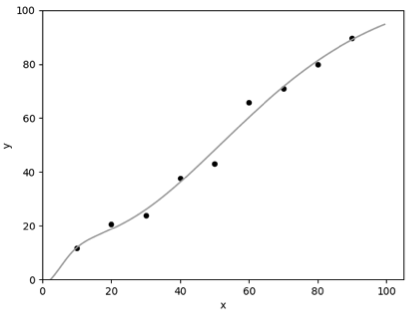
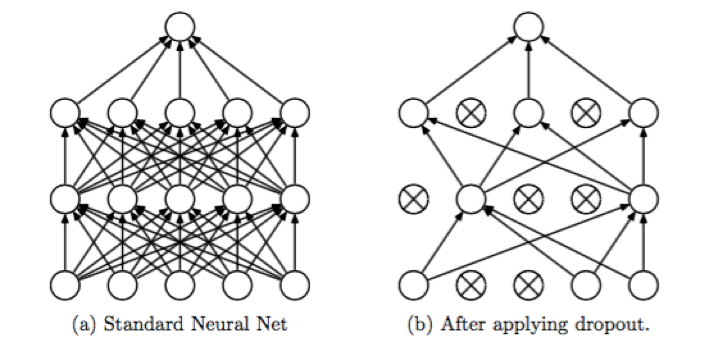
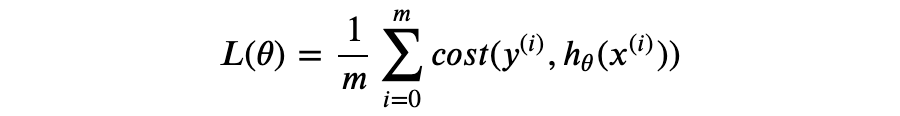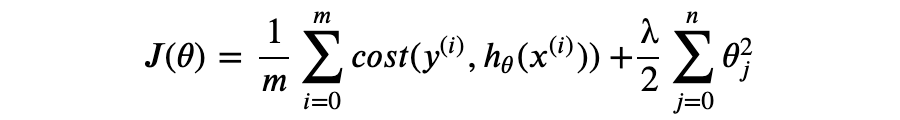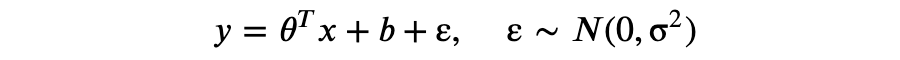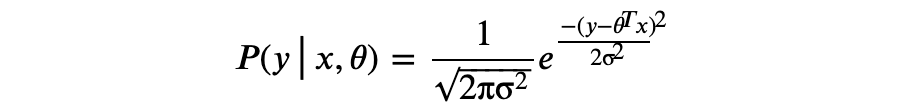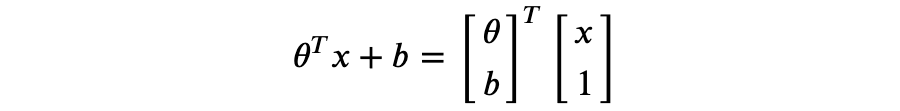现在,测试阶段保留了原有的模型结构,超参数 p 仅作用于训练阶段。通常我们更倾向于后一种实现方式,称为 inverted dropout。 Dropout 最早的论文发表于 2012 年 [Improving neural networks by preventing co-adaptation of feature detectors. G. E. Hinton. University of Toronto. 2012.],随后 2013 年的另一篇论文探讨了 Dropout 与 L2 正则化的联系 [Dropout Training as Adaptive Regularization. Stefan Wager. Stanford University. 2013.],还有 2014 年 Dropout 论文 [Dropout: A Simple Way to Prevent Neural Networks from Overfitting. Nitish Srivastava. University of Toronto. 2014.] 。 本文关于 MLE 和 MAP 的推导部分参考了康奈尔大学的 CS 课程 [Linear Regression. Cornell University. 2018.] 。
参考文献
[1] Improving neural networks by preventing co-adaptation of feature detectors. G. E. Hinton. University of Toronto. 2012. [2] Dropout Training as Adaptive Regularization. Stefan Wager. Stanford University. 2013. [3] Dropout: A Simple Way to Prevent Neural Networks from Overfitting. Nitish Srivastava. University of Toronto. 2014. [4] Linear Regression. Cornell University. 2018. [5] 贝叶斯线性回归. 百度百科. [6] Neural Networks Part 2: Setting up the Data and the Loss. Stanford University. 2020. [7] Regularization for Sparsity: L₁ Regularization. 2020.