【斯坦福马腾宇】理解预训练的三个方面:自监督丢失、归纳偏差和内隐偏差

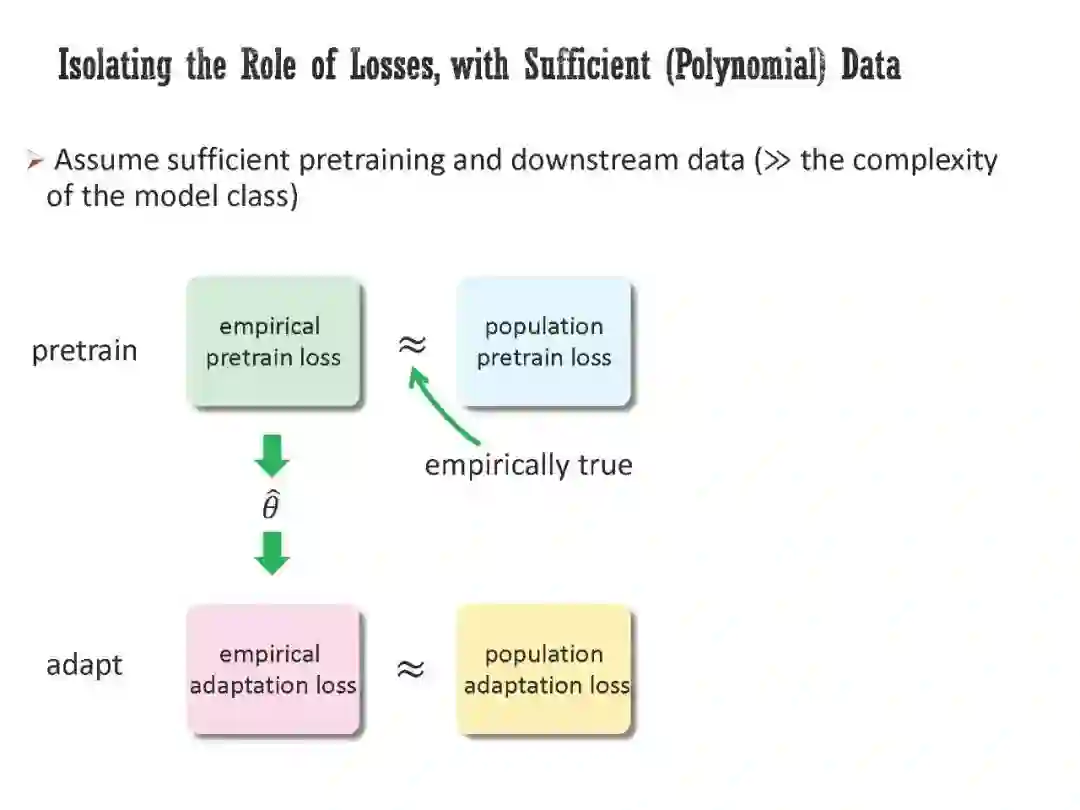
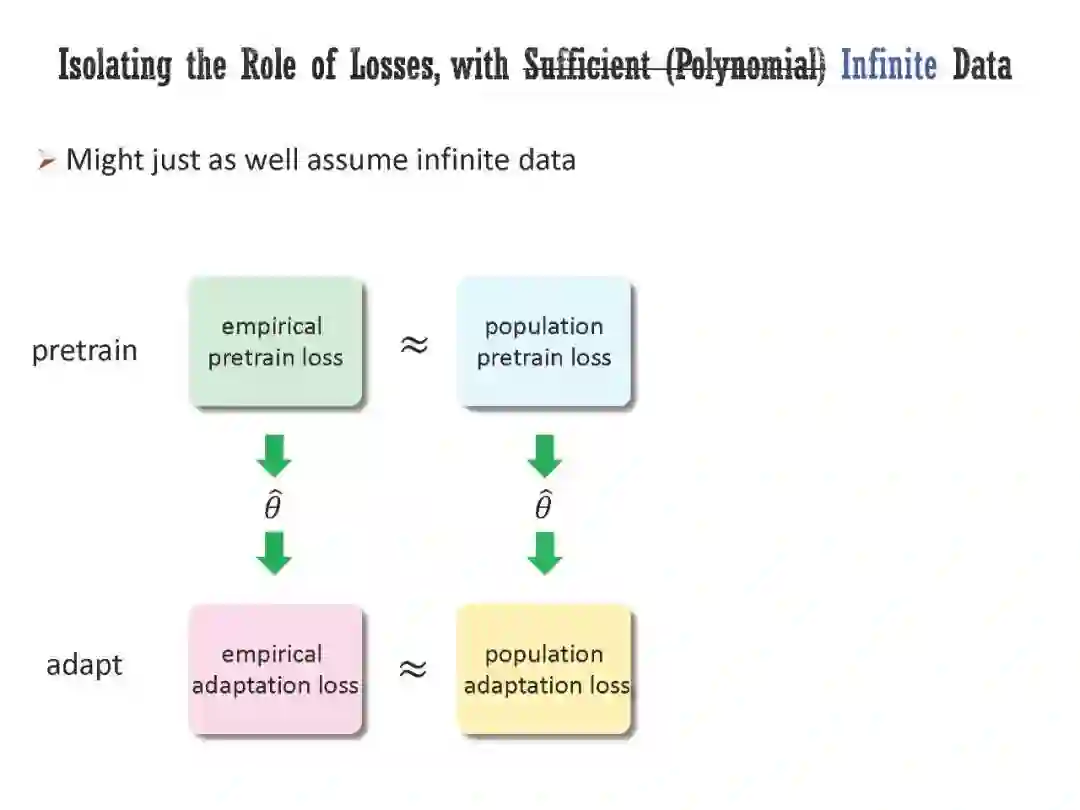
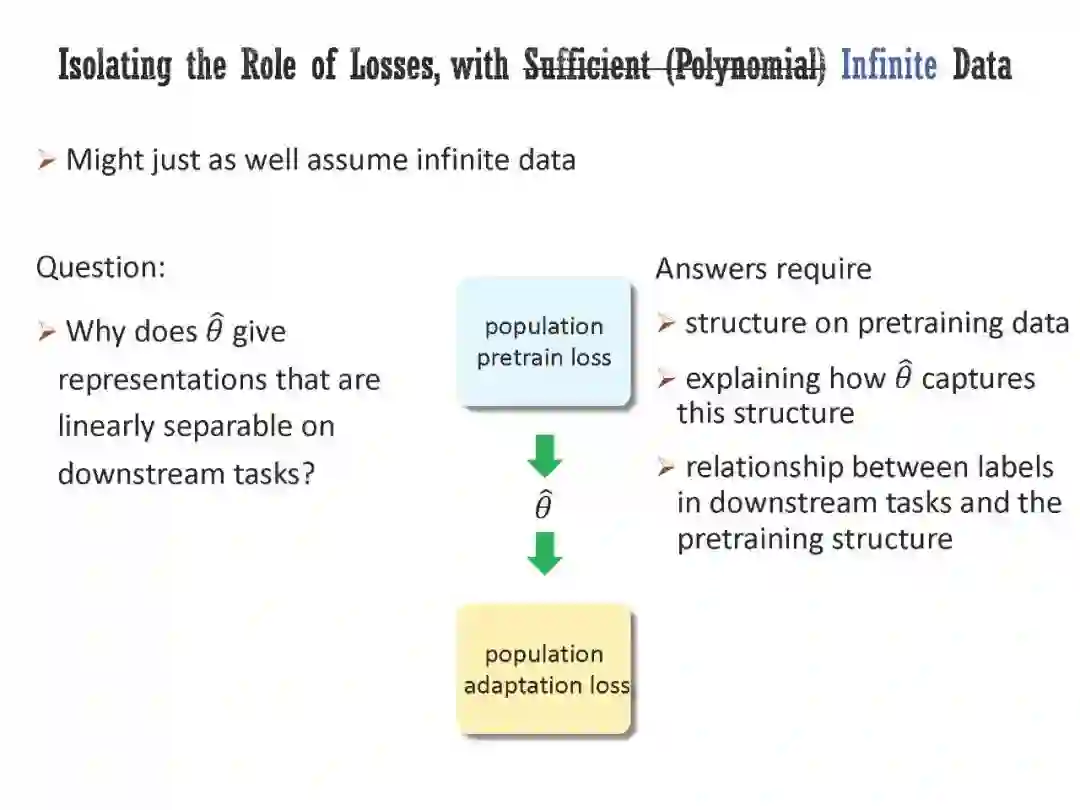
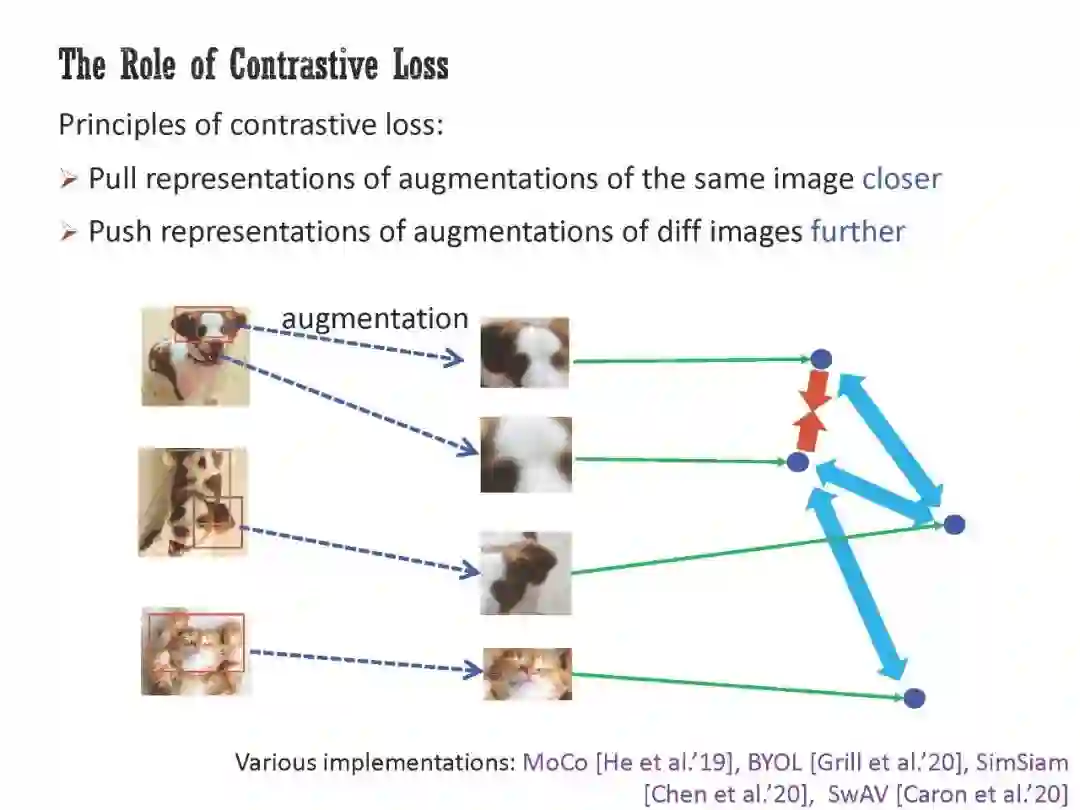
工智能正在经历范式转变,一些经过自监督预训练、然后适应广泛下游任务的模型正在兴起。然而,它们的工作原理在很大程度上仍然是个谜;经典的学习理论无法解释为什么对无监督任务的预训练可以帮助许多不同的下游任务。