我从吴恩达深度学习课程中学到的21个心得:加拿大银行首席分析师“学霸“笔记分享

大数据文摘作品
编译:新知之路、小饭盆、钱天培
今年8月,吴恩达的深度学习课程正式上线,并即刻吸引了众多深度学习粉丝的“顶礼膜拜”。一如吴恩达此前在Coursera上的机器学习课程,这几门深度学习课程也是好评如潮。
在诸多粉丝中,加拿大国家银行金融市场的首席分析师Ryan J. Shrott从前三门深度学习课程中总结出了21点心得,总结了该系列课程的诸多精华。
今天,文摘菌就带大家一起来读一读这份“学霸“笔记。
首先来看一下Ryan对该课程的总体评价:
吴恩达先生(Andrew Ng)的3门课程都超级有用,教会了我许多实用的知识。吴教授擅长过滤掉流行词汇,用一种清晰简洁的方式解释了一切。比如他阐明了监督式深度学习(supervised deep learning)只不过是一个多维的曲线拟合程序,而其他任何具有代表性的理解,如人类神经系统的通用参照,则有些太过玄乎了。
官方介绍说只需要有一些基本的线性代数和Python编程知识就可以听懂这些课程。然而我认为你还应该懂得矢量微积分(vector calculus),有助于懂得优化过程的内部机理。如果你不关心内部如何运行,只是关注获取更高层面的信息,你可以跳过那些微积分的视频。
下面,就是Ryan在学习完该系列课程后的心得。
心得1:为什么深度学习得以迅速发展
我们人类当今拥有的90%的数据都是于最近2年内收集的。深度神经网络(DNN’s)可以更好地利用大规模的数据,从而超越较小的网络及传统学习算法。
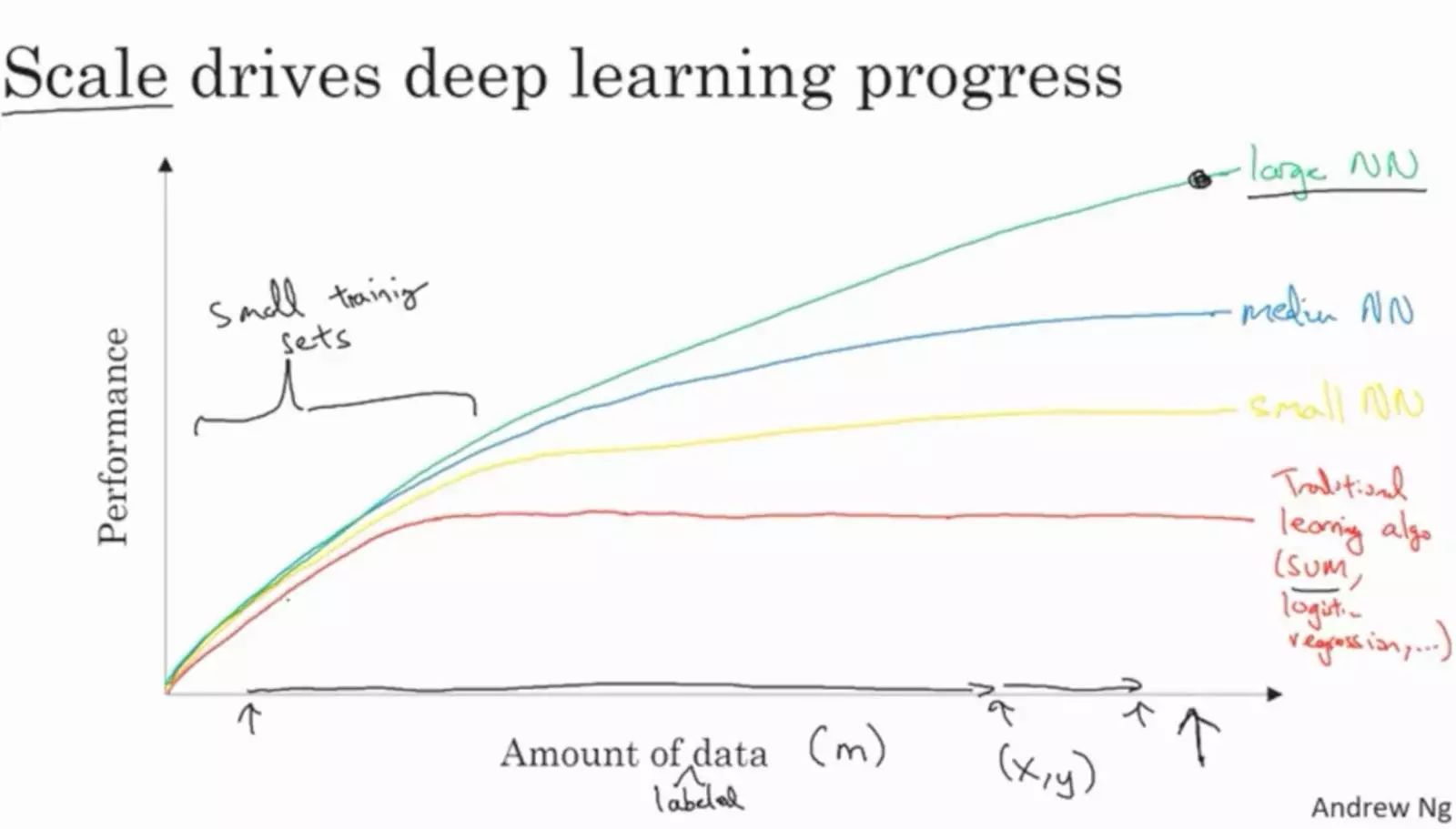
此外,还有好多算法方面的革新使DNN‘s的训练变得非常快。比如将Sigmoid激活函数转换成ReLU激活函数已经对梯度下降等优化过程产生了巨大的影响。这些算法的优化使得研究者们的“创意-编码-验证”循环迭代速度越来越快,从而引导了更多的创新。
心得2:深度学习内的矢量化(vectorization)
在上这门课之前,我从没有意识到一个神经网络可以不用for循环来搭建。吴恩达很好地传达了矢量化代码设计的重要性。在作业中,他还提供了一个标准化的矢量代码设计样本,这样你就可以很方便的应用到自己的应用中了。
心得3:DNN的深层理解
