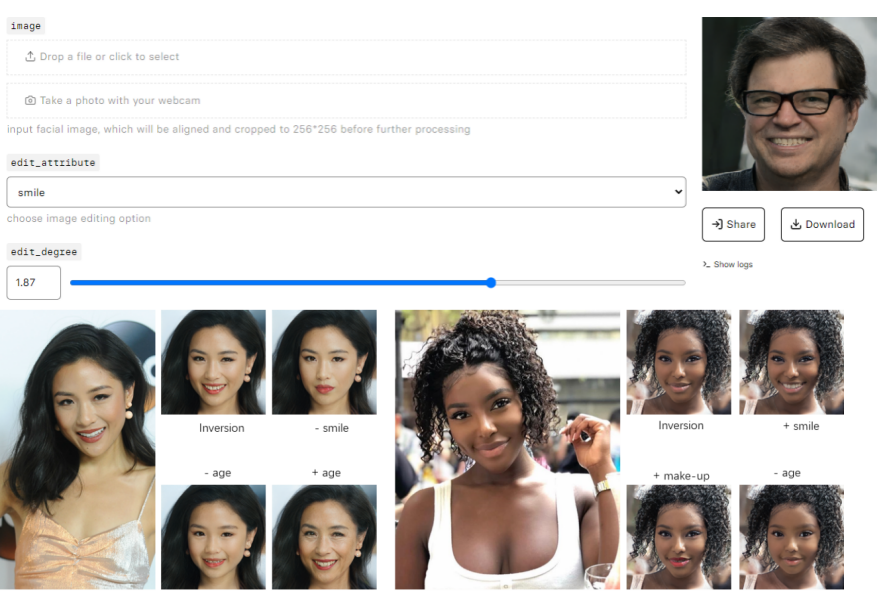
五、在线试玩
这么好玩的方法,想不想用自己或者朋友的照片来体验一下?作者提供了一个online demo,可以自己上传图片或者用摄像头拍照来进行编辑。
在线试玩地址:https://replicate.com/tengfei-wang/hfgi
ICCV和CVPR 2021论文和代码下载
后台回复:CVPR2021,即可下载CVPR 2021论文和代码开源的论文合集
后台回复:ICCV2021,即可下载ICCV 2021论文和代码开源的论文合集
后台回复:Transformer综述,即可下载最新的3篇Transformer综述PDF
CVer-Transformer交流群成立
扫描下方二维码,或者添加微信:CVer6666,即可添加CVer小助手微信,便可申请加入CVer-Transformer 微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer等。
一定要备注:研究方向+地点+学校/公司+昵称(如Transformer+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
▲扫码或加微信: CVer6666,进交流群
CVer学术交流群(知识星球)来了!想要了解最新最快最好的CV/DL/ML论文速递、优质开源项目、学习教程和实战训练等资料,欢迎扫描下方二维码,加入CVer学术交流群,已汇集数千人!
▲扫码进群
▲点击上方卡片,关注CVer公众号
整理不易,请点赞和在看







