[CVPR2020-Oral-FAIR-UIUC]使用原力,卢克!学习通过模拟效应来预测物理力

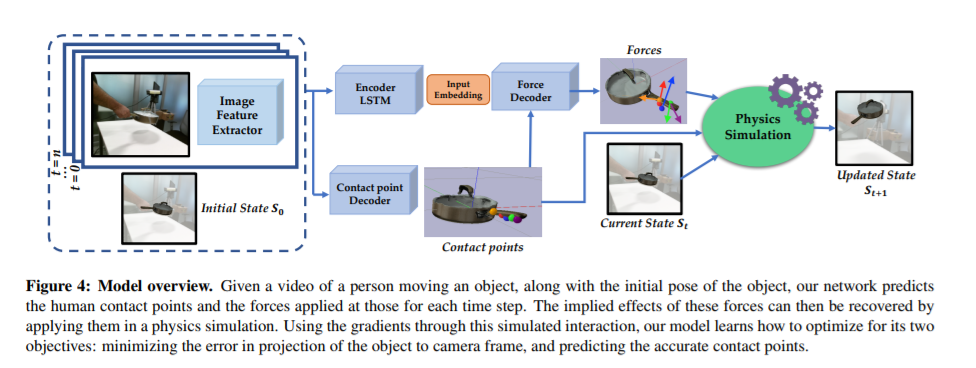
当我们人类观看人机交互的视频时,我们不仅可以推断出发生了什么,我们甚至可以提取可操作的信息并模仿这些交互。另一方面,当前的识别或几何方法缺乏动作表征的物质性。在这篇论文中,我们朝着对行为的物理理解迈出了一步。我们解决了从人类与物体互动的视频中推断接触点和物理力的问题。解决这一问题的主要挑战之一是为物理力取得真实标签。我们通过使用物理模拟器来进行监督,从而避免了这个问题。具体来说,我们使用一个模拟器来预测效果,并执行估计的力必须导致与视频中描述的相同的效果。我们定量和定性结果表明,(a)我们可以从视频中预测有意义的力,这能够导致对观察动作的准确模仿,(b)通过为接触点和力预测联合优化,我们可以在所有任务提高性能相比,和(c)我们可以从这个模型学习一个表示,泛化到使用小样本的物体上。
https://www.zhuanzhi.ai/paper/fb476420913c6ceb3585e71535c14c89
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“PFSE” 就可以获取《[CVPR2020-Oral-FAIR-UIUC]使用原力,卢克!学习通过模拟效应来预测物理力》专知下载链接



登录查看更多
相关内容
专知会员服务
39+阅读 · 2020年3月19日
专知会员服务
13+阅读 · 2019年10月31日
Arxiv
8+阅读 · 2018年2月21日




相关VIP内容
专知会员服务
39+阅读 · 2020年3月19日
专知会员服务
13+阅读 · 2019年10月31日
相关资讯
相关论文
Arxiv
8+阅读 · 2018年2月21日