在第一个课程中,我学会了用NumPy库实现前向和反向传播过程,我因而对诸如TensorFlow和Keras这些高级别框架的内部工作机理产生了更深层次的理解。吴恩达通过解释计算图(comptation graph)背后的原理,让我懂得TensorFlow是如何执行“神奇的优化”的。
心得4:为什么需要深度表征(Deep Representations)
吴恩达对DNN‘s的分层方面有着直观的理解。比如,在面部识别方面,他认为先前的分层用于将脸部边缘分组,后续的分层将这些分好的组形成五官(如鼻子、眼睛、嘴等等),再接下来的分层把这些器官组合在一起用以识别人像。他还解释了回路理论(circuit theory),即存在一些函数,需要隐藏单元的指数去匹配浅层网络的数据。可以通过添加有限数量的附加层来简化这个指数问题。
心得5:处理偏差(bias)和方差(variance)的工具
吴教授解释了识别和修缮偏差和方差相关问题的步骤。下图显示了解决这些问题系统性的方法。

机器学习的基本“秘诀” 解决偏差和方差的“秘诀”
他还解决了偏差和方差之间被普遍引用的“权衡”(tradeoff)问题。他认为在深度学习的时代,我们拥有独立解决每个问题的能力,所以这种“权衡”问题将不再存在。
心得6:正则化的直观解释
为什么向成本函数中加入一个惩罚项会降低方差效应?在上这门课之前我对它的直觉是它使权重矩阵接近于零,从而产生一个更加“线性”的函数。吴教授则给出了另一个关于tanh激活函数的解释。他认为更小的权重矩阵产生更小的输出,这些输出集中围绕在tanh函数的线性区域。
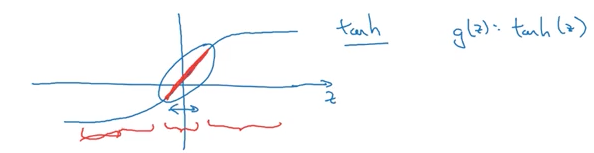
tanh激活函数
他还为dropout给出了一个直观的解释。之前我认为dropout仅仅在每个迭代中消灭随机神经元,就好比一个越小的网络,其线性程度就越强一样。而他的观点是从单个神经元的角度来看这一做法。
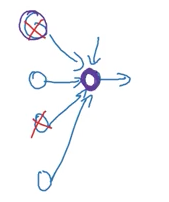
单个神经元的角度
因为dropout随即消灭连接,使得神经元向父系神经元中更加均匀地扩散权重。以至于更倾向于缩减权重的L2范数(squared norm)的效果。他还解释了dropout只不过是L2正则化的一种自适应形式,而这两种的效果类似。
心得7: 为什么归一化(normalization)有效?
