模型压缩高达75%,推理速度提升超20%,百度Paddle Lite v2.3正式发布


如今,诸如计算机视觉、智能语音交互等基于深度学习的AI技术,在满足日常应用层面上已经非常成熟。比如,人脸识别闸机在机场、地铁、办公楼、学校等地方随处可见。什么都不用带,只要刷个脸就行,方便快捷又省事!
当有人经过闸机时,可以在0.1-0.3秒内完成人脸实时跟踪,并在0.2秒内完成高安全性的静默活体检测及人脸比对,如此高效的响应速度,你知道是怎么做到的吗?
目前深度学习在各个领域轻松碾压传统算法,不过真正用到实际项目中却面临两大问题:计算量巨大;模型占用很高的内存(深度学习模型可能会高达几百M)。
为了更好地应对这些实际业务需求,解决终端系统资源有限等问题,百度深度学习平台飞桨(PaddlePaddle)对端侧推理引擎Paddle Lite进行了新一轮升级,v2.3版本正式全新上线!
Paddle Lite v2.3新功能包括:
支持“无校准数据的训练后量化”方法,模型压缩高达75%;
优化网络结构和OP,ARM CPU推理速度最高提升超20%;
简化模型优化工具操作流程,支持一键操作,用户上手更容易。
此次升级带来了以下几个方面的变化:
在手机等终端设备上部署深度学习模型,通常要兼顾推理速度和存储空间。一方面要求推理速度越快越好,另一方面要求模型更加的轻量化。为了解决这一问题,模型量化技术尤其关键。
模型量化是指使用较少比特数表示神经网络的权重和激活,能够大大降低模型的体积,解决终端设备存储空间有限的问题,同时加快了模型推理速度。将模型中特定OP权重从FP32类型量化成INT8/16类型,可以大幅减小模型体积。经验证,将权重量化为INT16类型,量化模型的体积降低50%;将权重量化为INT8类型,量化模型的体积降低75%。
Paddle Lite结合飞桨量化压缩工具PaddleSlim,为开发者提供了三种产出量化模型的方法:量化训练、有校准数据的训练后量化和无校准数据的训练后量化。
其中“无校准数据的训练后量化”是本次Paddle Lite新版本重要新增内容之一。
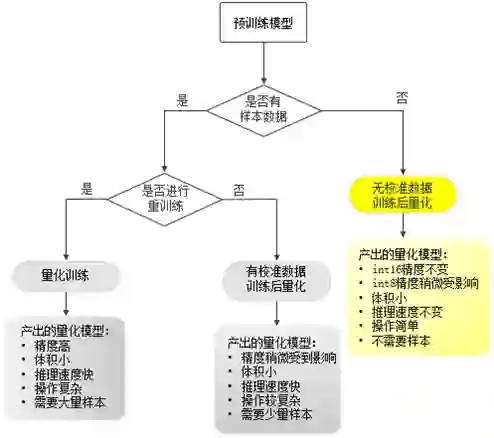
图1三种产出量化模型方法的处理示意图
“无校准数据的训练后量化”方法,在维持精度几乎不变的情况下,不需要样本数据,对于开发者来说使用更简便,应用范围也更广泛。
当然,如果希望同时减小模型体积和加快模型推理速度,开发者可以尝试采用PaddleSlim“有校准数据的训练后量化”方法和“量化训练”方法。
PaddleSlim除了量化功能以外,还集成了模型压缩中常用的剪裁、蒸馏、模型结构搜索、模型硬件搜索等方法。更多详细的介绍,请参见Github:
https://github.com/PaddlePaddle/PaddleSlim
下面以MoblieNetV1、MoblieNetv2和ResNet50模型为例,介绍本方法所获得的效果。
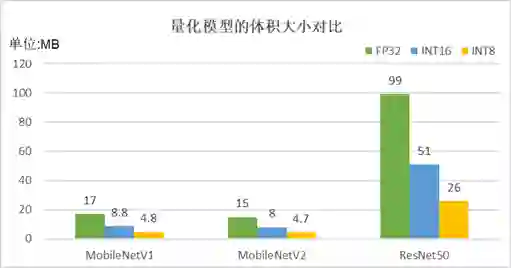
图2 “无校准数据的训练后量化”方法产出的量化模型体积对比图
由图2可知,INT16格式的量化模型,相比FP32,模型体积降低50%;INT8 格式的量化模型,相比FP32,模型体积降低75%。
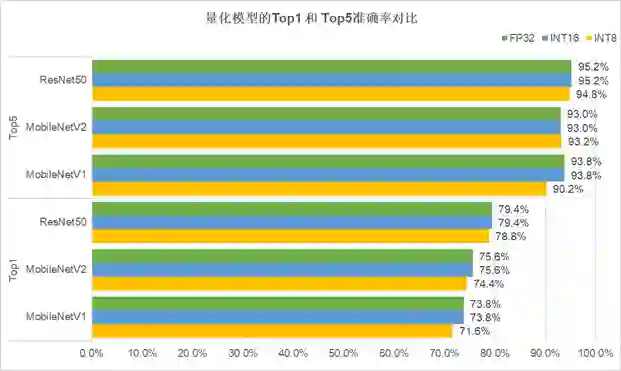
图3 “无校准数据的训练后量化”方法产出的量化模型准确率对比图
由图3可知,INT16格式的量化模型,相比FP32,准确率不变;INT8格式的量化模型,相比FP32,准确率仅微弱降低。
Paddle Lite v2.3在ARM CPU性能优化方面的主要更新包括:
-
针对Kernel Size为3*3的Conv,实现Winograd方法,包括F(6,3)和F(2, 3)。因Winograd相比普通算法从计算量上有大幅减少,该实现可以明显提升有相关OP的模型性能,比如ResNet50和SqueezeNet; -
针对Conv后激活为Relu6 或是LeakyRelu的模型,添加Conv+Relu6/LeakyRelu 融合,从而可以减少单独的激活函数需要的访存耗时; -
针对PaddlePaddle1.6 OP升级,如支持任意Padding的Conv和Pooling,Paddle Lite增加相关支持。该工作使得Tensorflow模型转换时,一个Tensorflow Conv 对应一个Paddle Conv, 而非Padding+Conv 两个OP,从而可以提升Tensorflow模型的推理性能。
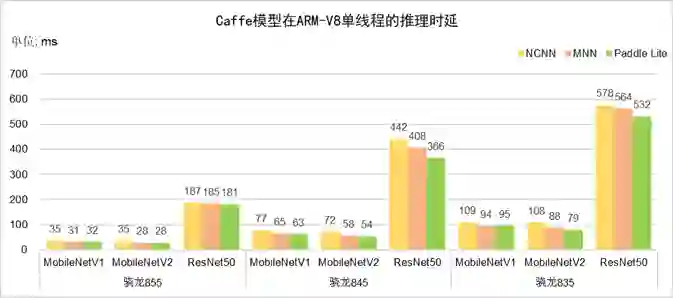 图4 Caffe框架模型的推理时延对比
图4 Caffe框架模型的推理时延对比
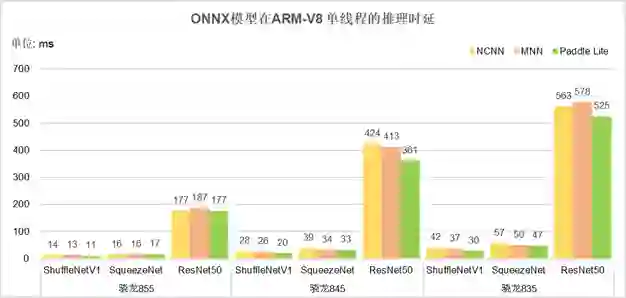
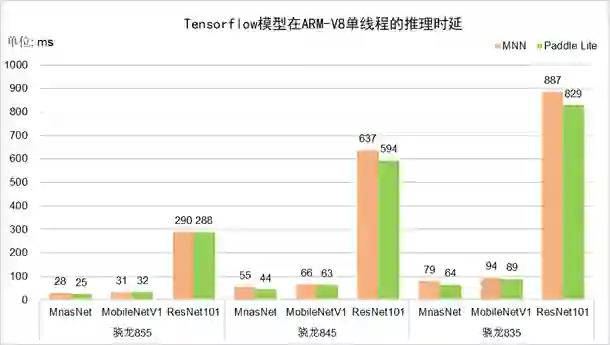
-
提供一键式脚本(auto_transformer.sh),支持一键完成从各类框架模型到Paddle Lite模型(含OP算子融合、内存复用等优化操作)的所有优化处理操作; -
优化后的模型最终只生成一个.nb文件,此文件包含模型网络结构和参数信息。同时提供加载模型.nb文件的API接口:set_model_from_file(nb_path),接口的具体内容请见【Model Load API】。原有的模型加载方式仍然支持; -
提供丰富的日志信息,比如支持查看某个模型用到哪些算子;还支持查看Paddle Lite支持哪些硬件,以及这些硬件分别支持哪些算子(如图7所示),进而了解Paddle Lite对模型的支持情况。
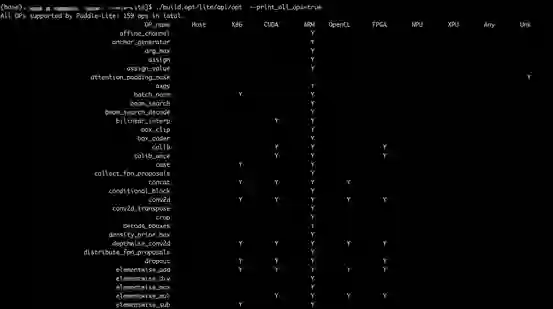


https://github.com/PaddlePaddle/Paddle-Lite
https://paddle-lite.readthedocs.io/zh/latest/index.html
https://github.com/PaddlePaddle/Paddle-Lite-Demo
https://github.com/PaddlePaddle/Paddle-Lite/tree/develop/lite/demo/cxx
https://paddle-lite.readthedocs.io/zh/latest/benchmark/benchmark.html
https://github.com/PaddlePaddle/Paddle-Lite/blob/release/v2.3/lite/tools/auto_transform.sh
https://paddle-lite.readthedocs.io/zh/latest/api_reference/cxx_api_doc.html#set-model-from-file-model-dir
https://paddle-lite.readthedocs.io/zh/latest/user_guides/model_optimize_tool.html
https://github.com/paddlepaddle

🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。