本次演讲将首先研究预训练损失在从未标记数据中提取有意义的结构信息方面的作用,特别是在无限数据状态下。具体来说,我将展示对比损失可能产生的嵌入,其欧氏距离捕获了原始数据之间的流形距离(或者更一般地说,所谓的正对图的图距离)。此外,嵌入空间中的方向对应于正对图中簇之间的关系。然后,我将讨论对实际预训练模型的行为进行清晰解释所必需的另外两个元素:体系结构的归纳偏差和优化器的隐式偏差。我将介绍两个最近正在进行的项目,其中我们(1)通过纳入体系结构的归纳偏差来加强之前的理论框架,(2)从经验和理论上证明优化器在预训练中的隐式偏差,即使使用无限的预训练数据。

马腾宇,2012届姚班校友,于普林斯顿大学获得博士学位,现为斯坦福大学计算机科学与统计学的助理教授。研究兴趣包括机器学习和深度学习,深度强化学习和高维统计。曾获得NIPS'16最佳学生论文奖,COLT'18最佳论文奖、ACM博士论文奖荣誉奖和2021斯隆研究奖。




专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“TFUP” 就可以获取《【斯坦福马腾宇】理解预训练的三个方面:自监督丢失、归纳偏差和内隐偏差》专知下载链接



登录查看更多
相关内容

Arxiv
0+阅读 · 2022年12月27日


相关VIP内容
相关资讯