吴恩达展示了为什么归一化可以通过绘制等高线图(contour plots)的方式加速优化步骤。他详细讲解了一个案例,在归一化和非归一化等高线图上梯度下降样本进行迭代。
心得8: 初始化的重要性
吴恩达展示了不好的参数初始化将导致梯度消失或爆炸。他认为解决这个问题的基本原则是确保每一层的权重矩阵的方差都近似为1。他还讨论了tanh激活函数的Xavier初始化方法。
心得9: 为什么使用小批量(mini-batch)梯度下降?
吴教授使用等高线图解释了减小和增加小批量尺寸的权衡。基本原则是较大的尺寸每次迭代会变慢,而较小的尺寸则可以加快迭代过程,但是无法保证同样的收敛效果。最佳方法就是在二者之间进行权衡,使得训练过程比立即处理整个数据集要快,又能利用向量化技术的优势。
心得10: 高级优化技术的直观理解
吴恩达解释了动量(momentum)和RMSprop等技术是如何限制梯度下降逼近极小值的路径。他还用球滚下山的例子生动地解释了这一过程。他把这些方法结合起来以解释著名的Adam优化过程。
心得11: 基本TensorFlow后端进程的理解
吴恩达解释了如何使用TensorFlow实现神经网络,并阐明了在优化过程中使用的后端进程。课程作业之一就是鼓励你用TensorFlow来实现dropout和L2正则化,加强了我对后端进程的理解。
心得12: 正交化
吴恩达讨论了机器学习策略中正交化的重要性。基本思想是执行一些控件,这些控件一次只作用于算法性能的单一组件。例如为了解决偏差问题,你可以使用更大的网络或更多的鲁棒优化技术。你希望这些控件只影响偏差而不会影响其他如较差泛化等问题。一个缺少正交化的控件过早停止了优化过程。因为这会同时影响模型的偏差和方差。
心得13:建立单一数字评估指标的重要性
吴恩达强调选择单一数字评估指标来评估算法的重要性。在模型开发过程中,如果你的目标改变,那么随后才可以更改评估度量标准。 Ng给出了在猫分类应用程序中识别色情照片的例子!
心得14:测试集/开发集的分布情况
始终确保开发集和测试集具有相同的分布。这可确保你的团队在迭代过程中瞄准正确的目标。这也意味着,如果你决定纠正测试集中错误标记的数据,那么你还必须纠正开发集中错误标记的数据。
心得15:处理训练集和测试集/开发集处于不同分布的情况
吴恩达给出了为什么一个团队会对具有不同分布的训练集和测试集/开发集感兴趣的原因。原因在于,你希望评估标准是根据你真正关心的例子计算出来的。例如,你也许想使用与你的问题不相关的示例作为训练集,但是,你别指望使用这些示例对你的算法进行评估。你可以使用更多的数据训练你的算法。经验证明,这种方法在很多情况下会给你带来更好的性能。缺点是你的训练集和测试集/开发集有着不同的分布。解决方案是留出一小部分训练集,来单独确定训练集的泛化能力。然后,你可以将此错误率与实际的开发集错误率进行比较,并计算出“数据不匹配”度量标准。吴恩达随后解释了解决这个数据不匹配问题的方法,如人工数据合成。
心得16:训练集/开发集/测试集的大小
在深度学习时代,建立训练集/开发集/测试集划分的参考标准发生了巨大的变化。在上课之前,我知道通常的60/20/20划分。 Ng强调,对于一个非常大的数据集,你应该使用大约98/1/1甚至99 / 0.5 / 0.5的划分。这是因为开发集和测试集只需足够大,以确保你的团队提供的置信区间即可。如果你正在使用10,000,000个训练集示例,那么也许有100,000个示例(或1%的数据)已经很大了,足以确保在你的开发集和/或测试集具有某些置信界限。
心得17:逼近贝叶斯最优误差
吴恩达解释了在某些应用中,人类水平的表现如何被用作贝叶斯误差的代表。例如,对于诸如视觉和音频识别的任务,人的水平误差将非常接近贝叶斯误差。这可以让你的团队量化你的模型中可以避免的偏差。没有贝叶斯误差等基准,将很难理解网络中的方差和可避免的偏差问题。
心得18:错误分析
吴恩达展示了一个效果比较明显的技术,即通过使用错误分析,来显著提高算法性能的有效性。基本思想是手动标记错误分类的示例,并将精力集中在对错误分类数据贡献最大的错误上。
识别猫的应用程序错误分析
例如,在识别猫的应用中,吴恩达判定模糊图像对错误贡献最大。这个灵敏度分析可以让你看到,在减少总的错误方面,你的努力是值得的。通常可能是这样的情况,修复模糊图像是一个非常艰巨的任务,而其他错误是明显的,且容易解决。因此敏感性和模糊工作都将被纳入决策过程。
心得19:何时使用迁移学习?
迁移学习允许你将知识从一个模型迁移到另一个模型。例如,你可以将图像识别知识从识别猫的应用程序迁移到放射诊断。实现迁移学习涉及到用更多的数据重新训练用于类似应用领域的最后几层网络。这个想法是,网络中较早的隐单元具有更广泛的应用,通常不是专门针对你正在使用的网络中的特定任务。总而言之,当两项任务具有相同的输入特征时,而且当你尝试学习的任务比你正在尝试训练的任务有更多的数据时,迁移学习是有效的。
心得20:何时使用多任务学习?
多任务学习迫使一个单一的神经网络同时学习多个任务(而不是每个任务都有一个单独的神经网络)。Ng解释说,如果一组任务可以从共享较低级别的特征中受益,并且每个任务的数据量在数量级上相似,则该方法可以很好地工作。
心得21:何时使用端到端的深度学习?
端到端的深度学习需要多个处理阶段,并将其组合成一个单一的神经网络。这使得数据能够自己说话,而不会存在人们在优化过程中手动显示工程步骤出现的偏差。相反,这种方法需要更多的数据,可能会排除可能手动设计的组件。
总结
Ryan总结道,虽然吴恩达的深度学习课程不能让你成为真正的深度学习专家,但可以让你对深度学习模型的发展过程有了基本的直觉了解。当然,这21点心得也远远不能涵盖该系列课程的全部信息,要想入门深度学习,还是的自己亲自学习这系列课程。
那么,学霸对这门课程有什么负面评价么?
没错,也还是有的。Ryan认为,这门课的作业实在太过简单——并顺手收过了文摘菌的膝盖。
课程推荐
使用keras快速构造深度学习模型实战
优惠倒计时2天
微软&谷歌数据科学家,带你每周案例实战
史上最高性价比!
两位顶尖的微软/谷歌数据科学家,直播互动分享珍贵学习经验,并详细讲解前沿实战案例!GPU云实验平台提供便捷的操作环境。还有原著大作免费送!
七周时间,带你玩转Keras!
很多即将毕业和渴望转型的小伙伴都加入了我们,你不来吗?

志愿者介绍
回复“志愿者”加入我们



往期精彩文章
点击图片阅读
Keras作者François Chollet:一位“网红”科学家的自我修养